Lesson 3: Introduction to Simple Linear Regression (SLR)
2026-01-12
Process of regression data analysis

![]()
![]()
Model Selection
Building a model
Selecting variables
Prediction vs interpretation
Comparing potential models
Model Fitting
Find best fit line
Using OLS in this class
Parameter estimation
Categorical covariates
Interactions
Model Evaluation
- Evaluation of model fit
- Testing model assumptions
- Residuals
- Transformations
- Influential points
- Multicollinearity
Model Use (Inference)
- Inference for coefficients
- Hypothesis testing for coefficients
- Inference for expected \(Y\) given \(X\)
- Prediction of new \(Y\) given \(X\)
Let’s start with an example
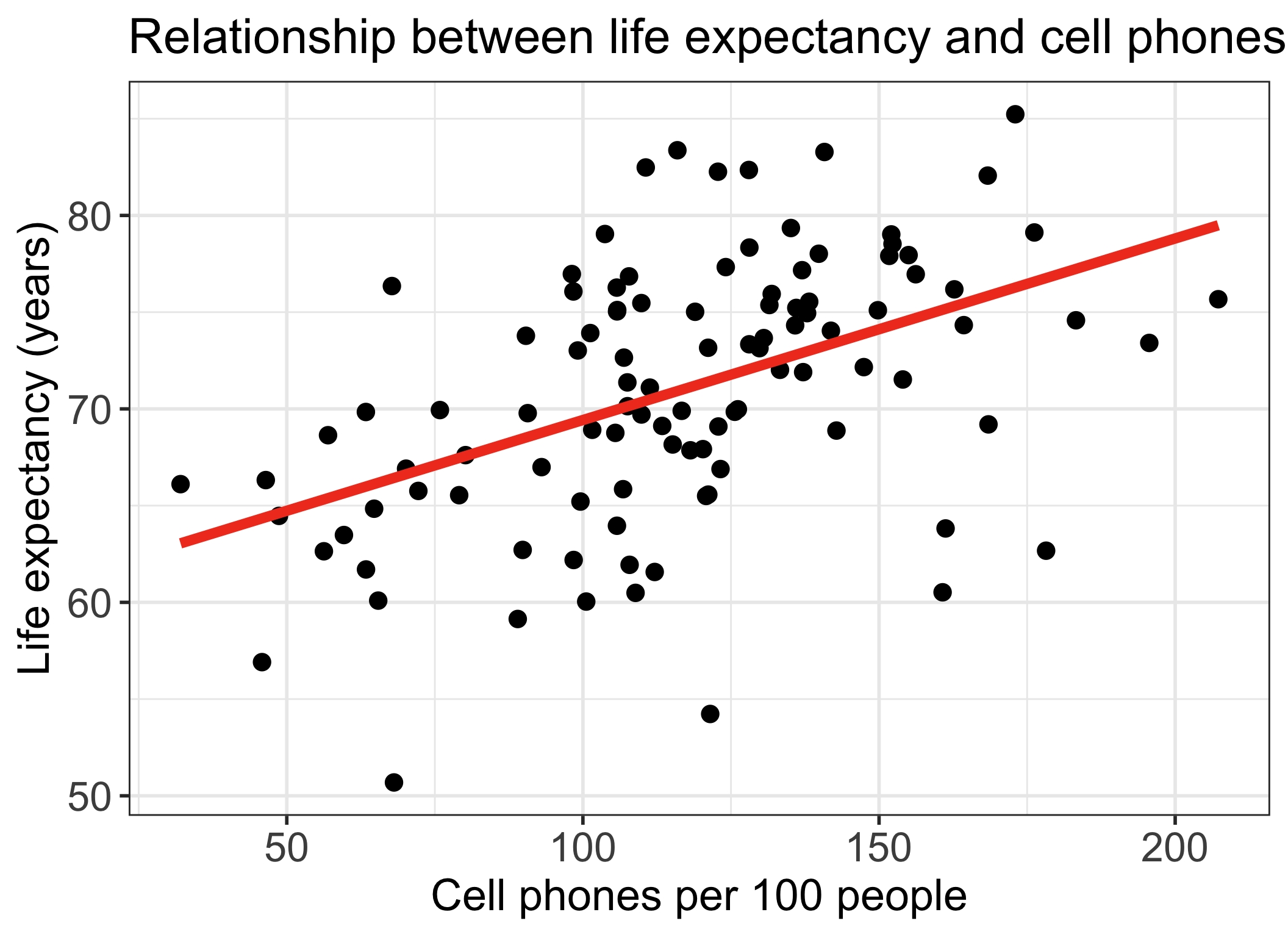
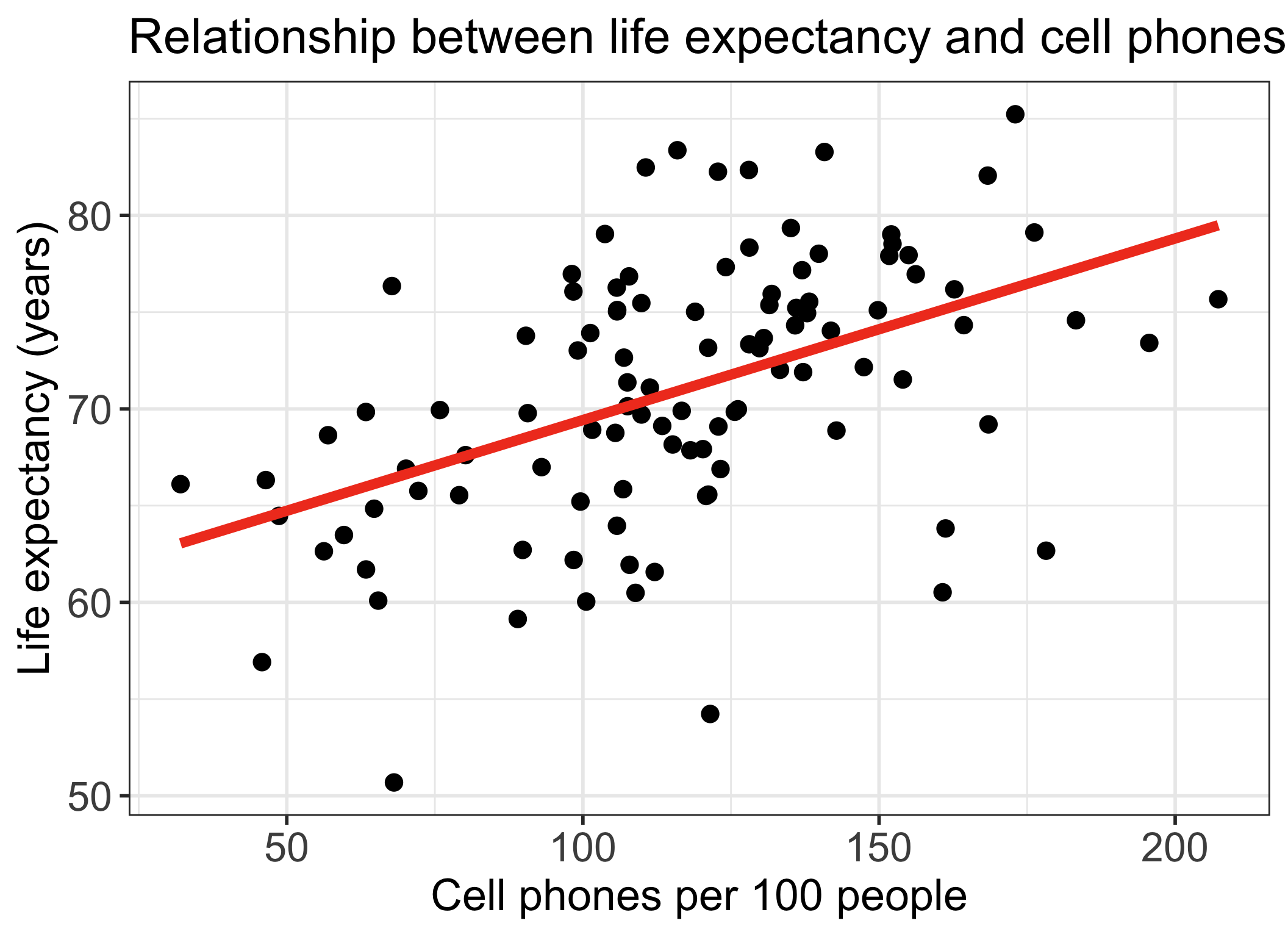
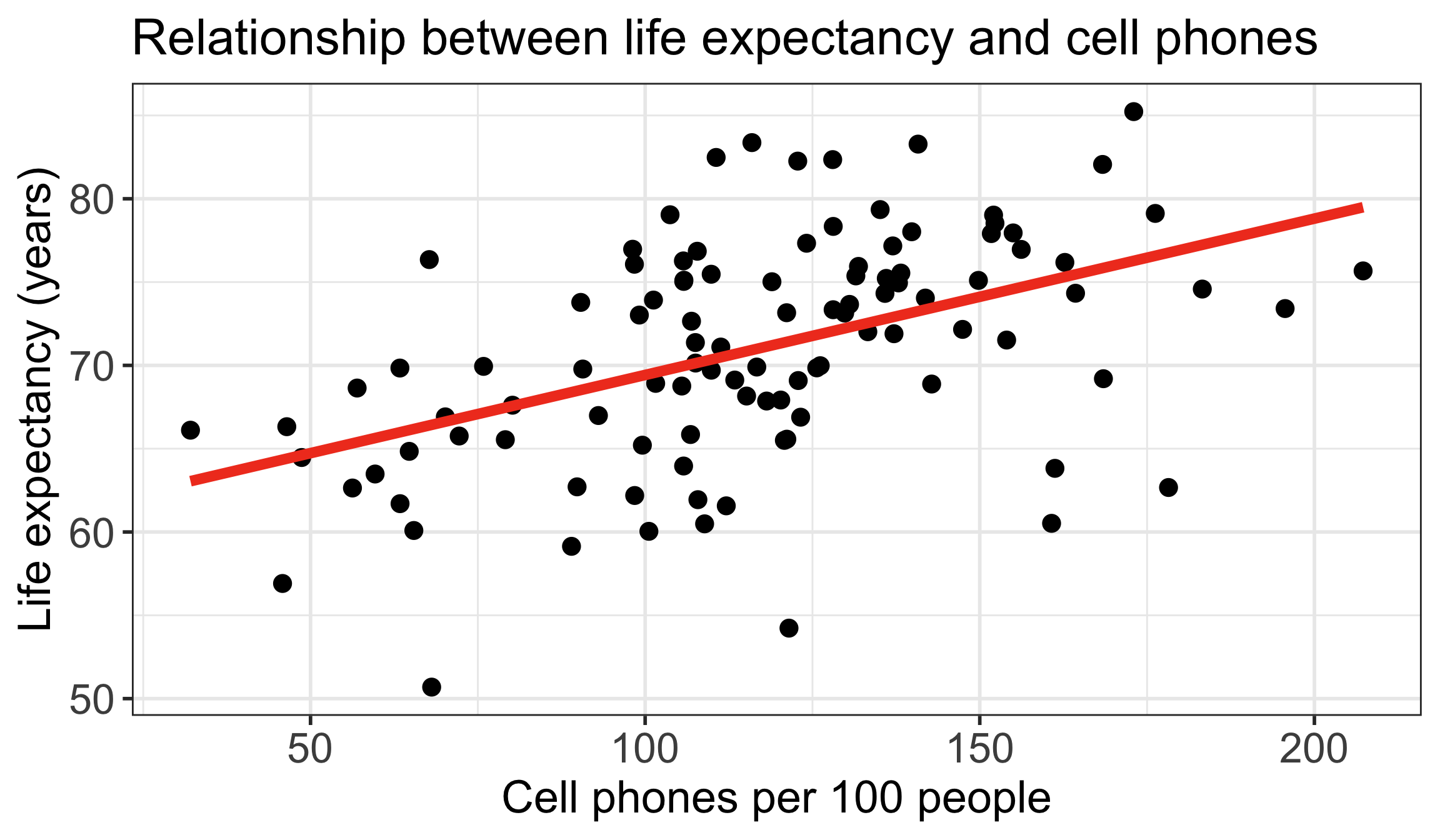
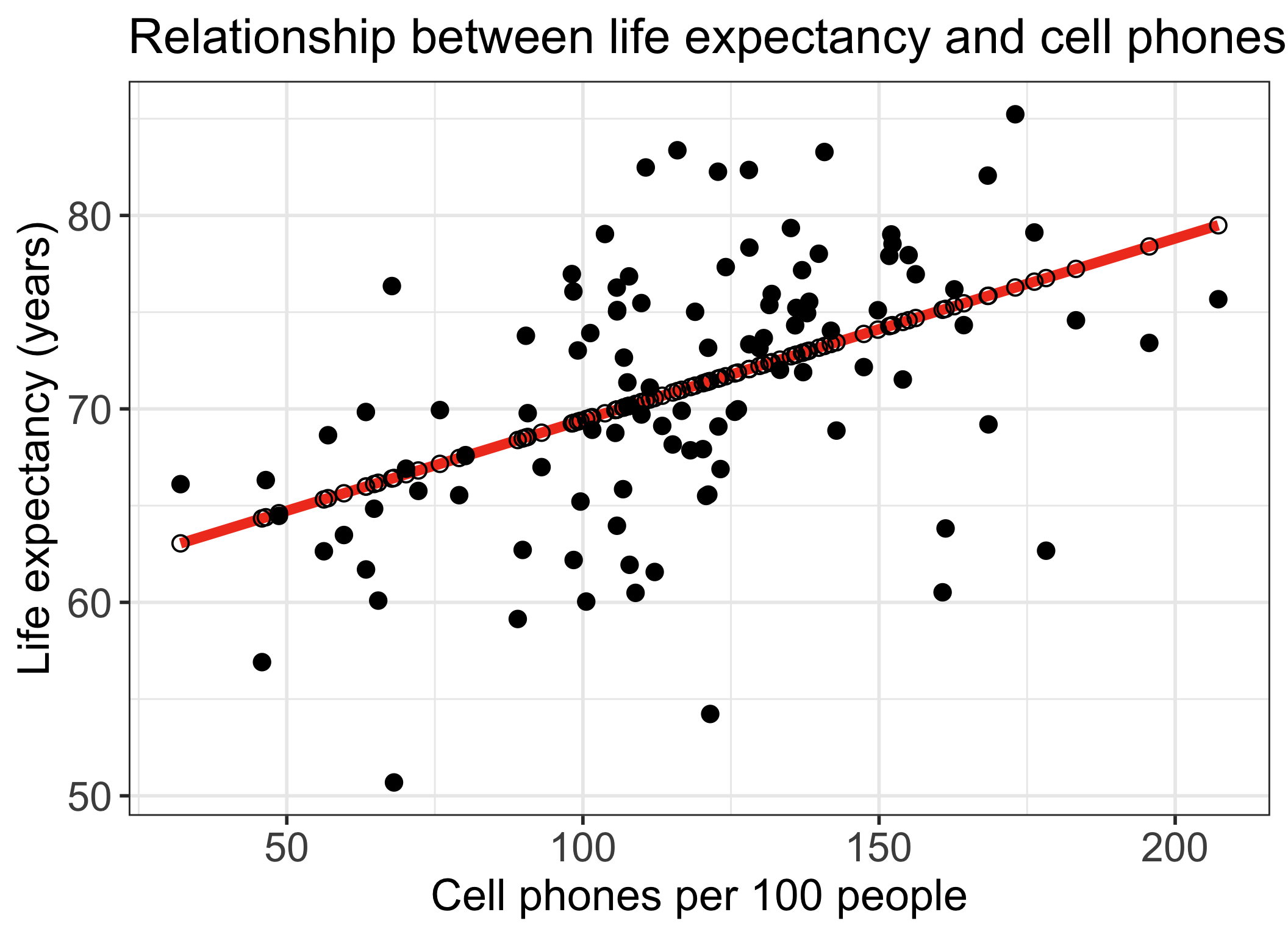
Life expectancy vs. cell phones
- Each point on the plot is for a different country/territory
- \(X\) = country’s number of cell phones per 100 people
- \(Y\) = country’s life expectancy (years)
\[\widehat{\text{life expectancy}} = 60.04 + 0.094\cdot\text{cell phones}\]
Reference: How did I code that?

gapm %>%
ggplot(aes(x = cell_phones_100,
y = life_exp)) +
geom_point(size = 4) +
geom_smooth(method = "lm", se = FALSE, size = 3, colour="#F14124") +
labs(x = "Cell phones per 100 people",
y = "Life expectancy (years)",
title = "Relationship between life expectancy and cell phones") +
theme(axis.title = element_text(size = 27),
axis.text = element_text(size = 25),
title = element_text(size = 25))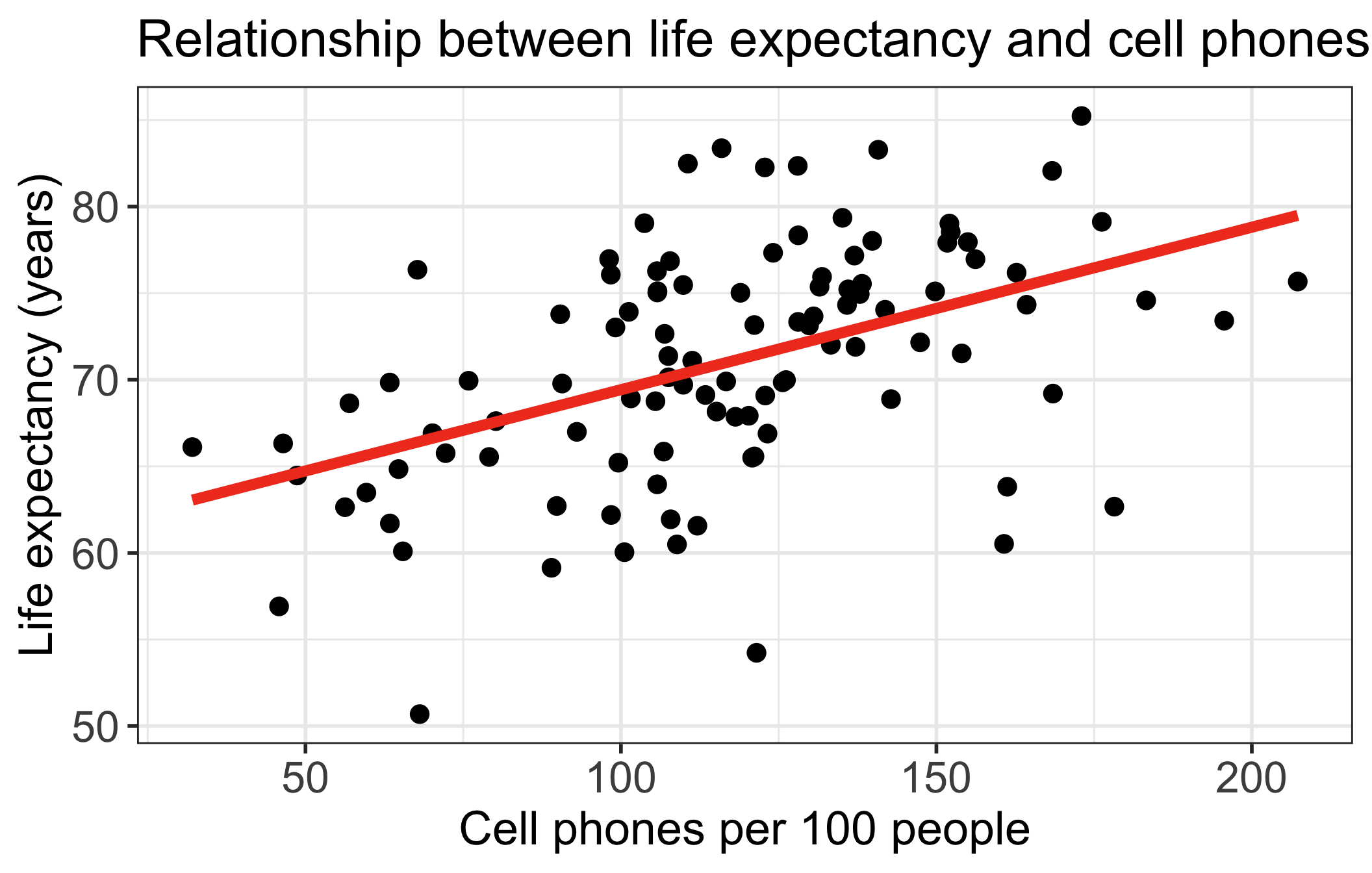
Get to know the data (3/3)
- Get a sense of the summary statistics
- Plot the individual variables
Code
cell_phone_hist = gapm %>%
ggplot(aes(x = cell_phones_100)) +
geom_histogram() +
labs(x = "Cell phones per 100 people",
y = "Number of territories",
title = "Distribution of cell phones per 100 people") +
theme(axis.title = element_text(size = 20),
axis.text = element_text(size = 18),
title = element_text(size = 20))
life_exp_hist = gapm %>%
ggplot(aes(x = life_exp)) +
geom_histogram() +
labs(x = "Life expectancy (years)",
y = "Number of territories",
title = "Distribution of life expectancy") +
theme(axis.title = element_text(size = 20),
axis.text = element_text(size = 18),
title = element_text(size = 20))
grid.arrange(cell_phone_hist, life_exp_hist, nrow=2)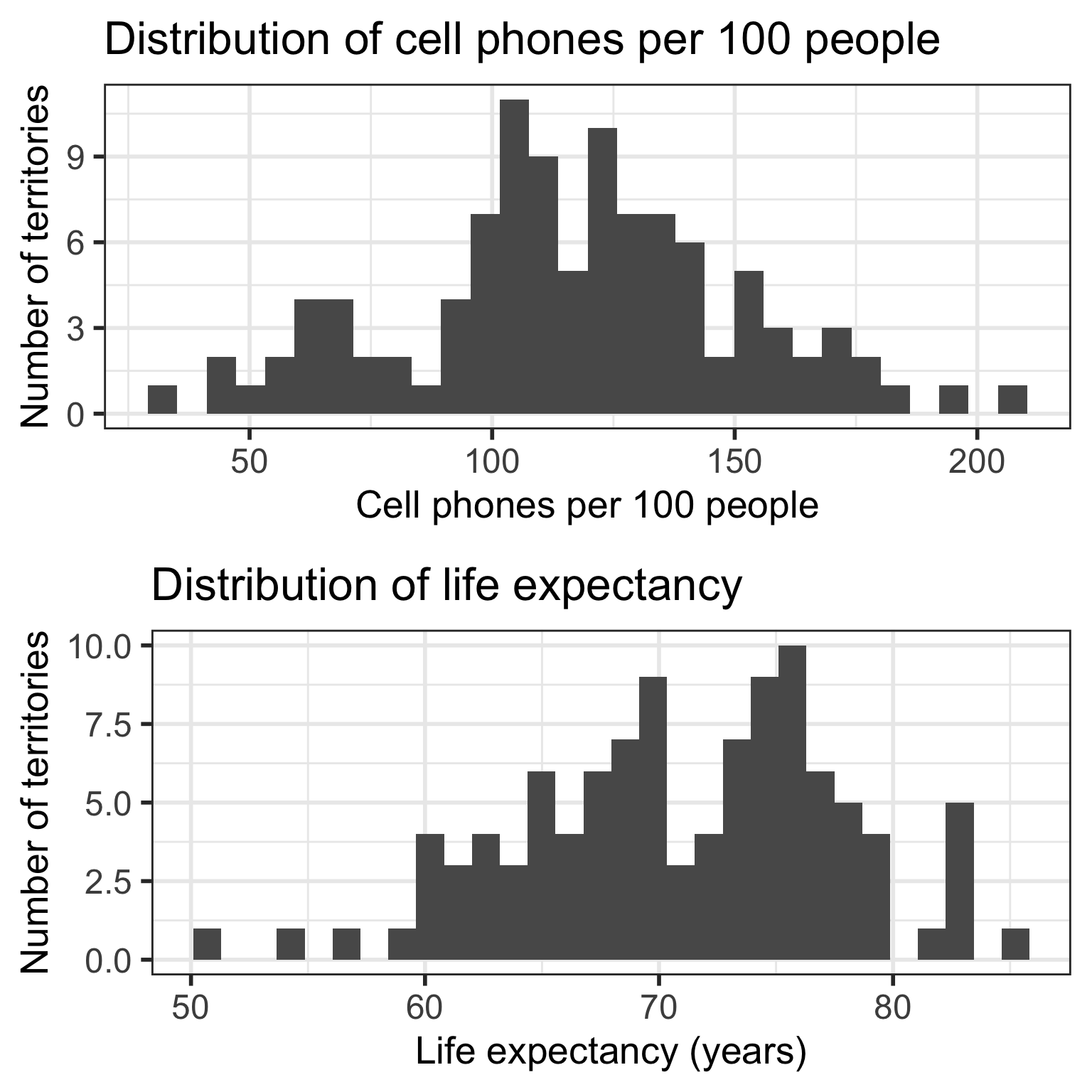
Questions we can ask with a simple linear regression model
- How do we…
- calculate slope & intercept?
- interpret slope & intercept?
- do inference for slope & intercept?
- CI, p-value
- do prediction with regression line?
- CI for prediction?
- Does the model fit the data well?
- Should we be using a line to model the data?
- Should we add additional variables to the model?
- multiple/multivariable regression
\[\widehat{\text{life expectancy}} = 60.04 + 0.094\cdot\text{cell phones}\]
Association vs. prediction
Association
- What is the association between countries’ life expectancy and cell phones?
- Use the slope of the line or correlation coefficient
Prediction
- What is the expected life expectancy for a country with a specified number of cell phones per 100 people?
\[\widehat{\text{life expectancy}} = 60.04 + 0.094\cdot\text{cell phones}\]
Let’s revisit the regression analysis process
![]()
![]()
Model Selection
Building a model
Selecting variables
Prediction vs interpretation
Comparing potential models
Model Fitting
Find best fit line
Using OLS in this class
Parameter estimation
Categorical covariates
Interactions
Model Evaluation
- Evaluation of model fit
- Testing model assumptions
- Residuals
- Transformations
- Influential points
- Multicollinearity
Model Use (Inference)
- Inference for coefficients
- Hypothesis testing for coefficients
- Inference for expected \(Y\) given \(X\)
- Prediction of new \(Y\) given \(X\)
If the population parameters are unobservable, how did we get the line for life expectancy?
Note: the population model is the true, underlying model that we are trying to estimate using our sample data
- Our goal in simple linear regression is to estimate \(\beta_0\) and \(\beta_1\)
Regression line = best-fit line
\[\widehat{Y} = \widehat{\beta}_0 + \widehat{\beta}_1 X \]
- \(\widehat{Y}\) is the predicted outcome for a specific value of \(X\)
- \(\widehat{\beta}_0\) is the intercept of the best-fit line
- \(\widehat{\beta}_1\) is the slope of the best-fit line, i.e., the increase in \(\widehat{Y}\) for every increase of one (unit increase) in \(X\)
- slope = rise over run
It all starts with a residual…
Recall, one characteristic of our population model was that the residuals, \(\epsilon\), were Normally distributed: \(\epsilon \sim N(0, \sigma^2)\)
In our population regression model, we had: \[Y = \beta_0 + \beta_1X + \epsilon\]
We can also take the average (expected) value of the population model
We take the expected value of both sides and get:
\[\begin{aligned} E[Y] & = E[\beta_0 + \beta_1X + \epsilon] \\ E[Y] & = E[\beta_0] + E[\beta_1X] + E[\epsilon] \\ E[Y] & = \beta_0 + \beta_1X + E[\epsilon] \\ E[Y|X] & = \beta_0 + \beta_1X \\ \end{aligned}\]
- We call \(E[Y|X]\) the expected value (or average) of \(Y\) given \(X\)
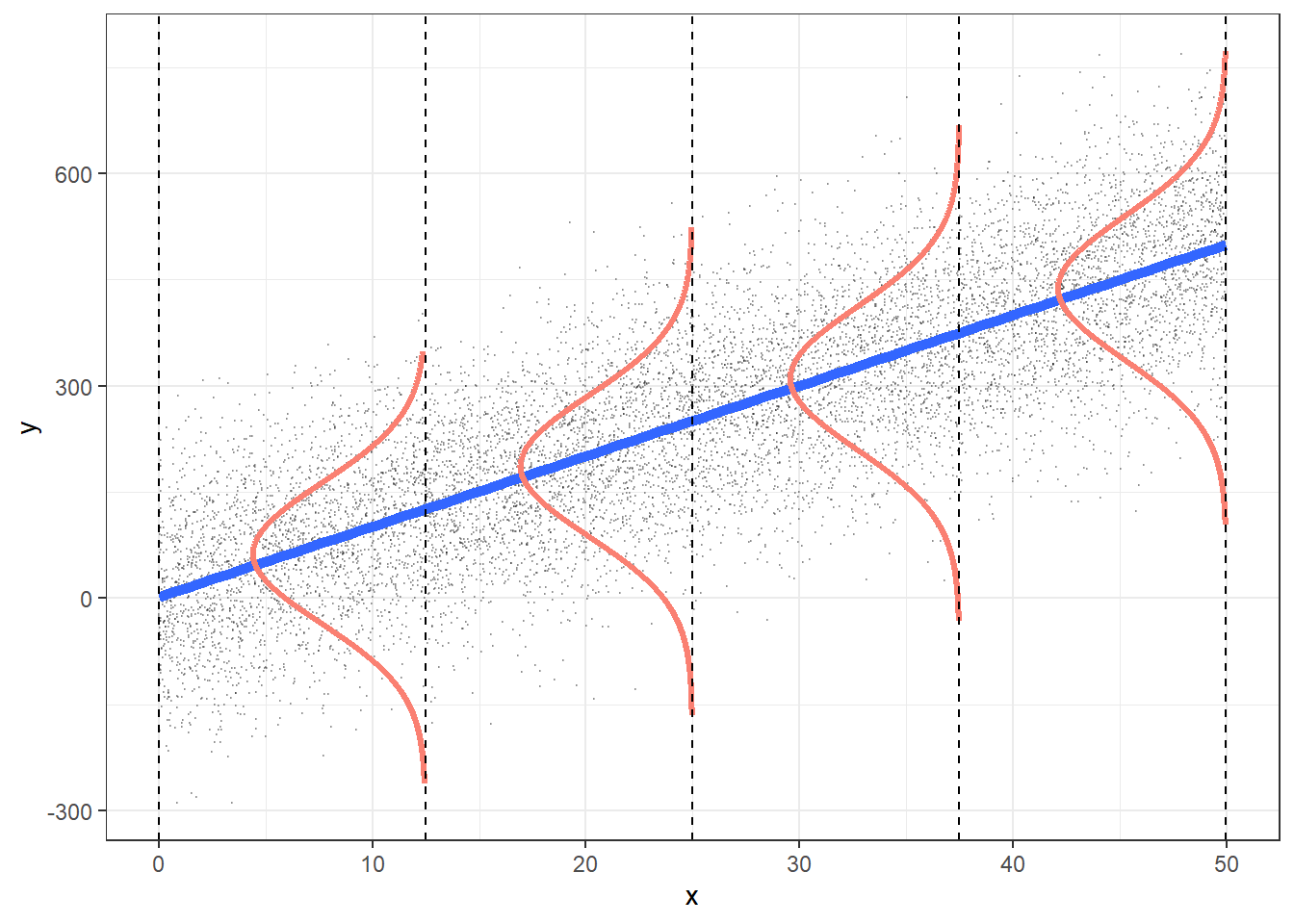
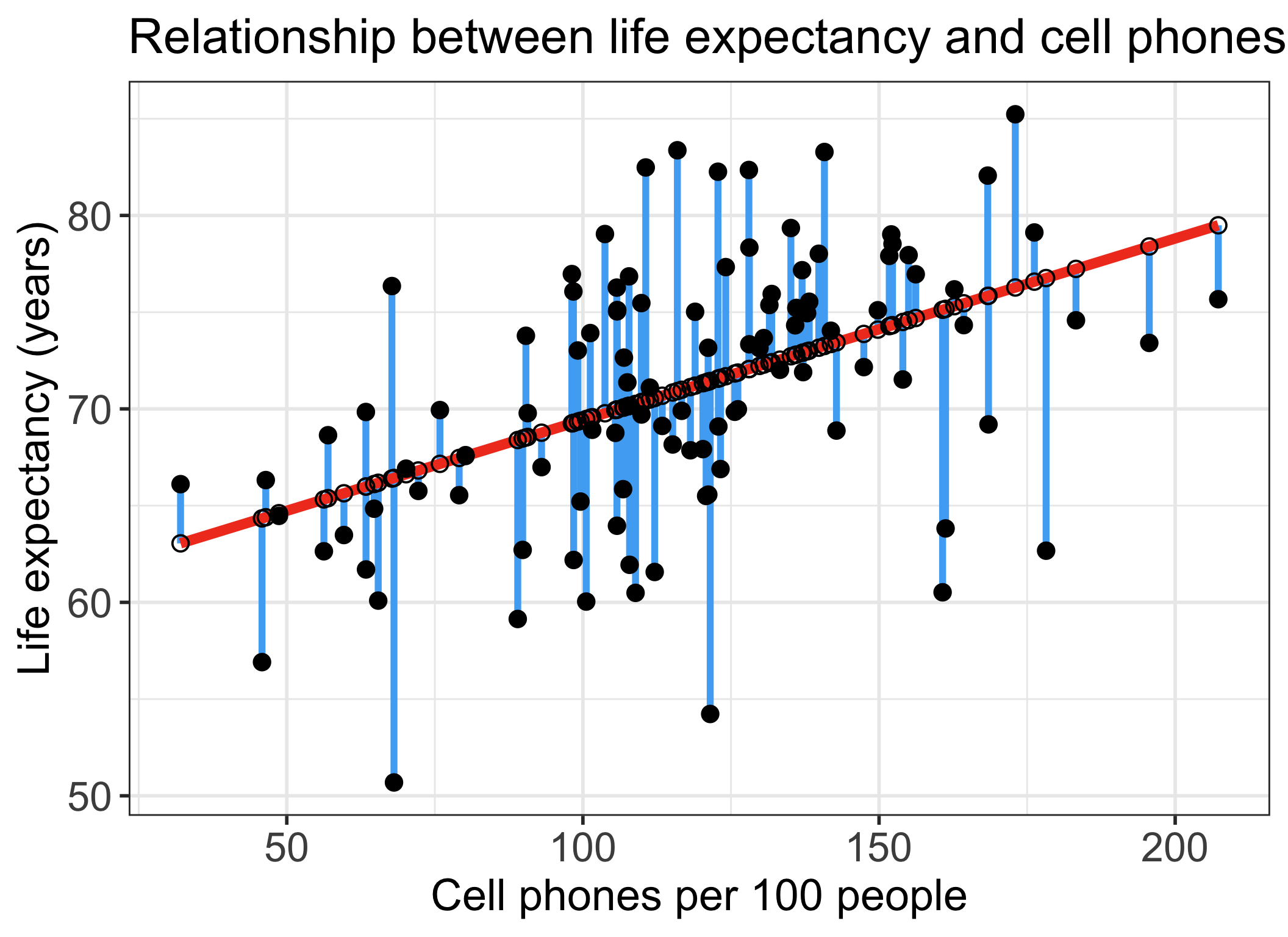
Residuals for observation \(i\) in the estimated/fitted model
- Observed values for each country \(i\): \(Y_i\)
- Value in the dataset for country \(i\)
- Fitted value for each country \(i\): \(\widehat{Y}_i\)
- Value that falls on the best-fit line for a specific \(X_i\)
- If two individuals have the same \(X_i\), then they have the same \(\widehat{Y}_i\)
Residuals for observation \(i\) in the estimated/fitted model
Observed values for each individual \(i\): \(Y_i\)
- Value in the dataset for individual \(i\)
Fitted value for each individual \(i\): \(\widehat{Y}_i\)
- Value that falls on the best-fit line for a specific \(X_i\)
- If two individuals have the same \(X_i\), then they have the same \(\widehat{Y}_i\)
Residual for each individual: \(\widehat\epsilon_i = Y_i - \widehat{Y}_i\)
- Difference between the observed and fitted value
Do I need to do all that work every time??
