Lesson 6: SLR: More inference
2025-01-27
Process of regression data analysis

![]()
![]()
Model Selection
Building a model
Selecting variables
Prediction vs interpretation
Comparing potential models
Model Fitting
Find best fit line
Using OLS in this class
Parameter estimation
Categorical covariates
Interactions
Model Evaluation
- Evaluation of model fit
- Testing model assumptions
- Residuals
- Transformations
- Influential points
- Multicollinearity
Model Use (Inference)
- Inference for coefficients
- Hypothesis testing for coefficients
- Inference for expected \(Y\) given \(X\)
- Prediction of new \(Y\) given \(X\)
Explained vs. Unexplained Variation
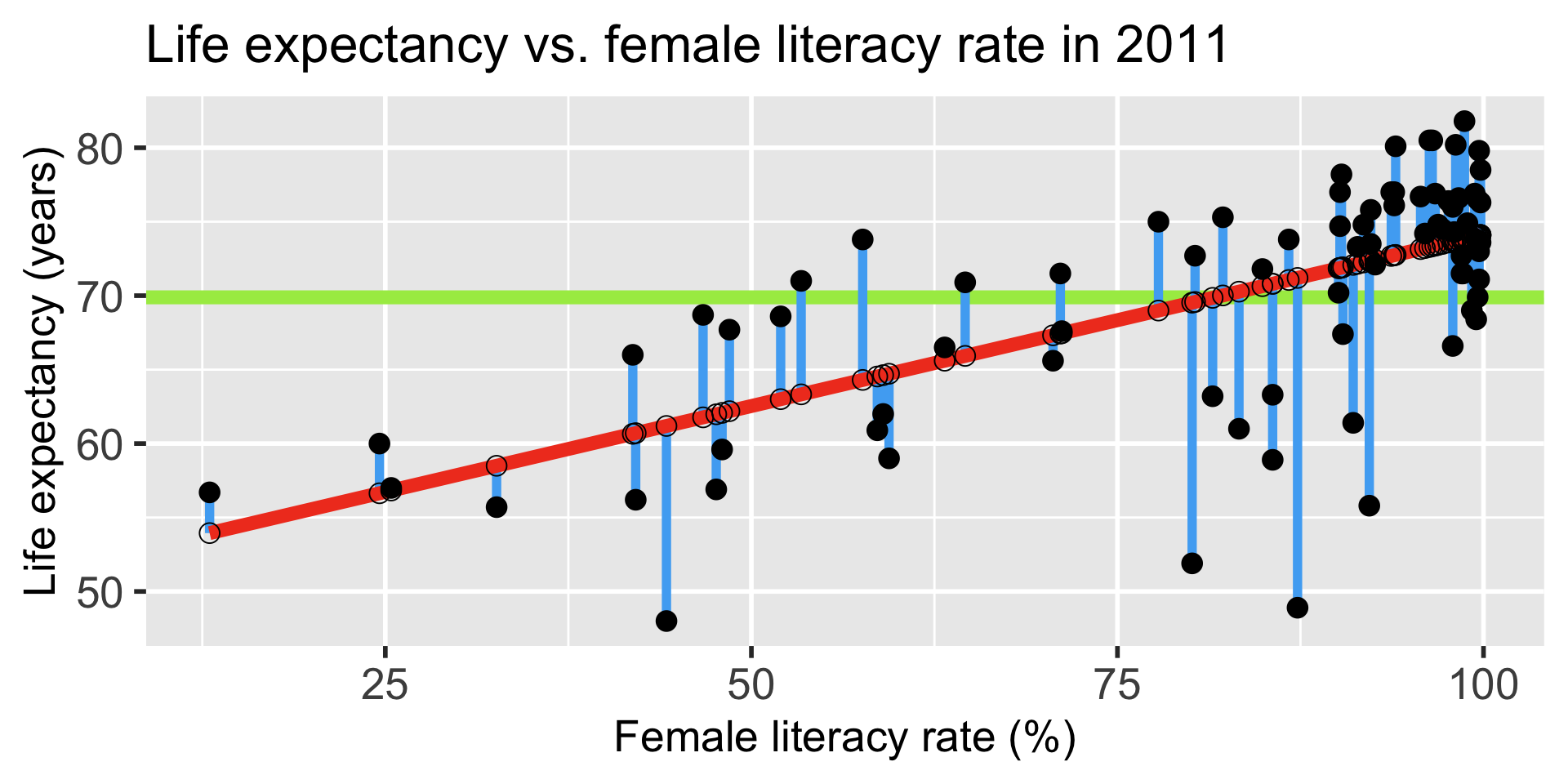
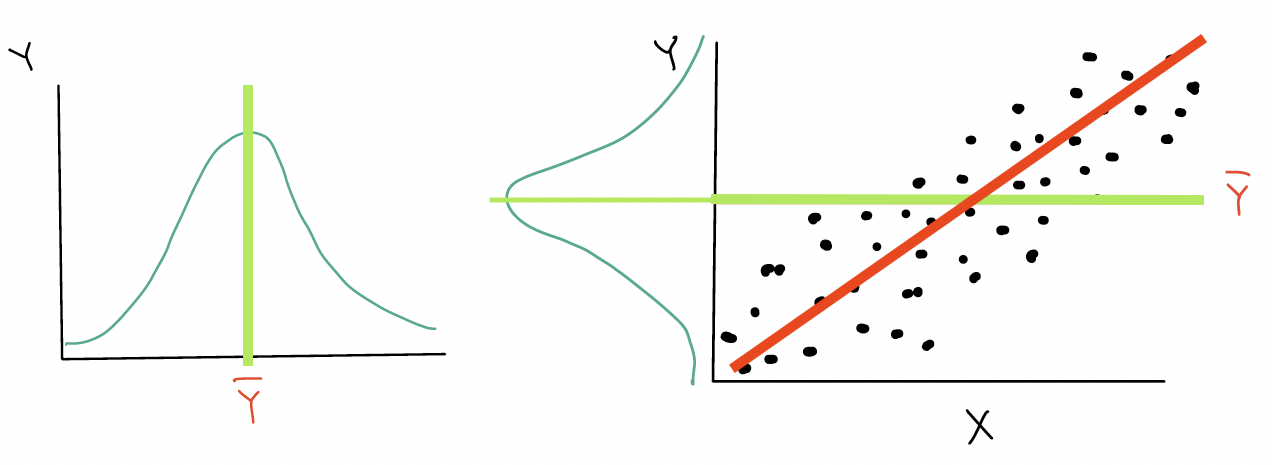
\[ \begin{aligned} Y_i - \overline{Y} & = (Y_i - \widehat{Y}_i) + (\widehat{Y}_i- \overline{Y})\\ \text{Total variation} & = \text{Residual variation after regression} + \text{Variation explained by regression} \end{aligned}\]
More on the equation
\[Y_i - \overline{Y} = (Y_i - \widehat{Y}_i) + (\widehat{Y}_i- \overline{Y})\]
- \(Y_i - \overline{Y}\) = the deviation of \(Y_i\) around the mean \(\overline{Y}\)
- (the total amount deviation)
- \(Y_i - \widehat{Y}_i\) = the deviation of the observation \(Y\) around the fitted regression line
- (the amount deviation unexplained by the regression at \(X_i\) ).
- \(\widehat{Y_i}- \overline{Y}\) = the deviation of the fitted value \(\widehat{Y}_i\) around the mean \(\overline{Y}\)
- (the amount deviation explained by the regression at \(X_i\) )
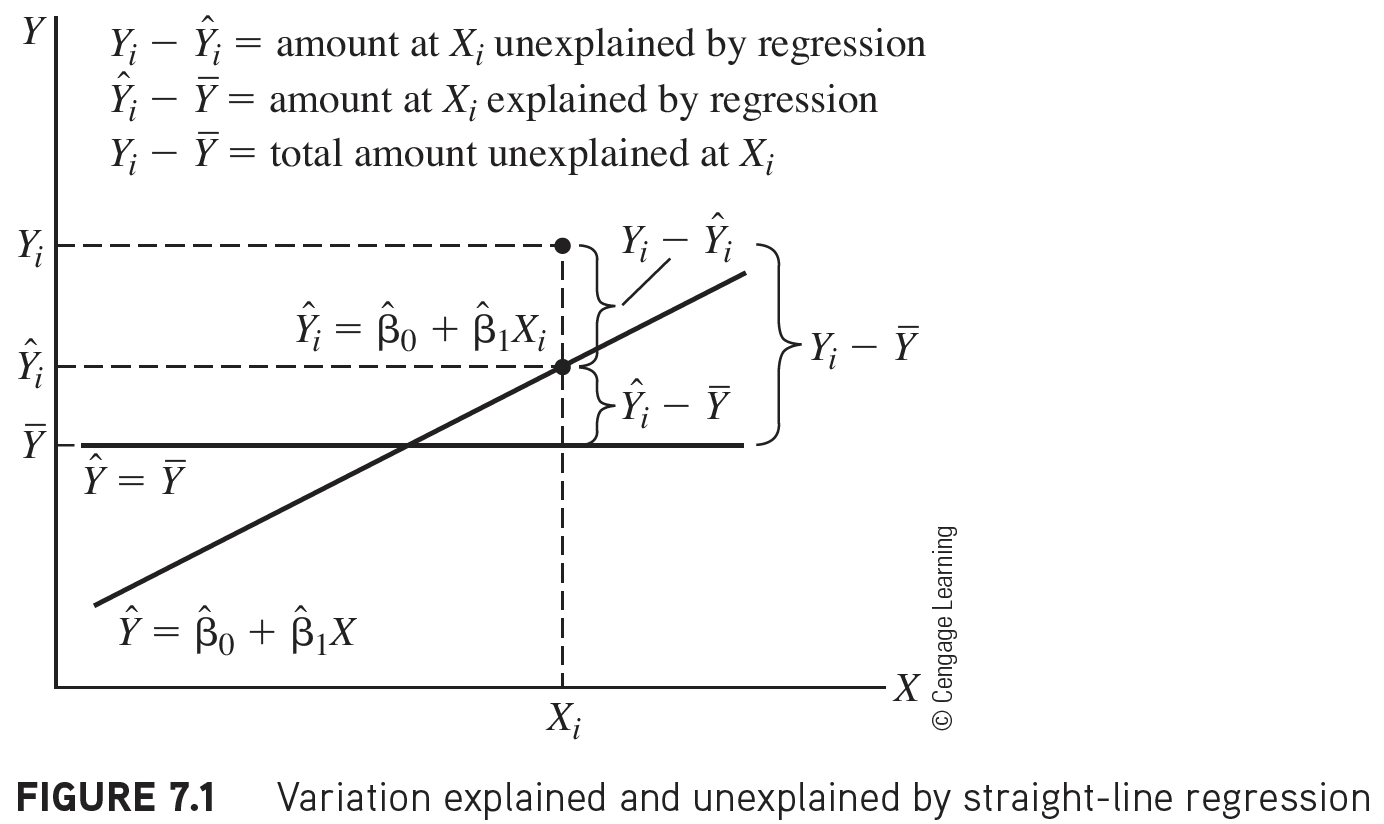
Another way of thinking about the different deviations
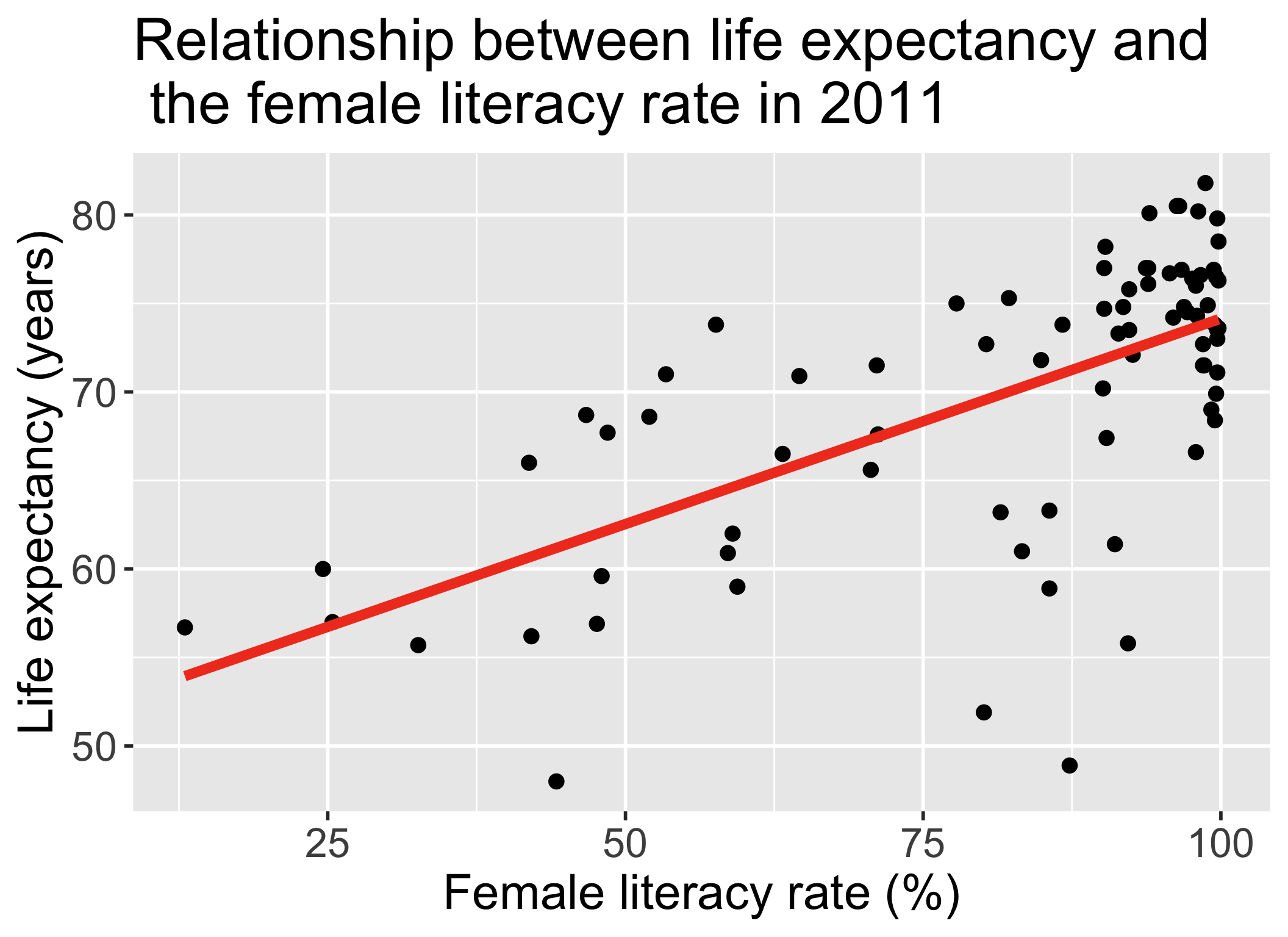
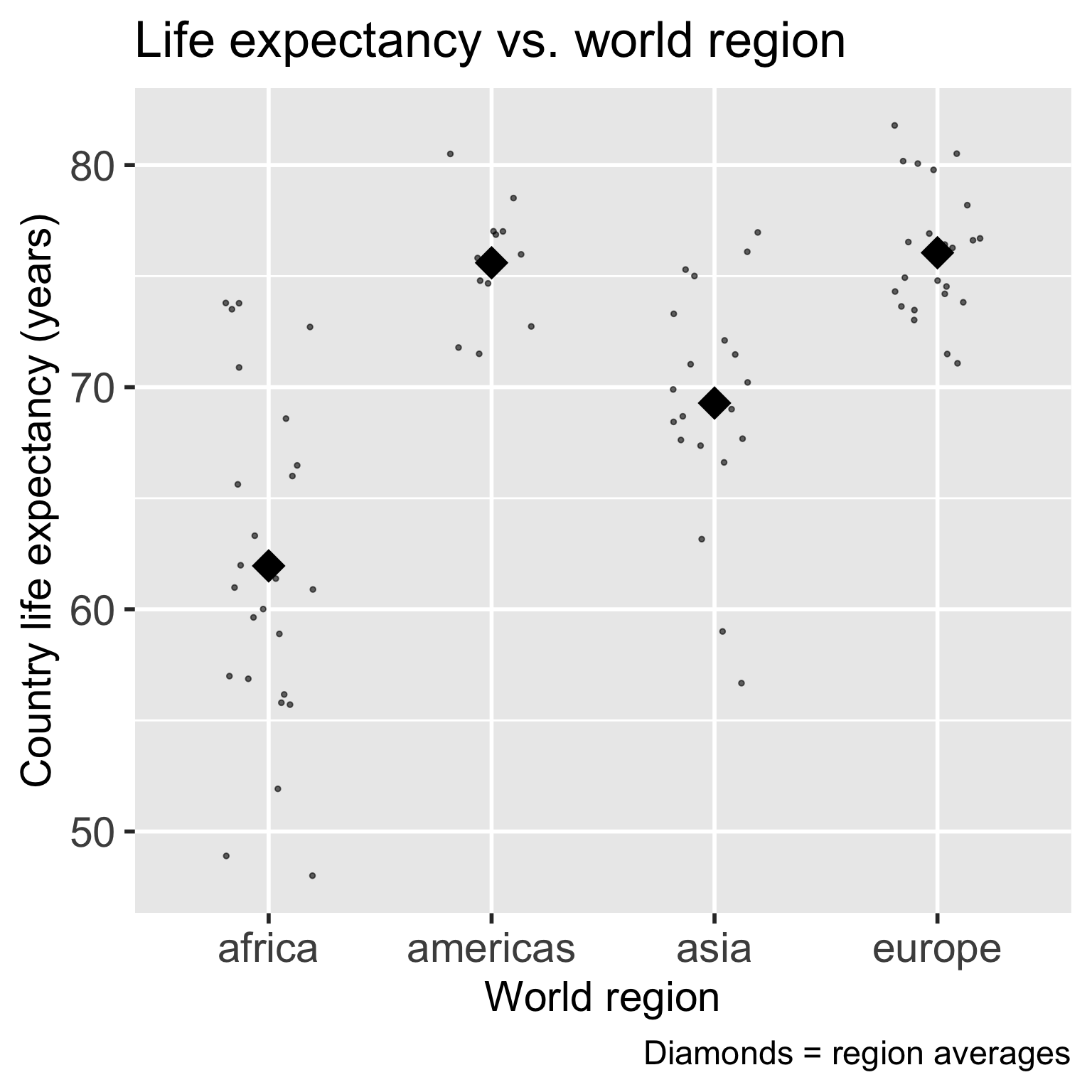
Let’s say we want to test the association between life expectancy and world region
\[\begin{aligned} \widehat{\textrm{LE}} = & 61.96 + 13.64 \cdot I(\text{Americas}) + \\ &7.33 \cdot I(\text{Asia}) + 14.1 \cdot I(\text{Europe}) \\ \widehat{\textrm{LE}} = & \widehat\beta_0 + \widehat\beta_1 \cdot I(\text{Americas}) + \\ & \widehat\beta_2 \cdot I(\text{Asia}) + \widehat\beta_3 \cdot I(\text{Europe}) \end{aligned}\]
- We need to figure out if the model with world region explains significantly more variation than the model without world region!
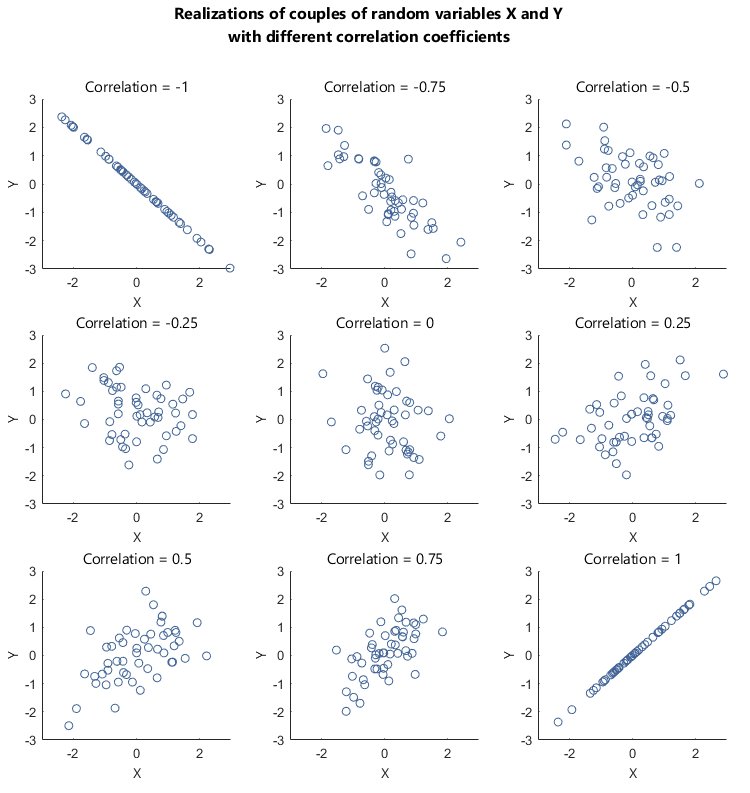
Correlation coefficient from 511
Correlation coefficient \(r\) can tell us about the strength of a relationship between two continuous variables
If \(r = -1\), then there is a perfect negative linear relationship between \(X\) and \(Y\)
If \(r = 1\), then there is a perfect positive linear relationship between \(X\) and \(Y\)
If \(r = 0\), then there is no linear relationship between \(X\) and \(Y\)
Note: All other values of \(r\) tell us that the relationship between \(X\) and \(Y\) is not perfect. The closer \(r\) is to 0, the weaker the linear relationship.
Correlation coefficient (\(r\) or \(R\))
The (Pearson) correlation coefficient \(r\) of variables \(X\) and \(Y\) can be computed using the formula:
\[\begin{aligned} r & = \frac{\sum_{i=1}^n (X_i - \overline{X})(Y_i - \overline{Y})}{\Big(\sum_{i=1}^n (X_i - \overline{X})^2 \sum_{i=1}^n (Y_i - \overline{Y})^2\Big)^{1/2}} \\ & = \frac{SSXY}{\sqrt{SSX \cdot SSY}} \end{aligned}\]
we have the relationship
\[\widehat{\beta}_1 = r\frac{SSY}{SSX},\ \ \text{or},\ \ r = \widehat{\beta}_1\frac{SSX}{SSY}\]
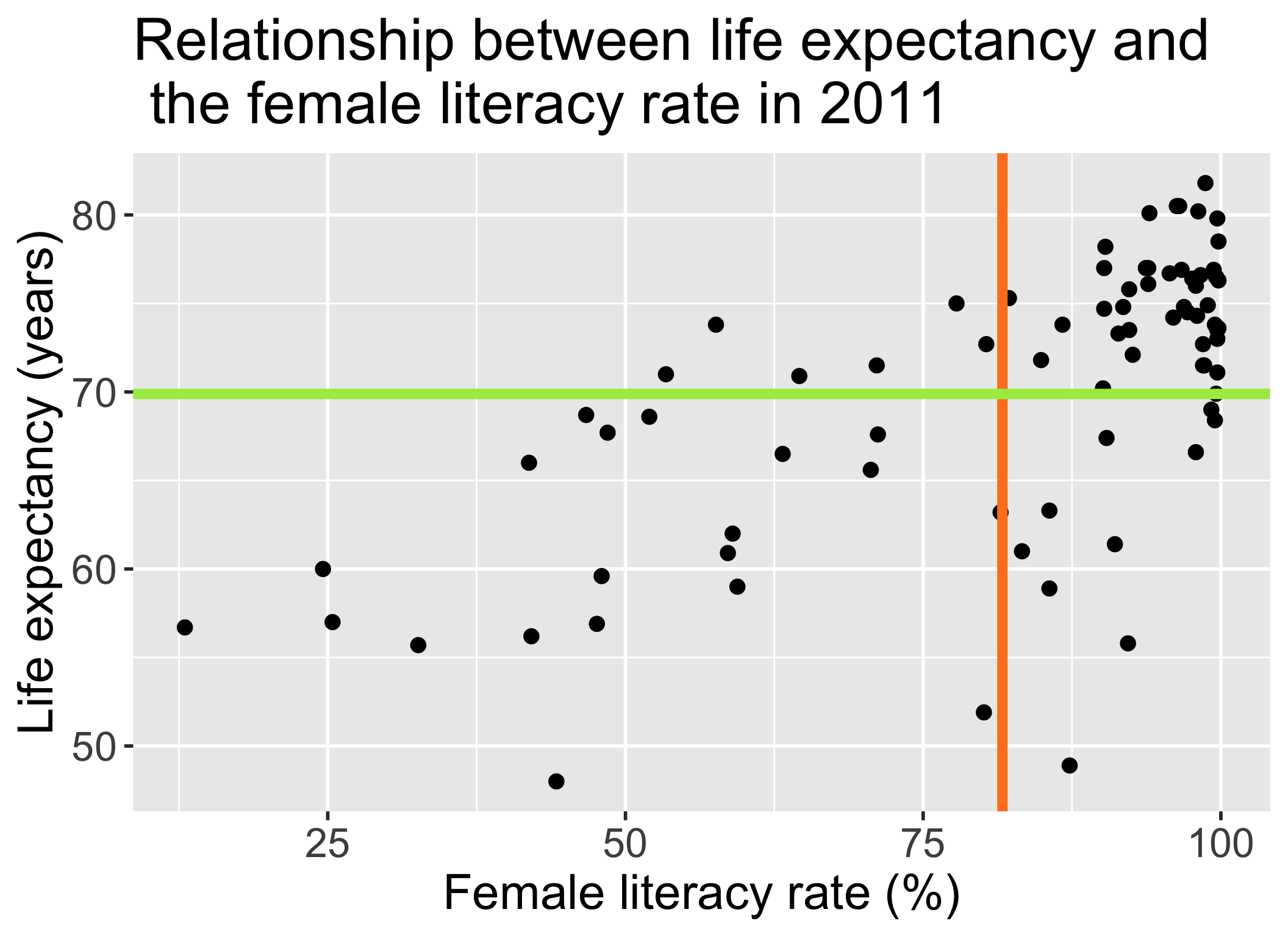
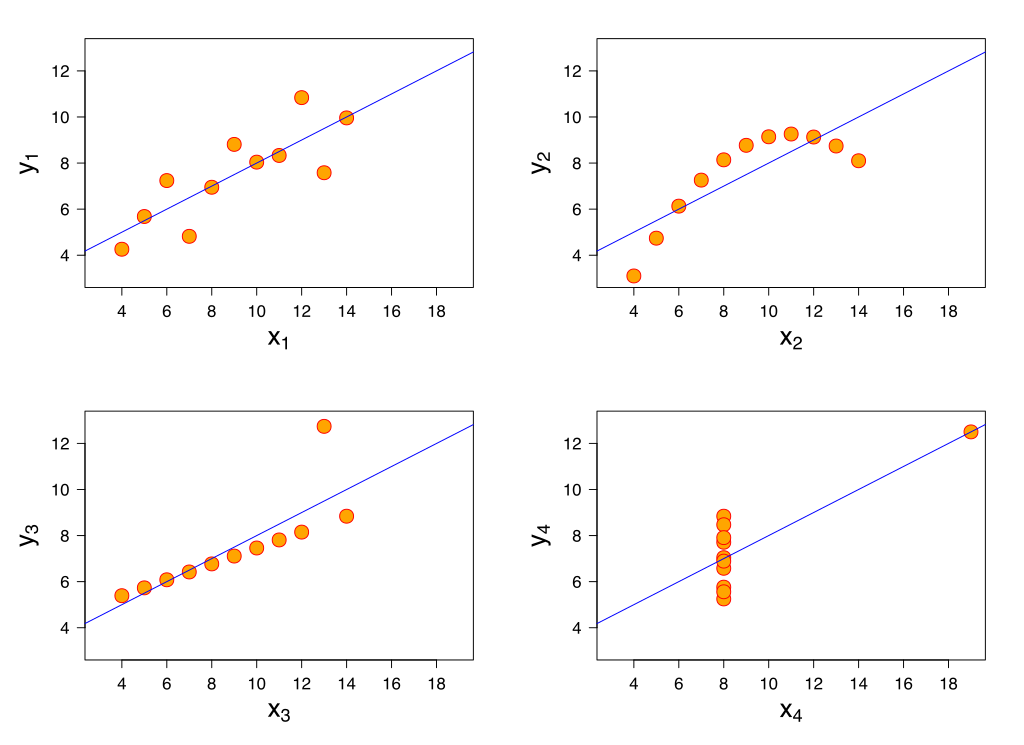
What does \(R^2\) not measure?
\(R^2\) is not a measure of the magnitude of the slope of the regression line
- Example: can have \(R^2 = 1\) for many different slopes!!
\(R^2\) is not a measure of the appropriateness of the straight-line model
- Example: figure