Poster Results Help Session
2025-03-05
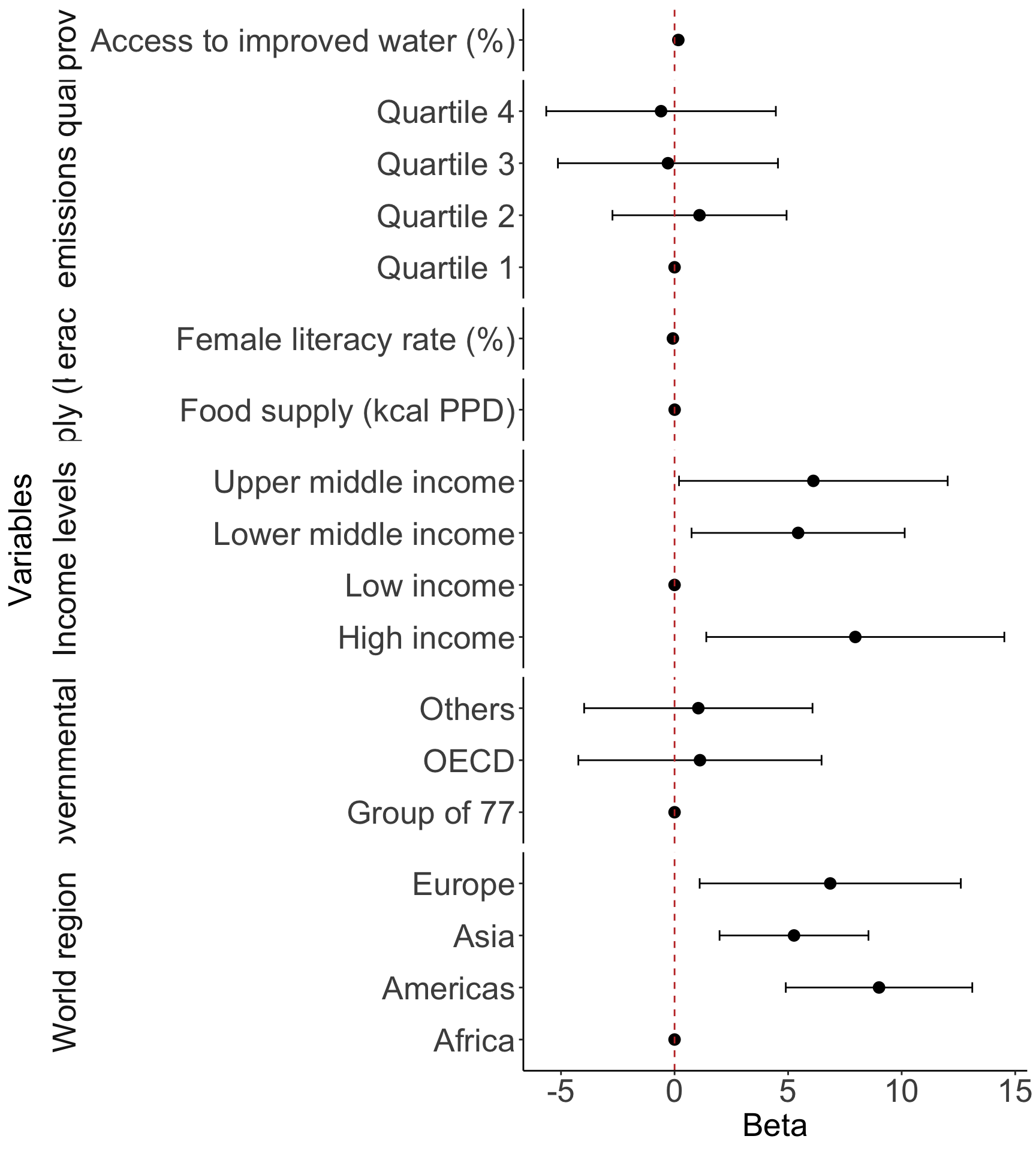
2. Regression table or Forest plot (needs work!)
- This is a fun one to investigate!
- Stick to the regression table if you are having trouble with this!
library(broom.helpers)
model_tidy = tidy_and_attach(final_model, conf.int=T) %>%
tidy_remove_intercept() %>%
tidy_add_reference_rows() %>% tidy_add_estimate_to_reference_rows() %>%
tidy_add_term_labels()
ggplot(data=model_tidy, aes(y=label, x=estimate, xmin=conf.low, xmax=conf.high)) +
facet_grid(rows = vars(var_label), scales = "free",
space='free_y', switch = "y") +
geom_point(size = 3) + geom_errorbarh(height=.2) +
geom_vline(xintercept=0, color='#C2352F', linetype='dashed', alpha=1) +
theme_classic() +
labs(x = "Beta", y = "Variables") +
theme(axis.title = element_text(size = 20), axis.text = element_text(size = 20),
title = element_text(size = 20), strip.placement = "outside",
strip.text = element_text(size = 20), strip.background = element_blank())