Lesson 11: Interactions, Part 1
2025-02-12
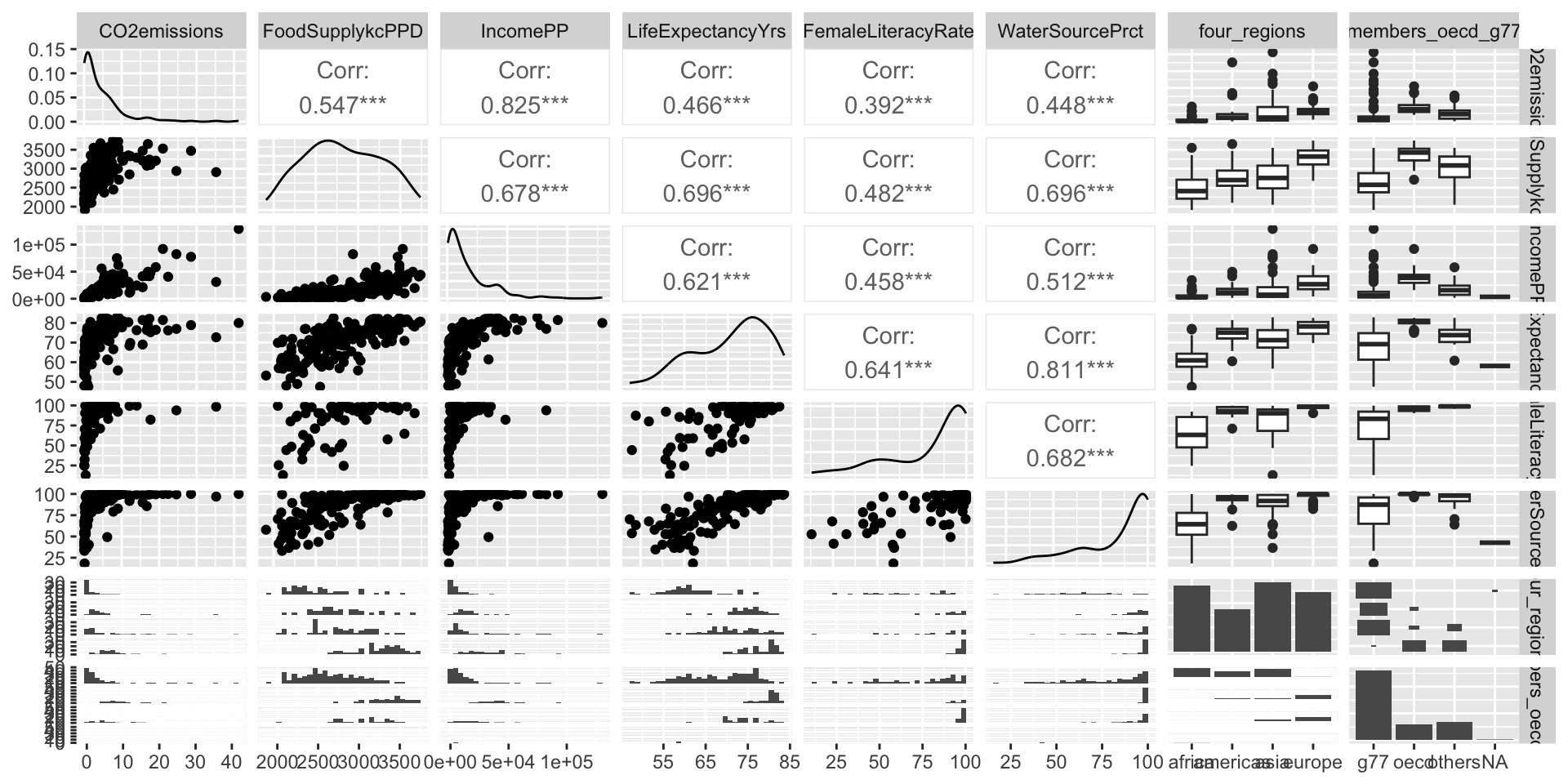
Regression analysis process

![]()
![]()
Model Selection
Building a model
Selecting variables
Prediction vs interpretation
Comparing potential models
Model Fitting
Find best fit line
Using OLS in this class
Parameter estimation
Categorical covariates
Interactions
Model Evaluation
- Evaluation of model fit
- Testing model assumptions
- Residuals
- Transformations
- Influential points
- Multicollinearity
Model Use (Inference)
- Inference for coefficients
- Hypothesis testing for coefficients
- Inference for expected \(Y\) given \(X\)
- Prediction of new \(Y\) given \(X\)
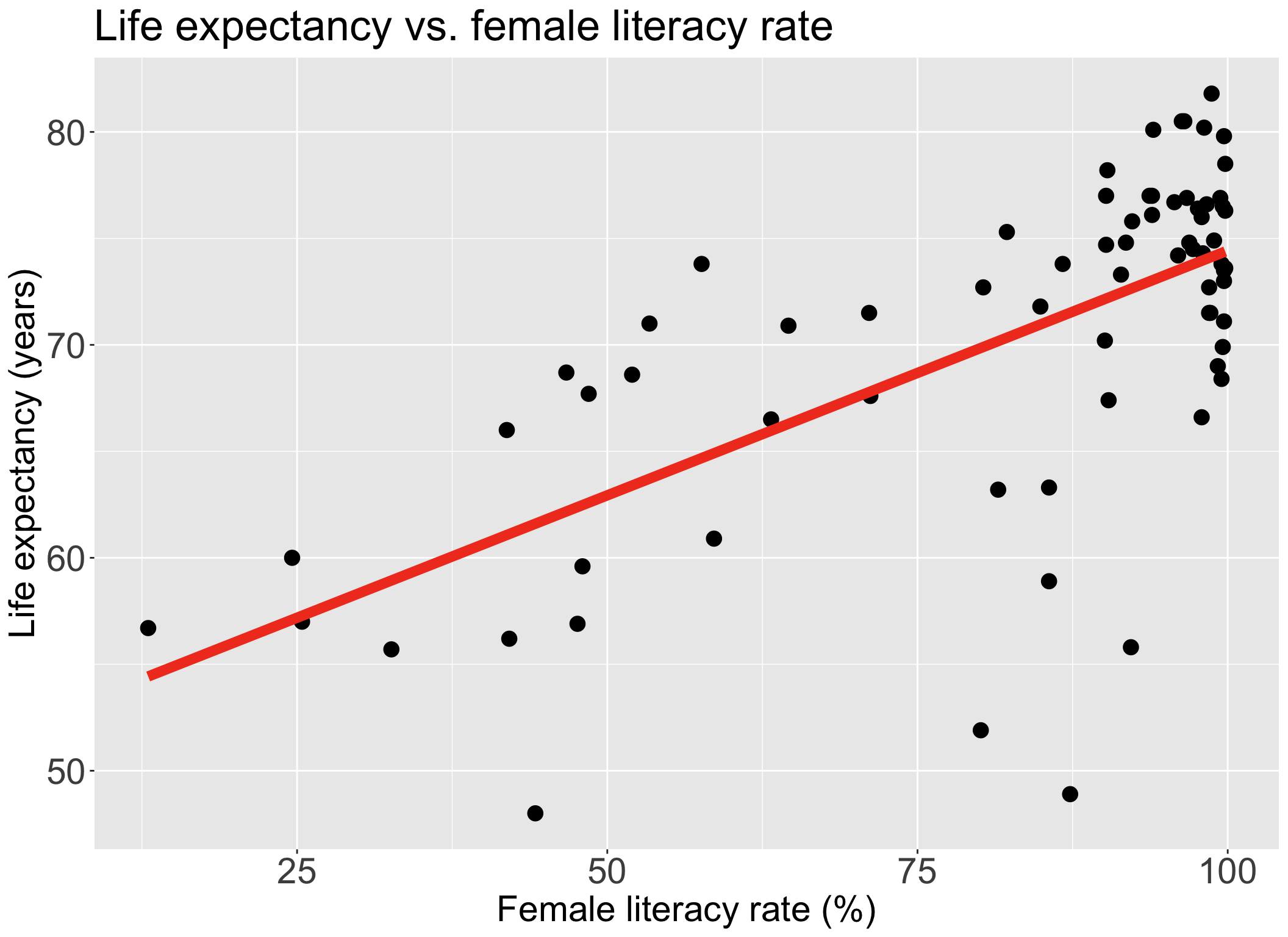
Recall our data and the main relationship
What is a confounder?
- A confounding variable, or confounder, is a factor/variable that wholly or partially accounts for the observed effect of the risk factor on the outcome
A confounder must be…
- Related to the outcome Y, but not a consequence of Y
- Related to the explanatory variable X, but not a consequence of X

- A classic example: We found an association between ice cream consumption and sunburn!
- If we adjust for a potential confounder, temperature/hot weather, we may see that the association between ice and sunburn is not as large
- Another example: We found an association between socioeconomic status (SES) and lung cancer!
- If we adjust for a potential confounder, exposure to air pollution, we may see that the association between SES and lung cancer decreases
Exploratory approach to identifying confounders
What is an effect modifier?
An additional variable in the model
- Outside of the main relationship between \(Y\) and \(X_1\) that we are studying
An effect modifier will change the effect of \(X_1\) on \(Y\) depending on its value
Aka: as the effect modifier’s values change, so does the association between \(Y\) and \(X_1\)
So the coefficient estimating the relationship between \(Y\) and \(X_1\) changes with another variable
Example: A breast cancer education program (the exposure) that is much more effective in reducing breast cancer (outcome) in rural areas than urban areas.
- Location (rural vs. urban) is the EMM
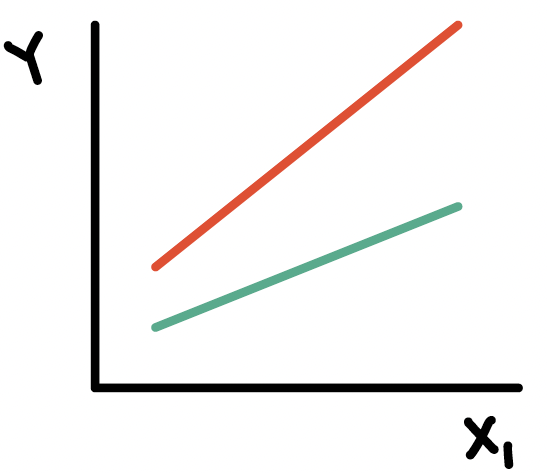
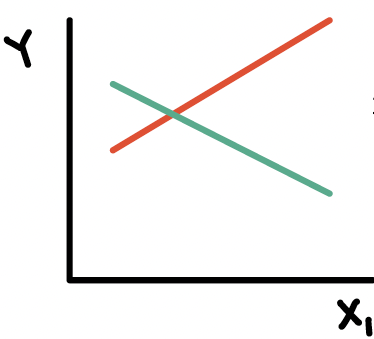
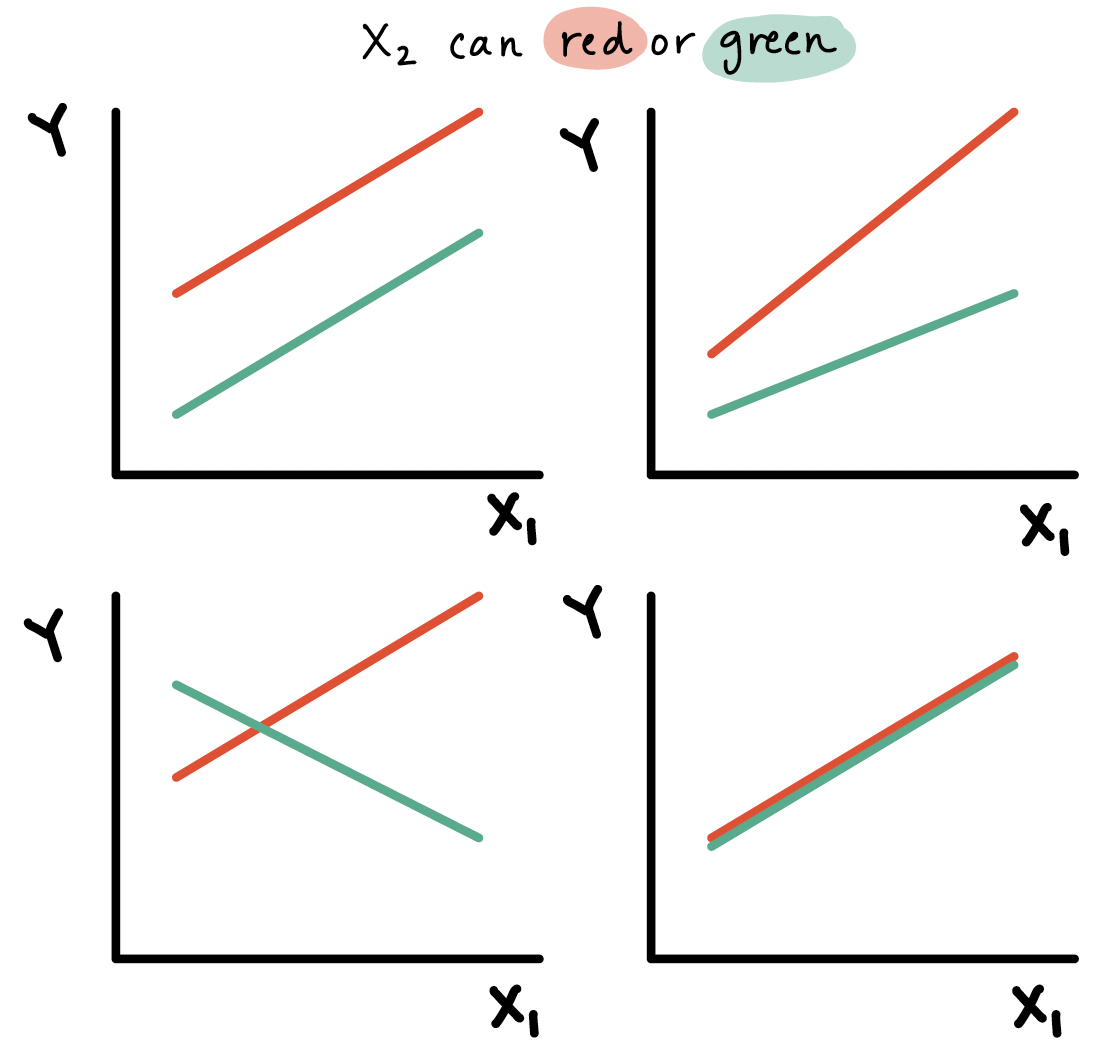
Types of interactions / non-interactions
Common types of interactions:
Synergism: \(X_{2}\) strengthens the \(X_{1}\) effect
Antagonism:\(X_{2}\) weakens the \(X_{1}\) effect
If the interaction coefficient is not significant
- No evidence of effect modification, i.e., the effect of \(X_{1}\) does not vary with \(X_{2}\)
If the main effect of \(X_2\) is also not significant
- No evidence that \(X_2\) is a confounder
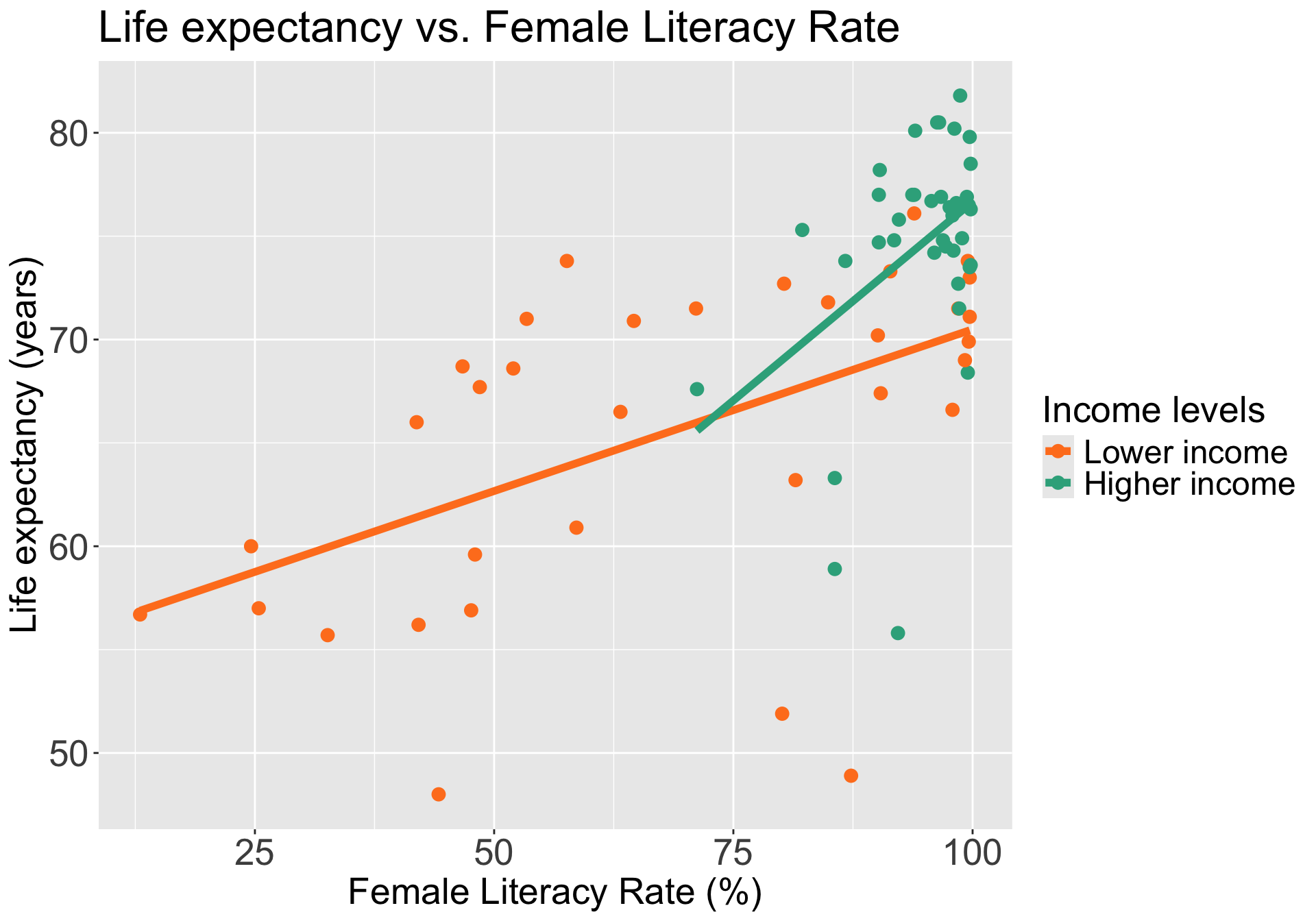
Do we think income level is an effect modifier for female literacy rate?
Let’s say we only have two income groups: low income and high income
We can start by visualizing the relationship between life expectancy and female literacy rate by income level
Questions of interest: Is the effect of female literacy rate on life expectancy differ depending on income level?
- This is the same as: Is income level is an effect modifier for female literacy rate?
- “effect of female literacy rate” differing = different slopes between FLR and LE depending on the income group
Let’s run an interaction model to see!
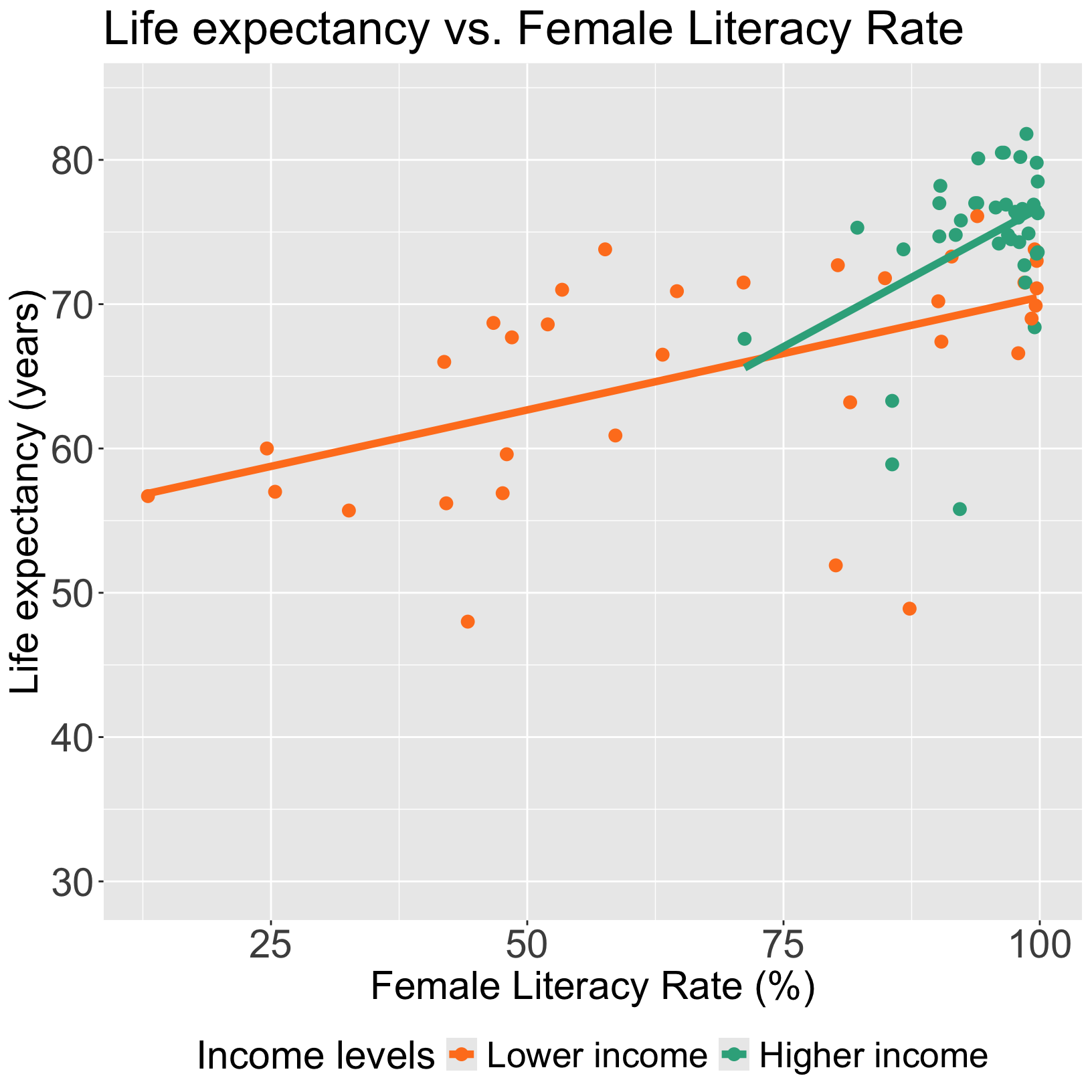
Let’s take a look back at the plot
For lower income countries: \(I(\text{high income}) =0\)
\[ \begin{aligned} \widehat{LE} = & \widehat\beta_0 + \widehat\beta_1 FLR \\ \widehat{LE} = & 54.85 + 0.156 \cdot FLR\\ \end{aligned}\]
For higher income countries: \(I(\text{high income}) =1\)
\[ \begin{aligned} \widehat{LE} = & (\widehat\beta_0 +\widehat\beta_2) + (\widehat\beta_1 +\widehat\beta_3) FLR \\ \widehat{LE} = & (54.85 - 16.65) + (0.156 + 0.228) \cdot FLR\\ \widehat{LE} = & 38.2 + 0.384 \cdot FLR\\ \end{aligned}\]
PAUSE: Centering continuous variables when including interactions

- For the high income group, the mean life expectancy had a regression line with a small intercept
\[ \begin{aligned} \widehat{LE} = & (\widehat\beta_0 +\widehat\beta_2) + (\widehat\beta_1 +\widehat\beta_3) FLR \\ \widehat{LE} = & (54.85 - 16.65) + (0.156 + 0.228) \cdot FLR\\ \widehat{LE} = & 38.2 + 0.384 \cdot FLR\\ \end{aligned}\]
Intercept of 38.2 is misleading because
- Makes you think some of the life expectancies for high income countries are lower than that of low income countries (depending on the FLR)
- There are no high income countries with FLR less than ~70%
Other online sources about when and when not to center:
Centering a variable
Centering a variable means that we will subtract the mean or median (or other measurement of center) from the measured value
Mean centered: \[X_i^c = X_i - \overline{X}\]
Median centered: \[X_i^c = X_i - \text{median } X\]
Centering the continuous variables in a model (when they are involved in interactions) helps with:
Interpretations of the coefficient estimates
Correlation between the main effect for the variable and the interaction that it is involved with
- To be discussed in future lecture: leads to multicollinearity issues
It’ll be helpful to center female literacy rate
- Centering female literacy rate: \[ FLR^c = FLR - \overline{FLR}\]
- Centering in R:
- I’m going to print the mean so I can use it for my interpretations
Now all intercept values (in each respective world region) will be the mean life expectancy when female literacy rate is 82.03%
We will used center FLR for the rest of the lecture
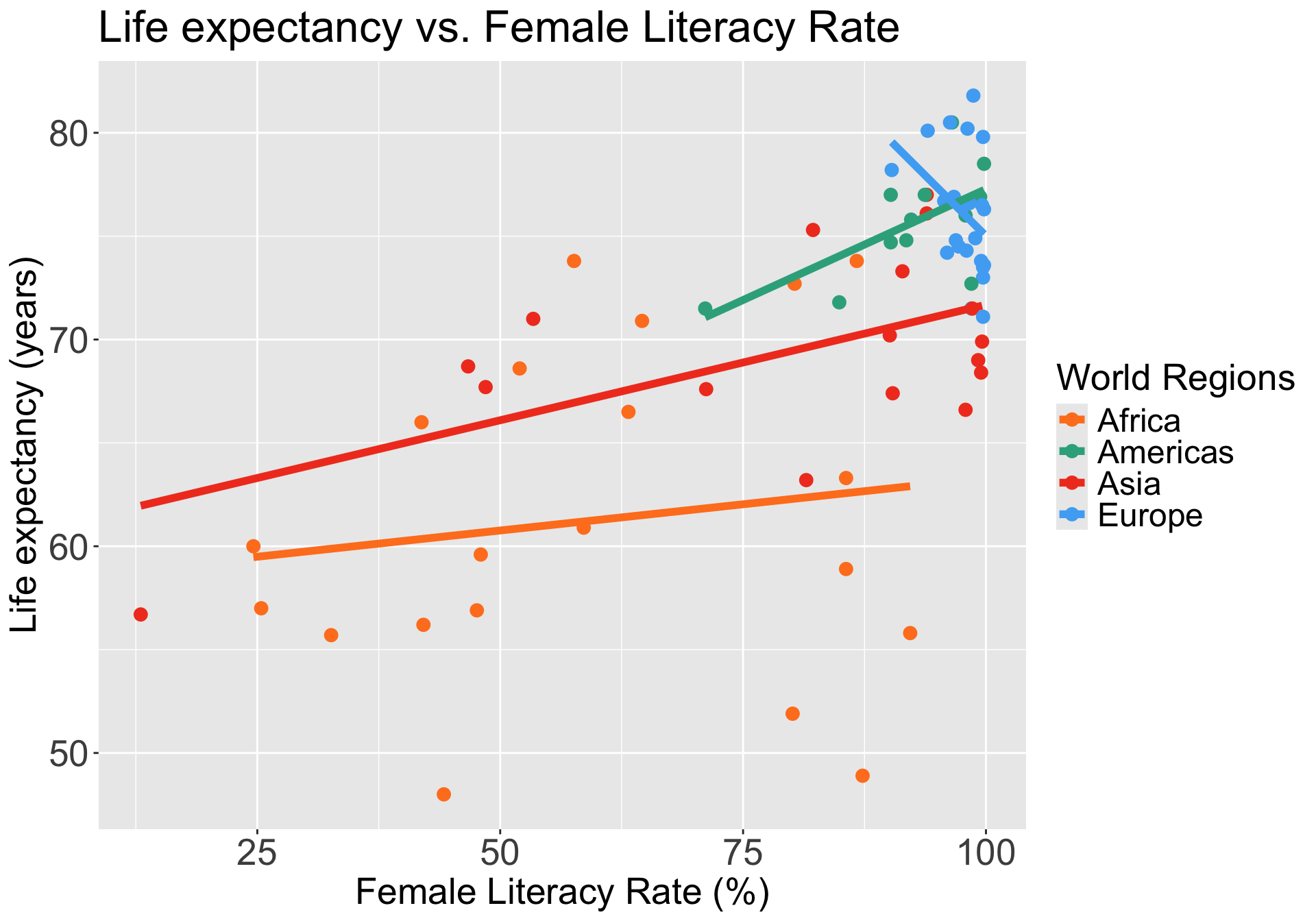
Do we think world region is an effect modifier for female literacy rate?
We can start by visualizing the relationship between life expectancy and female literacy rate by world region
Questions of interest: Does the effect of female literacy rate on life expectancy differ depending on world region?
- This is the same as: Is world region is an effect modifier for female literacy rate?
Let’s run an interaction model to see!