Lesson 13: Model/Variable Selection
2025-02-24
Regression analysis process

![]()
![]()
Model Selection
Building a model
Selecting variables
Prediction vs interpretation
Comparing potential models
Model Fitting
Find best fit line
Using OLS in this class
Parameter estimation
Categorical covariates
Interactions
Model Evaluation
- Evaluation of model fit
- Testing model assumptions
- Residuals
- Transformations
- Influential points
- Multicollinearity
Model Use (Inference)
- Inference for coefficients
- Hypothesis testing for coefficients
- Inference for expected \(Y\) given \(X\)
- Prediction of new \(Y\) given \(X\)
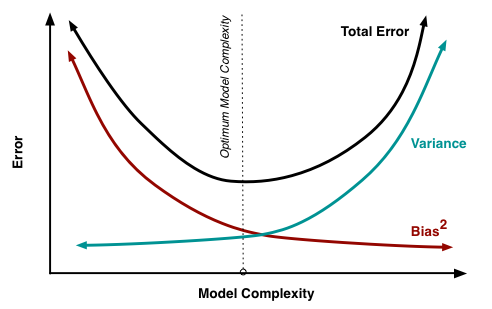
Model Complexity vs. Parsimony
Suppose we have \(p = 30\) covariates (in the true model) and n = 50 observations. We could consider the following two alternatives:
- We could fit a model using all of the covariates.
- In this case, \(\widehat\beta\) is unbiased for \(\beta\) (in a linear model fit using OLS). But \(\widehat\beta\) has very high variance.
- We could fit a model using only the five strongest covariates.
- In this case, \(\widehat\beta\) will more likely be biased for \(\beta\), but it will have lower variance (compared to the estimate including all covariates)
- Increasing the number of observations sometimes, but not always, helps with the first approach
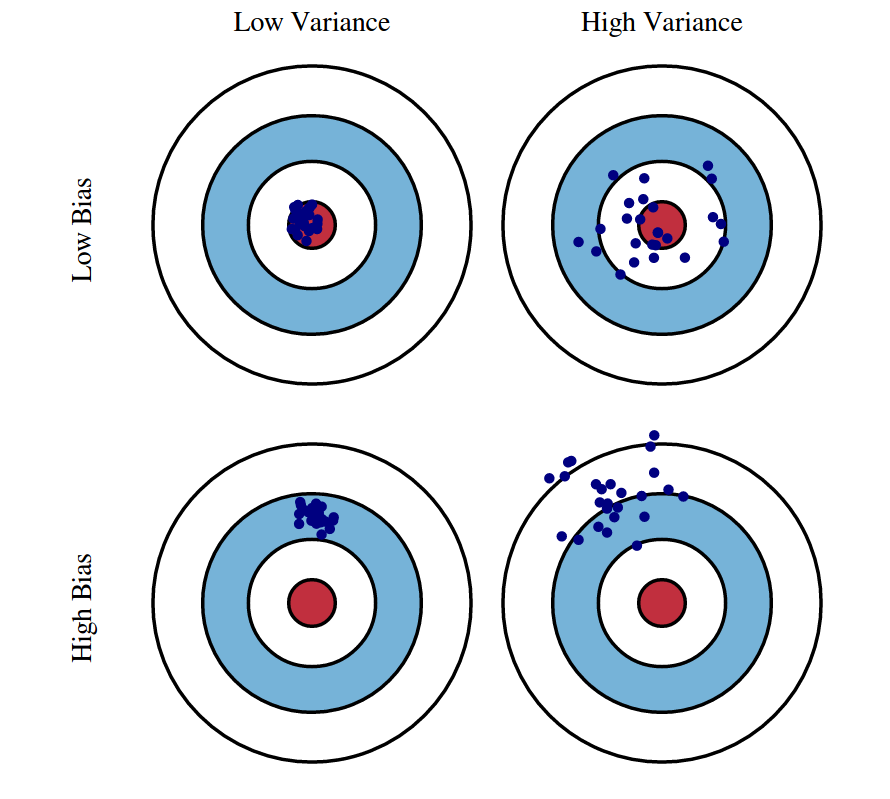
Bias-variance trade off
Recall mean square error is a function of SSE (sum of squared residuals)
\[ MSE = \dfrac{1}{n} \sum_{i=1}^{n} \big(Y_i - \widehat{Y}_i \big)^2 = \dfrac{1}{n} SSE \]
MSE can also be written as a function of the bias and variance
\[ MSE = \text{bias}\big(\widehat\beta\big)^2 + \text{variance}\big(\widehat\beta\big) \]
For the same data:
More covariates in model: less bias, more variance
Less covariates in model: more bias, less variance
Our goal: find a model with just the right amount of covariates to balance bias and vairance

Model building for association vs. prediction
More information on the two analysis goals:
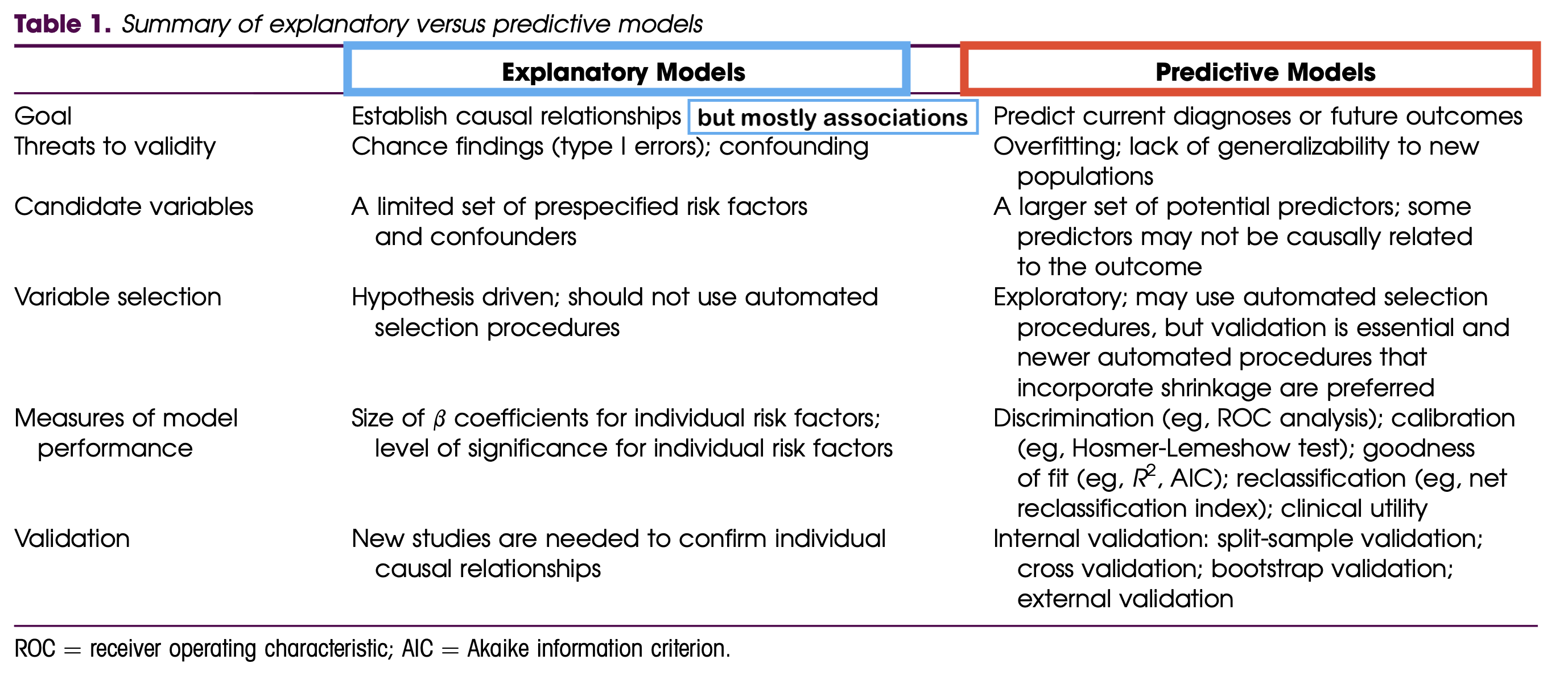
If you ever get the chance, check out Dr. Kristin Sainani’s series on Statistics
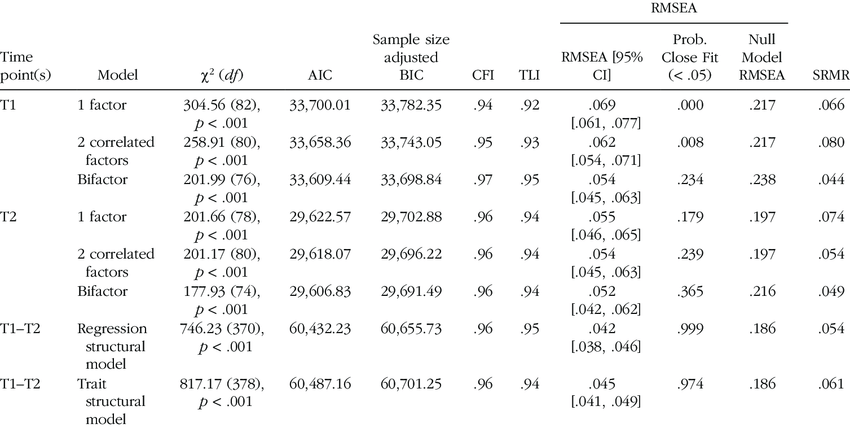
Common model fit statistics
There is no hypothesis testing for these fit statistics
Only helpful if you are comparing models
Works for nested and non-nested models
Common to report all or some of them
All of the fit statistics will not necessarily reach a consensus about the best fitting model
- Each weigh SSE, number of parameters, and number of observations differently
https://www.researchgate.net/figure/Model-Fit-Statistics_tbl1_308844501