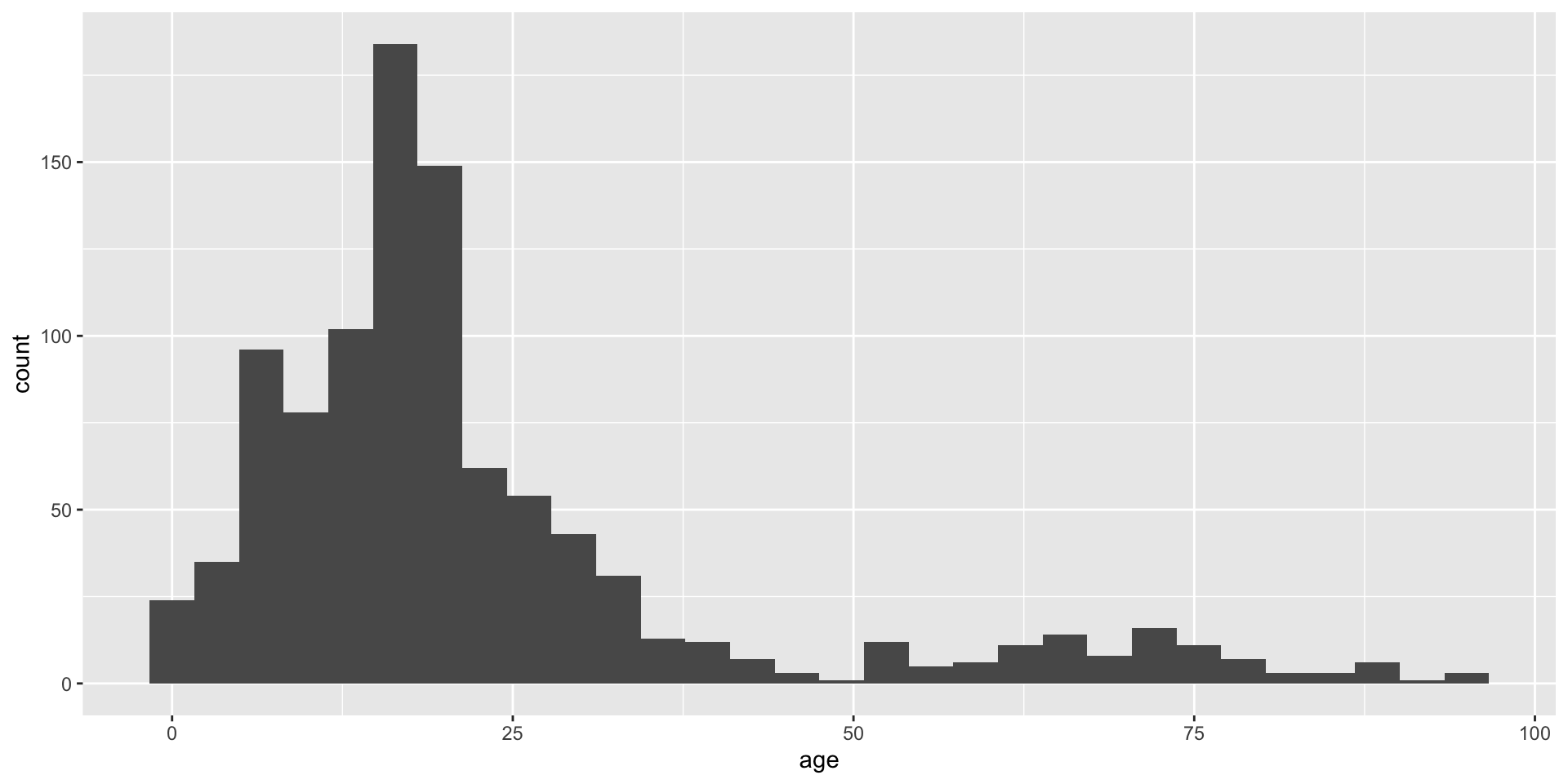
Main sections of the course
Review
Simple Linear Regression
- Model evaluation and Model use
Intro to MLR: estimation and testing
- Model use
Diving into our predictors: categorical variables, interactions between variable
- Model fitting
Key ingredients: model evaluation, diagnostics, selection, and building
- Model evaluation and Model selection