Lesson 16: Log-binomial Regression
2025-05-28
Logistic regression: Reporting results of GLOW Study with interactions
- Remember our main covariate is prior fracture, so we want to focuse on how age changes the relationship between prior fracture and a new fracture!
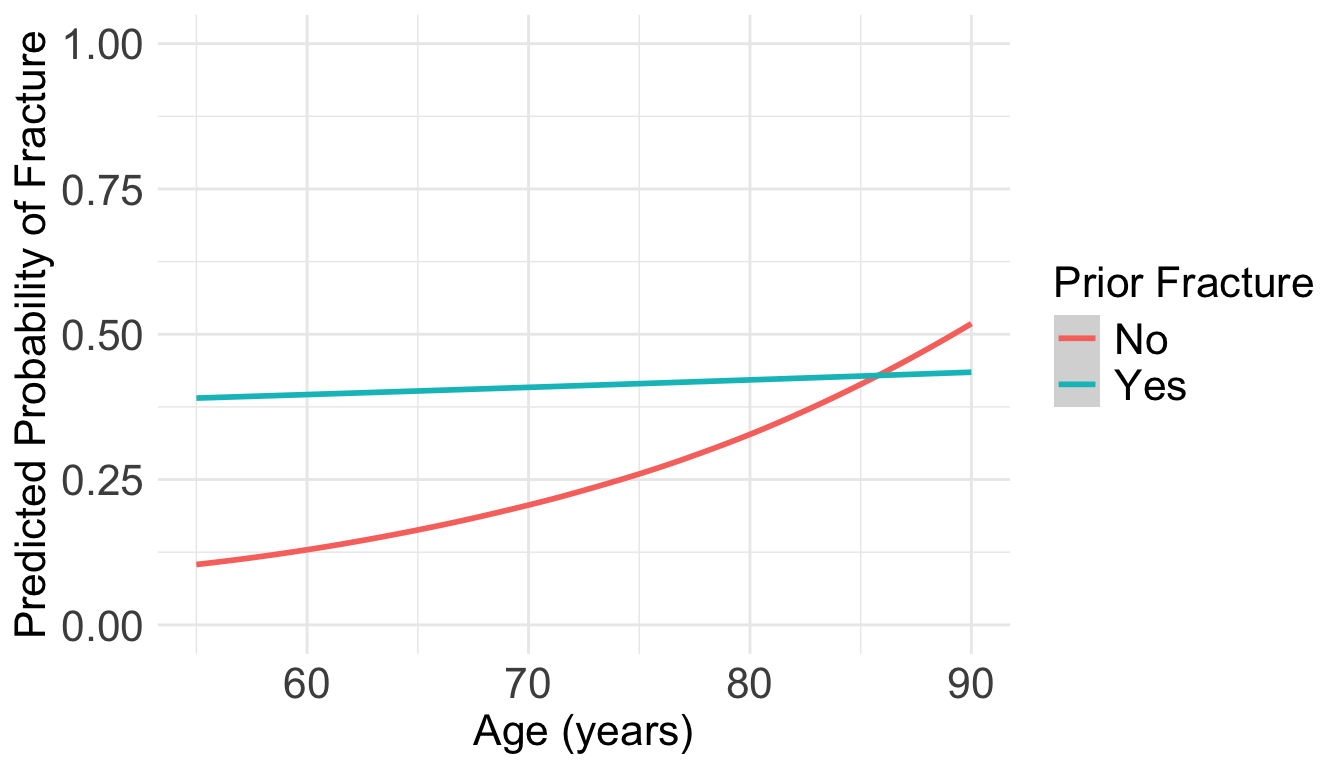
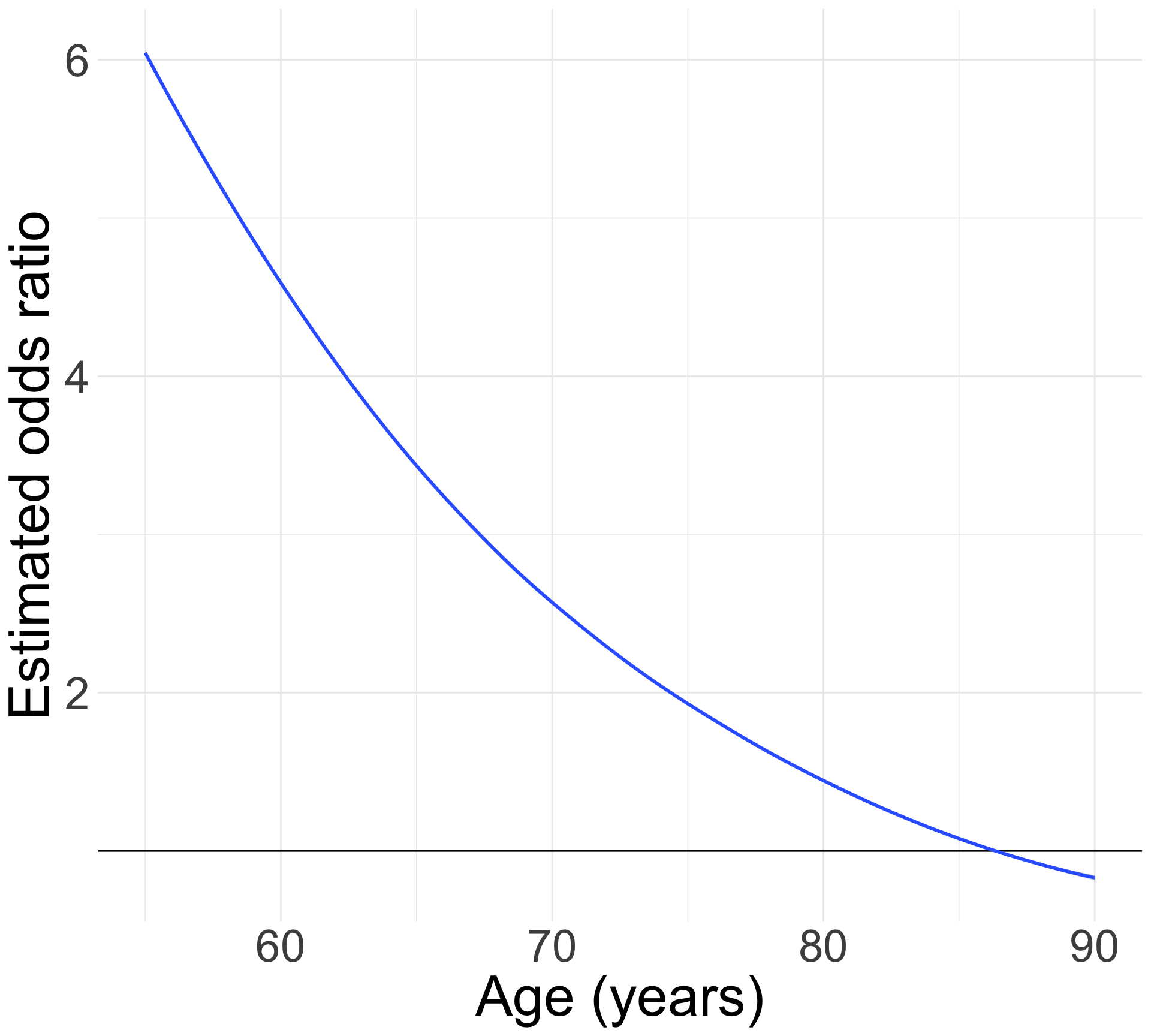
For individuals 69 years old, the estimated odds of a new fracture for individuals with prior fracture is 2.72 times the estimated odds of a new fracture for individuals with no prior fracture (95% CI: 1.70, 4.35). As seen in Figure 1 (a), the odds ratio of a new fracture when comparing prior fracture status decreases with age, indicating that the effect of prior fractures on new fractures decreases as individuals get older. In Figure 1 (b), it is evident that for both prior fracture statuses, the predict probability of a new fracture increases as age increases. However, the predicted probability of new fracture for those without a prior fracture increases at a higher rate than that of individuals with a prior fracture. Thus, the predicted probabilities of a new fracture converge at age [insert age here].
Visualization: We can look at the log-risk
- This will help us understand the model that we fit
- Ultimately, we do not need a visualization of the risk ratio because the main effects model is constant across age
Code to make the following plot
prior_age = expand_grid(priorfrac = c("No", "Yes"), age_c = (55:90)-69)
frac_pred_lb = predict(glow_main, prior_age, se.fit = F, type="link")
pred_glow_lb = prior_age %>% mutate(frac_pred = frac_pred_lb,
age = age_c + mean_age)
ggplot(pred_glow_lb) +
geom_vline(xintercept = 69) +
geom_smooth(method = "loess", aes(x = age, y = frac_pred, color = priorfrac)) +
theme(text = element_text(size=35), title = element_text(size=22)) +
labs(x = "Age (years)", y = "Estimated log-risk")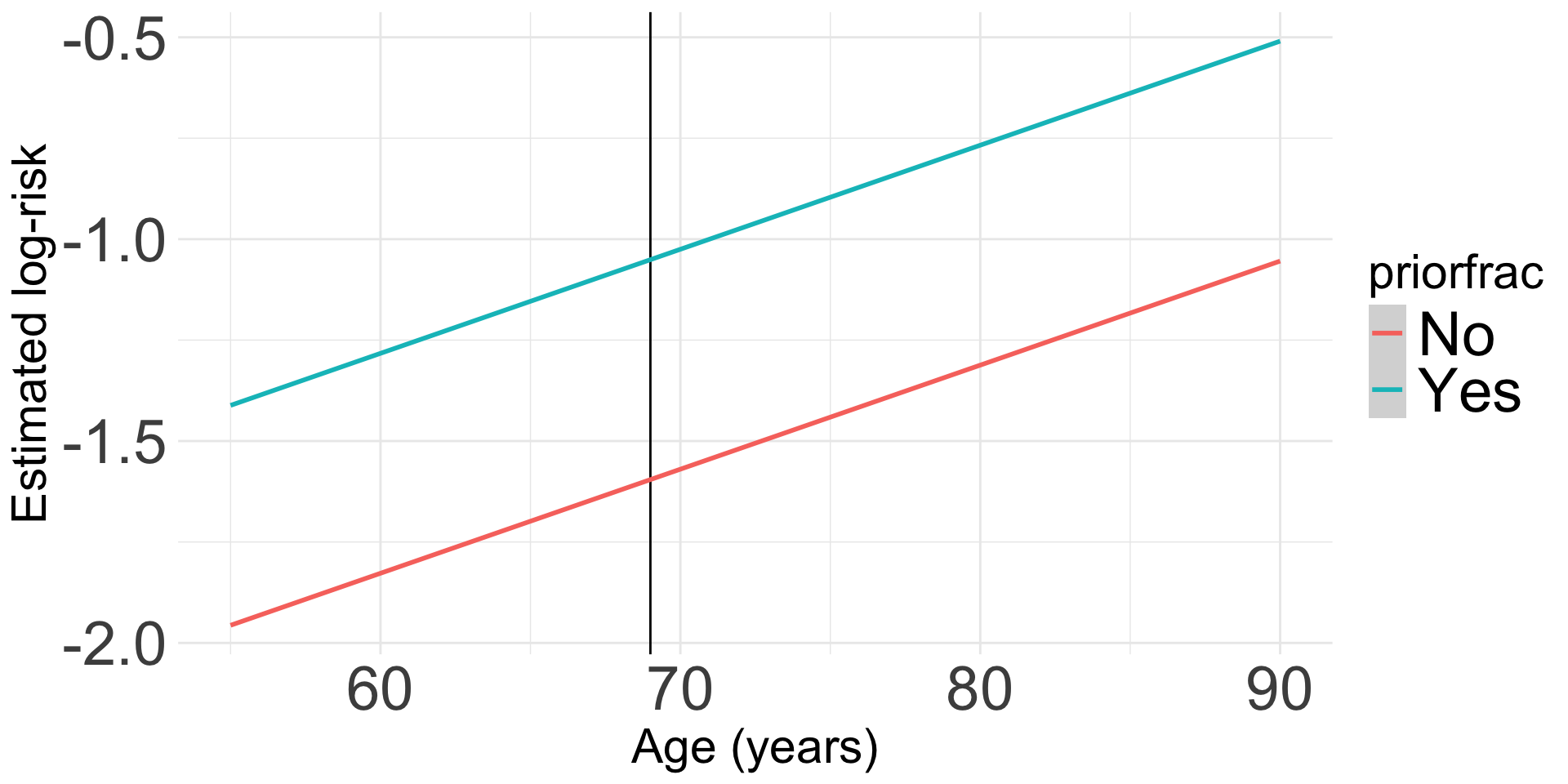
Visualization of interaction: We can look at the log-risk
- This will help us understand the model that we fit
- Ultimately, we do not need a visualization of the risk ratio because the main effects model is constant across age
Table of coefficient estimates
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | −1.596 | 0.104 | −15.414 | 0.000 |
| priorfracYes | 0.576 | 0.170 | 3.382 | 0.001 |
| age_c | 0.037 | 0.026 | 1.440 | 0.150 |
| interaction_PF_age | −0.009 | 0.017 | −0.546 | 0.585 |
Code to make the following plot
prior_age = expand_grid(priorfrac = c("No", "Yes"), age_c = (55:90)-69) %>%
mutate(interaction_PF_age = ifelse(priorfrac=="Yes", 1, 0)*age_c)
frac_pred_lb = predict(glow2_log_binom, prior_age, se.fit = F, type="link")
pred_glow_lb = prior_age %>% mutate(frac_pred = frac_pred_lb,
age = age_c + mean_age)
ggplot(pred_glow_lb) +
geom_vline(xintercept = 69) +
geom_smooth(method = "loess", aes(x = age, y = frac_pred, color = priorfrac)) +
theme(text = element_text(size=35), title = element_text(size=22)) +
labs(x = "Age (years)", y = "Estimated log-risk")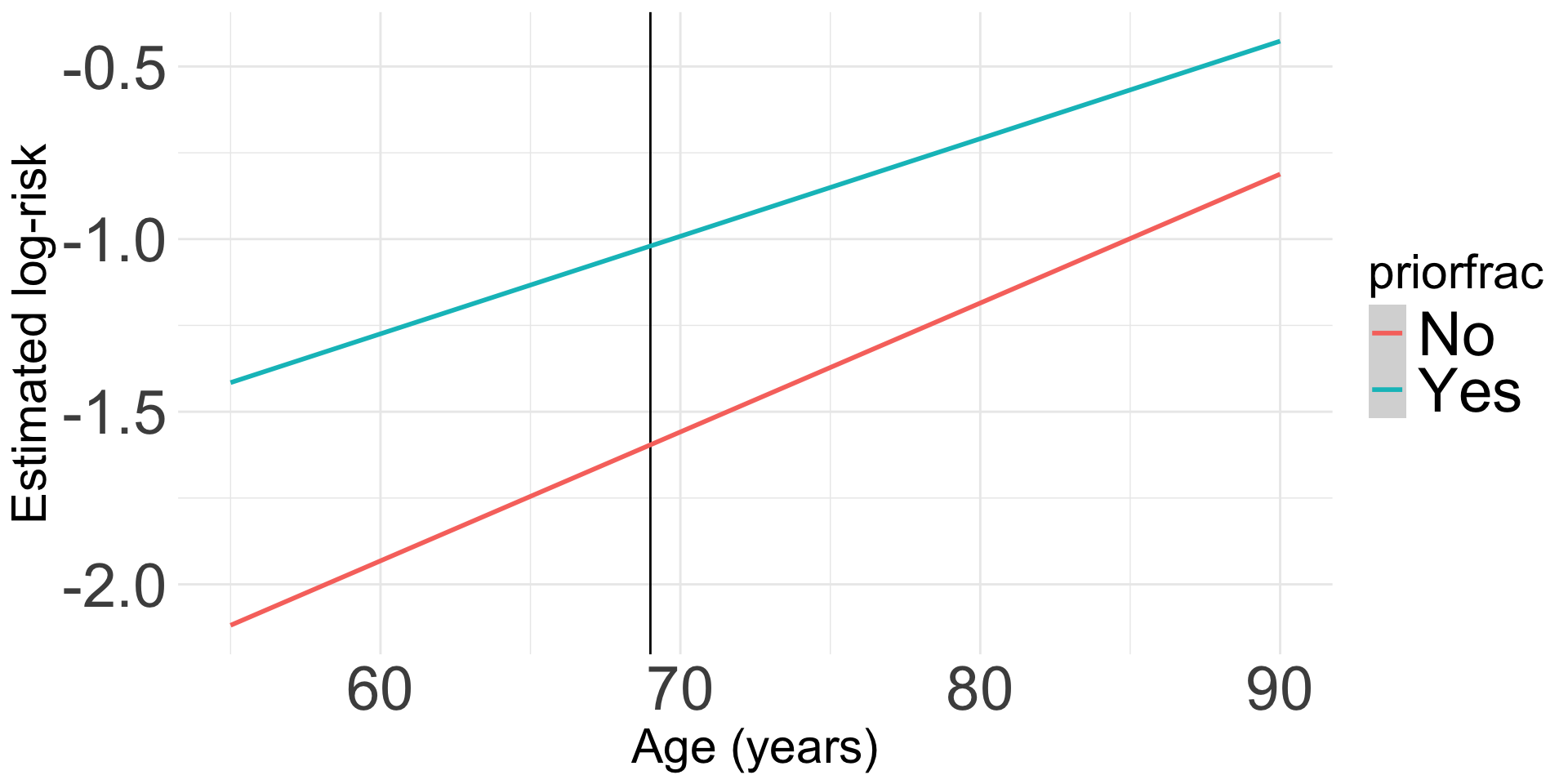
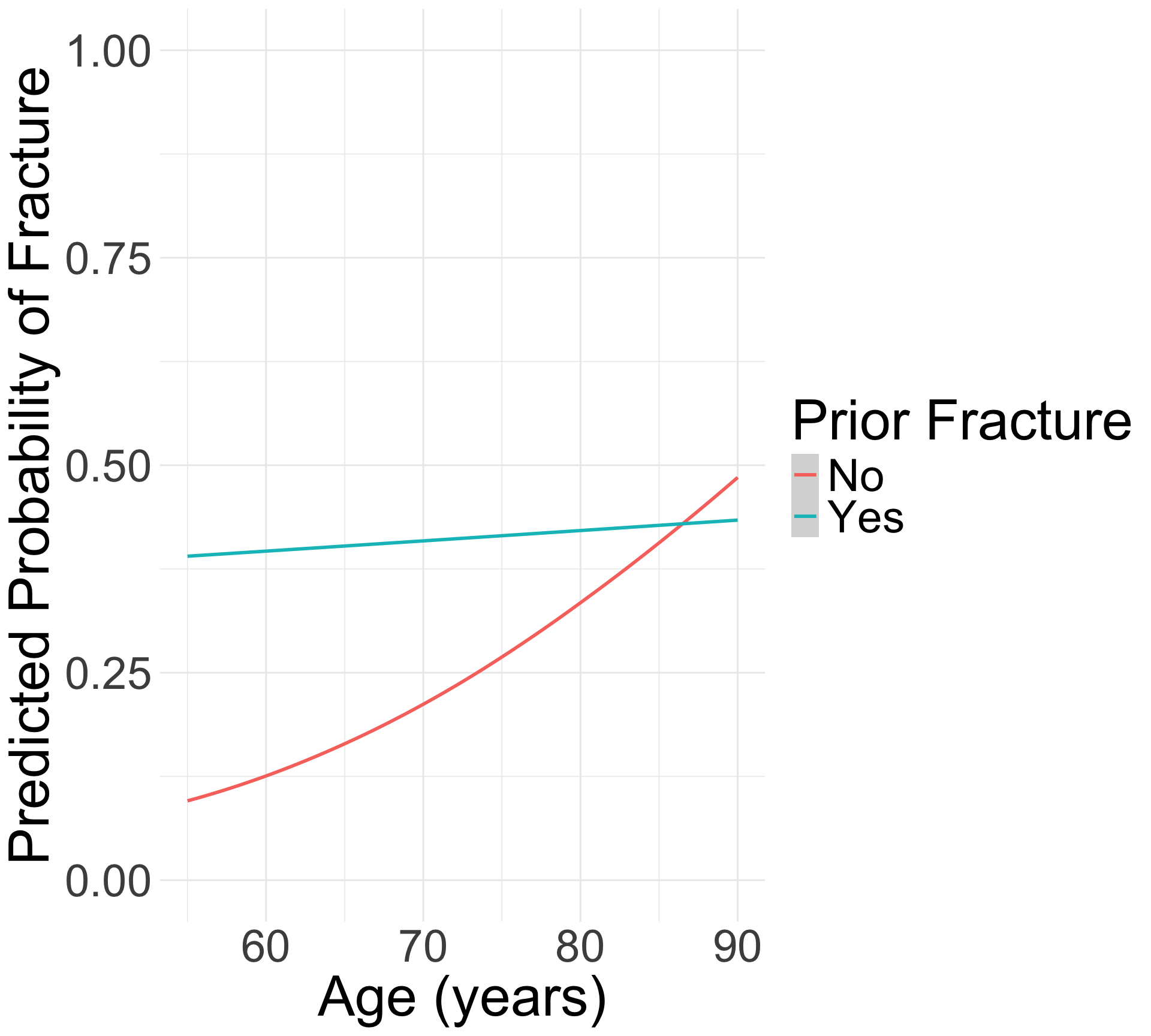
Predicted probabilities and visualizations
- Does this look familiar?? It should!
- The predicted probabilities from the logistic regression and the log-binomial regression should be the same!
Code to make the following plot
prior_age = expand_grid(priorfrac = c("No", "Yes"), age_c = (55:90)-69)
frac_pred_lb = predict(glow_log_binom, prior_age, se.fit = T, type="response")
pred_glow_lb = prior_age %>% mutate(frac_pred = frac_pred_lb$fit,
age = age_c + mean_age)
ggplot(pred_glow_lb) + #geom_point(aes(x = age, y = frac_pred, color = priorfrac)) +
geom_smooth(method = "loess", aes(x = age, y = frac_pred, color = priorfrac)) +
theme(text = element_text(size=20), title = element_text(size=16)) + ylim(0,1) +
labs(color = "Prior Fracture", x = "Age (years)", y = "Predicted Probability of Fracture")