Lesson 4: SLR Inference and Prediction
2025-01-15
Process of regression data analysis

![]()
![]()
Model Selection
Building a model
Selecting variables
Prediction vs interpretation
Comparing potential models
Model Fitting
Find best fit line
Using OLS in this class
Parameter estimation
Categorical covariates
Interactions
Model Evaluation
- Evaluation of model fit
- Testing model assumptions
- Residuals
- Transformations
- Influential points
- Multicollinearity
Model Use (Inference)
- Inference for coefficients
- Hypothesis testing for coefficients
- Inference for expected \(Y\) given \(X\)
- Prediction of new \(Y\) given \(X\)
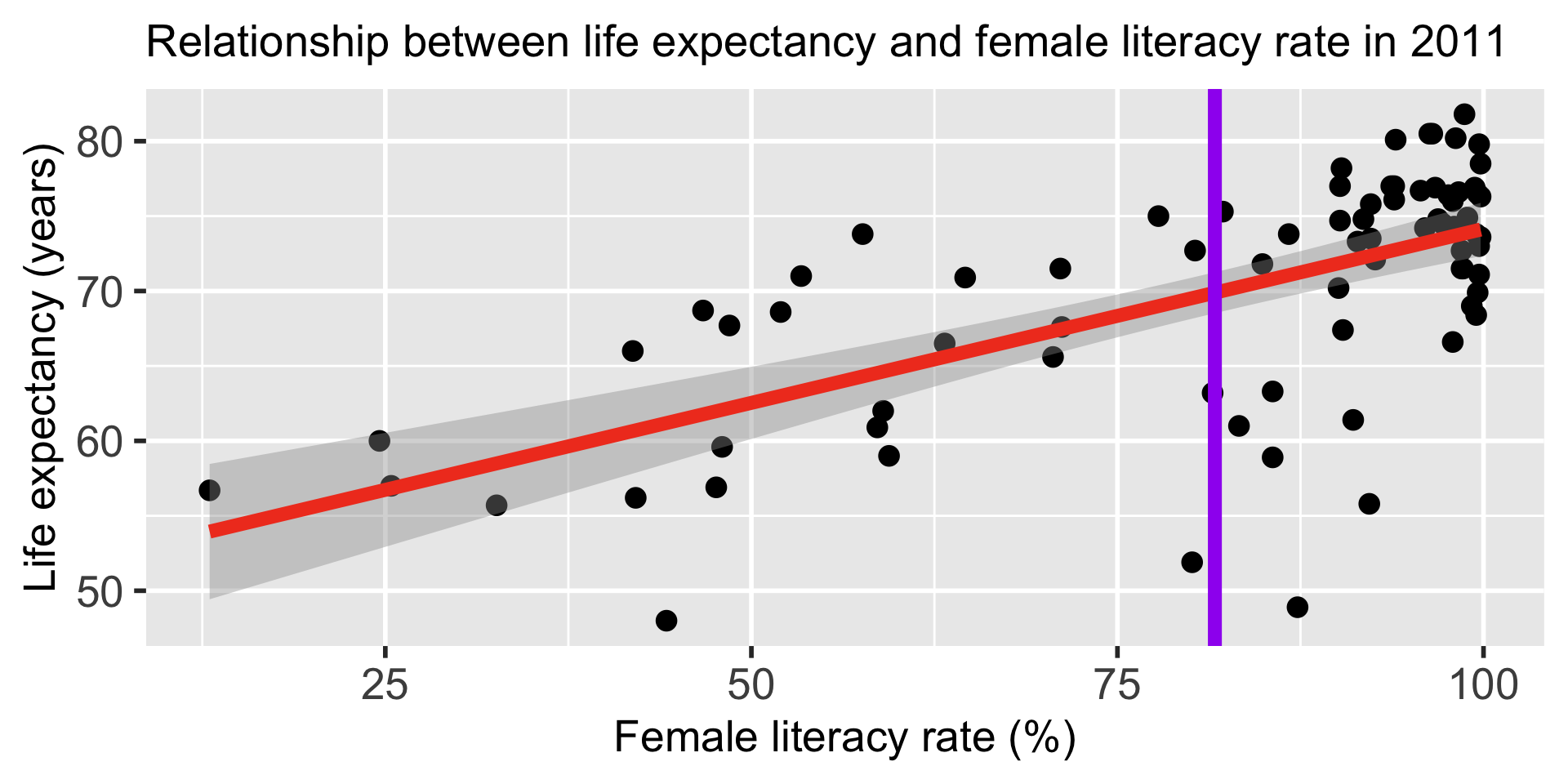
Let’s remind ourselves of the model that we fit last lesson
We fit Gapminder data with female literacy rate as our independent variable and life expectancy as our dependent variable
We used OLS to find the coefficient estimates of our best-fit line
model1 <- gapm %>% lm(formula = LifeExpectancyYrs ~ FemaleLiteracyRate)
# Get regression table:
tidy(model1) %>% gt() %>%
tab_options(table.font.size = 40) %>%
fmt_number(decimals = 2)| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 50.93 | 2.66 | 19.14 | 0.00 |
| FemaleLiteracyRate | 0.23 | 0.03 | 7.38 | 0.00 |
Standard error of fitted slope \(\widehat\beta_1\)

\[\text{SE}_{\widehat\beta_1} = \frac{s_{\textrm{residuals}}}{s_x\sqrt{n-1}}\]
\(\text{SE}_{\widehat\beta_1}\) is the variability of the statistic \(\widehat\beta_1\)
- \(s_{\textrm{residuals}}^2\) is the sd of the residuals
- \(s_x\) is the sample sd of the explanatory variable \(x\)
- \(n\) is the sample size, or the number of (complete) pairs of points
Calculating standard error for \(\widehat\beta_1\) (1/2)
- Option 1: Calculate using the formula
# A tibble: 1 × 12
r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0.411 0.403 6.14 54.4 1.50e-10 1 -258. 521. 529.
# ℹ 3 more variables: deviance <dbl>, df.residual <int>, nobs <int># standard deviation of the residuals (Residual standard error in summary() output)
(s_resid <- glance(model1)$sigma)[1] 6.142157[1] 21.95371[1] 80[1] 0.03147744Calculating standard error for \(\widehat\beta_1\) (2/2)
- Option 2: Use regression table
# recall model1_b1 is regression table restricted to b1 row
model1_b1 <-tidy(model1) %>% filter(term == "FemaleLiteracyRate")
model1_b1 %>% gt() %>%
tab_options(table.font.size = 45) %>% fmt_number(decimals = 4)| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| FemaleLiteracyRate | 0.2322 | 0.0315 | 7.3766 | 0.0000 |
Mean response/prediction with regression line
Recall the population model:
line + random “noise”
\[Y = \beta_0 + \beta_1 \cdot X + \varepsilon\] with \(\varepsilon \sim N(0,\sigma^2)\)
- When we take the expected value, at a given value \(X^*\), the average expected response at \(X^*\) is:
\[\widehat{E}[Y|X^*] = \widehat\beta_0 + \widehat\beta_1 X^*\]
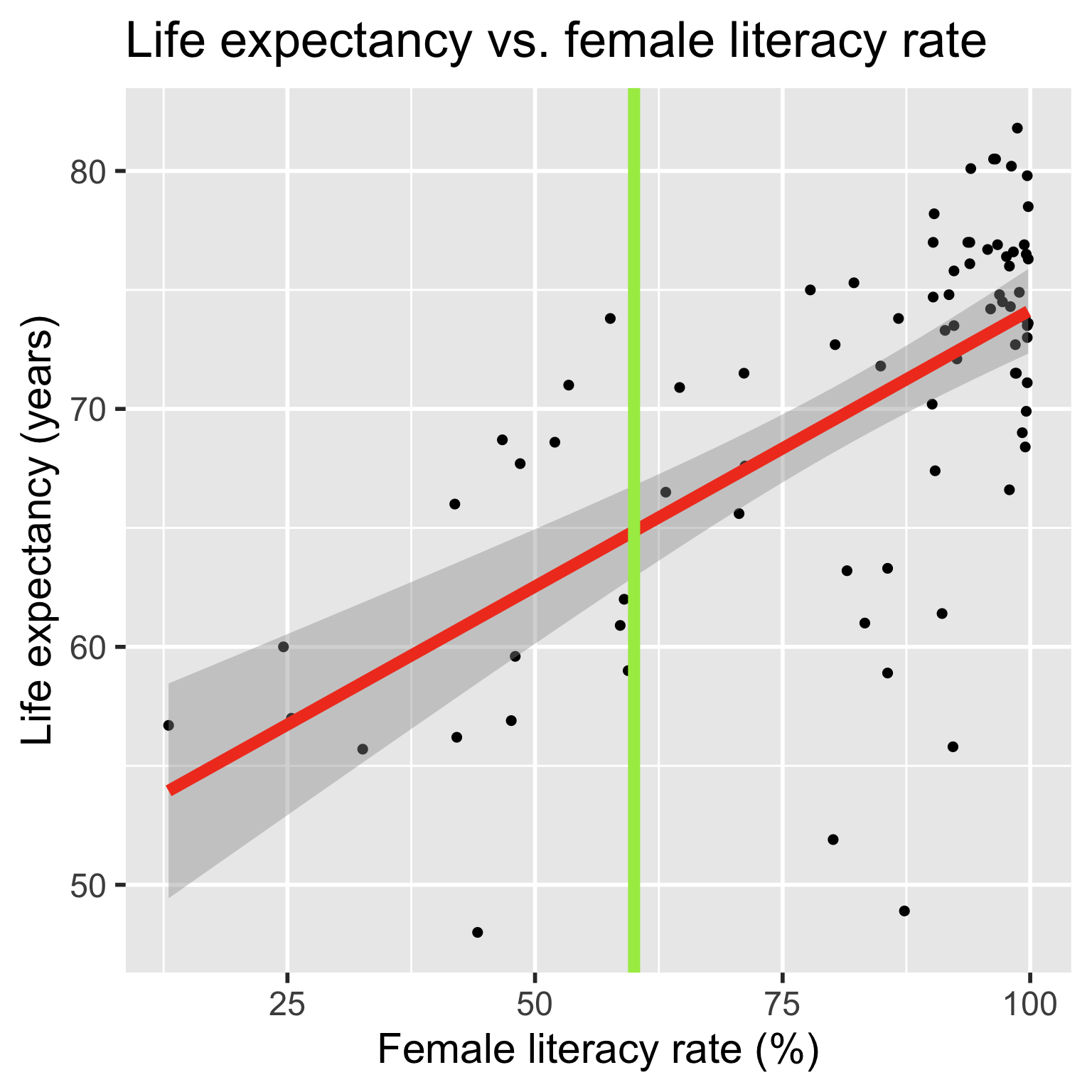
- These are the points on the regression line
- The mean responses have variability, and we can calculate a CI for it, for every value of \(X^*\)
Confidence bands for mean response \(\mu_{Y|X^*}\)
- Often we plot the CI for many values of X, creating confidence bands
- The confidence bands are what ggplot creates when we set
se = TRUEwithingeom_smooth - Think about it: for what values of X are the confidence bands (intervals) narrowest?
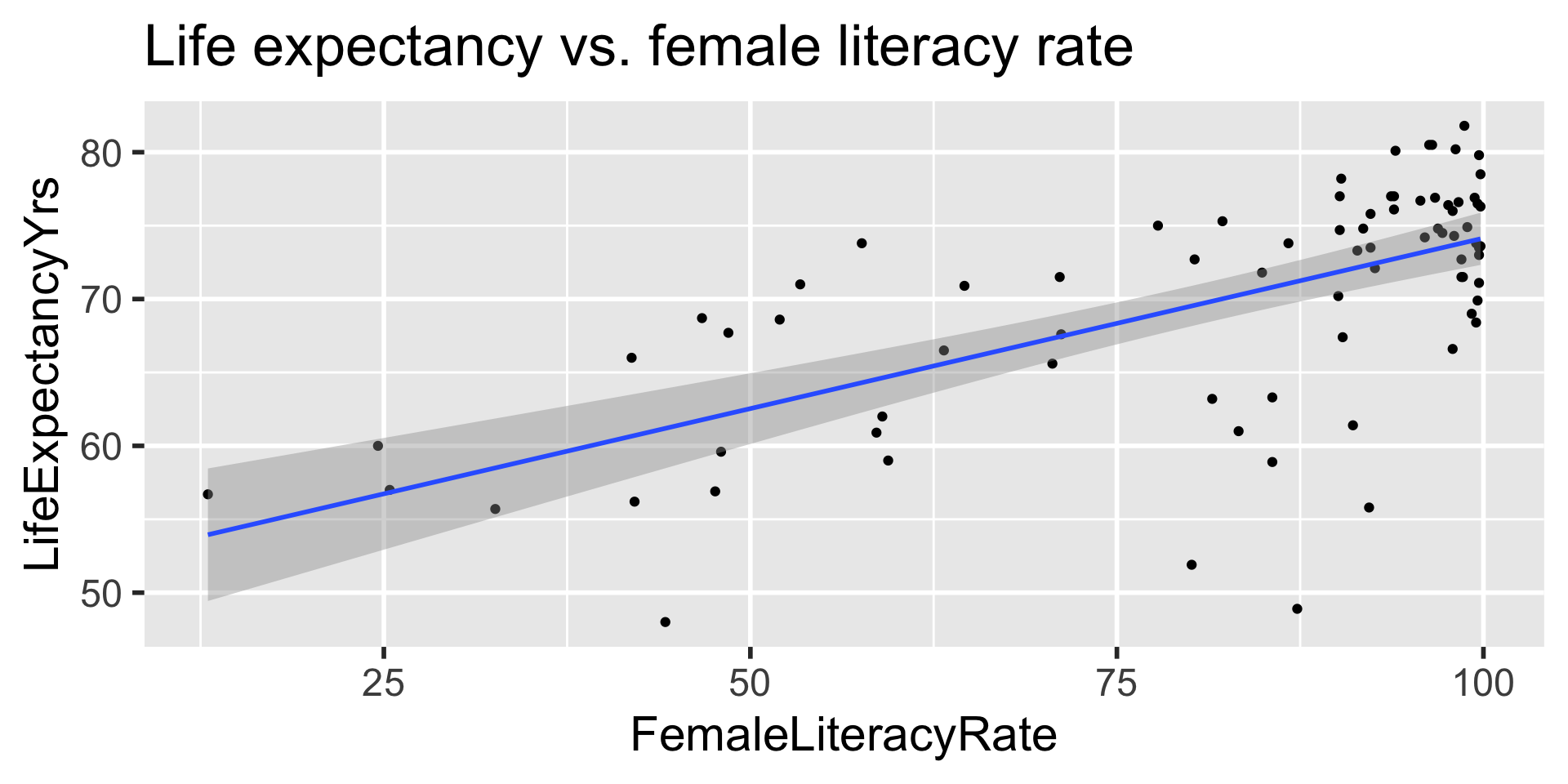
Width of confidence bands for mean response \(\mu_{Y|X^*}\)
- For what values of \(X^*\) are the confidence bands (intervals) narrowest? widest?