Lesson 9: Variability in estimates
TB sections 4.1
2024-10-30

Where are we?
Population

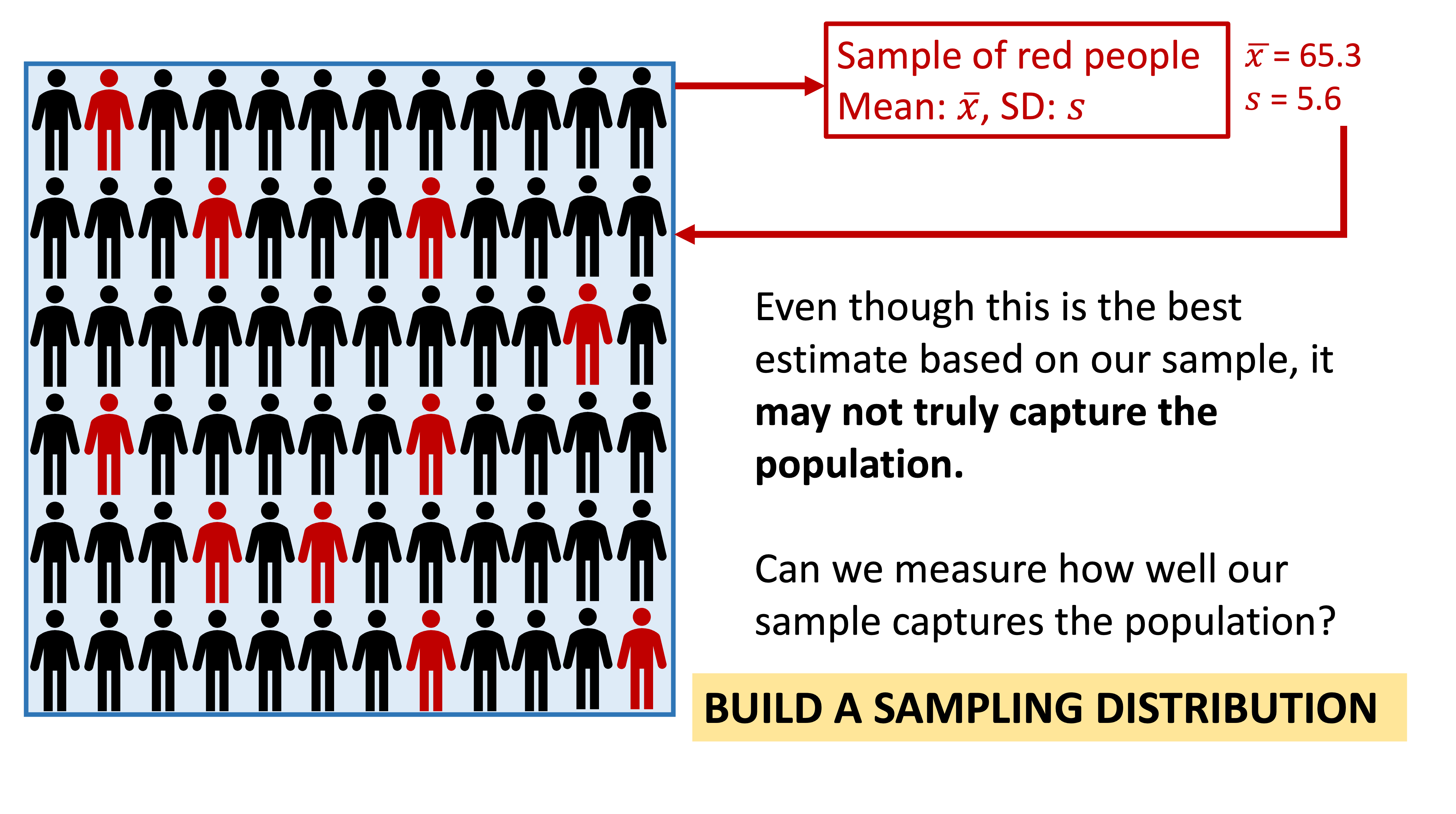
Take one sample
Take one sample
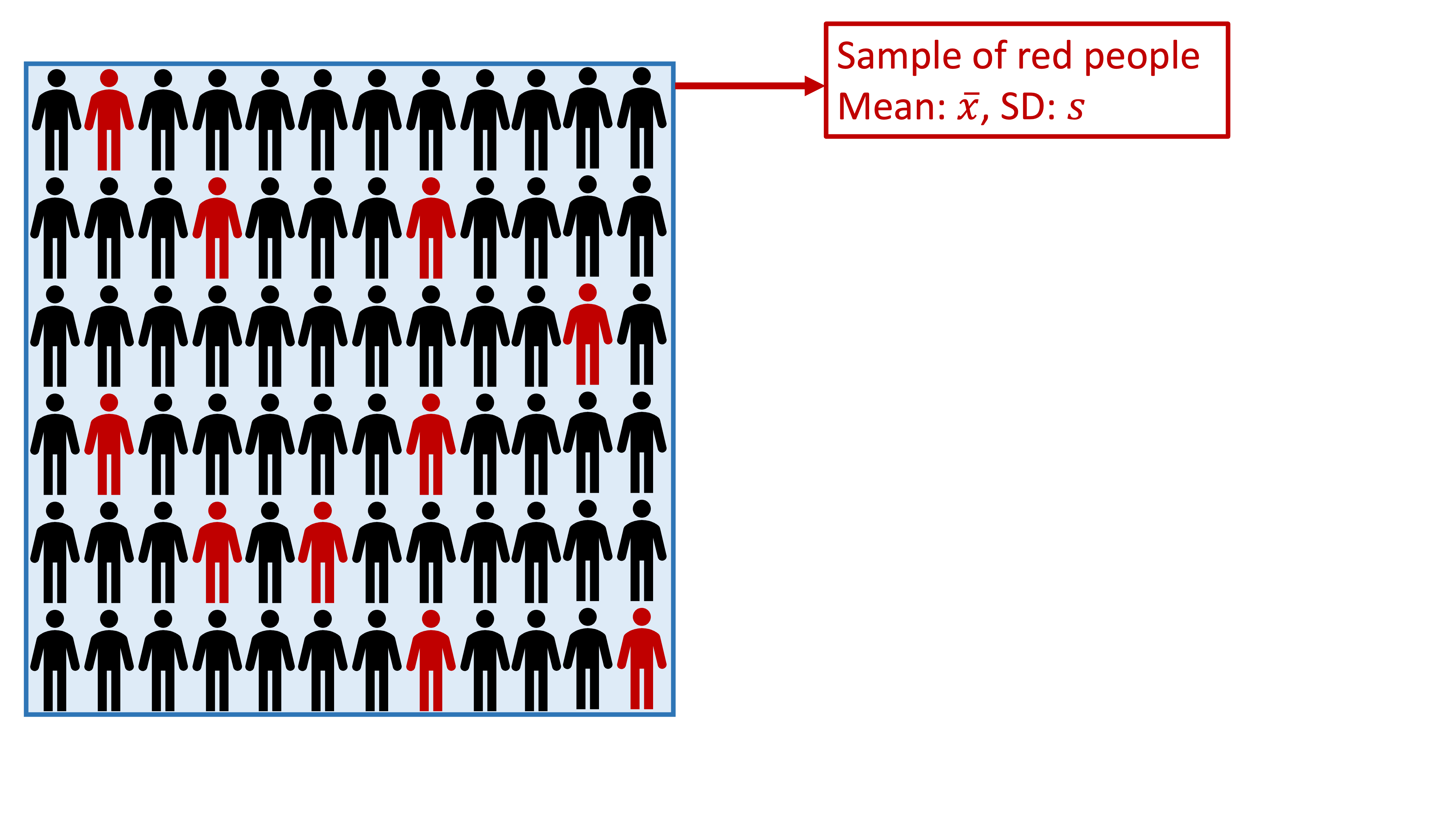
Take one sample
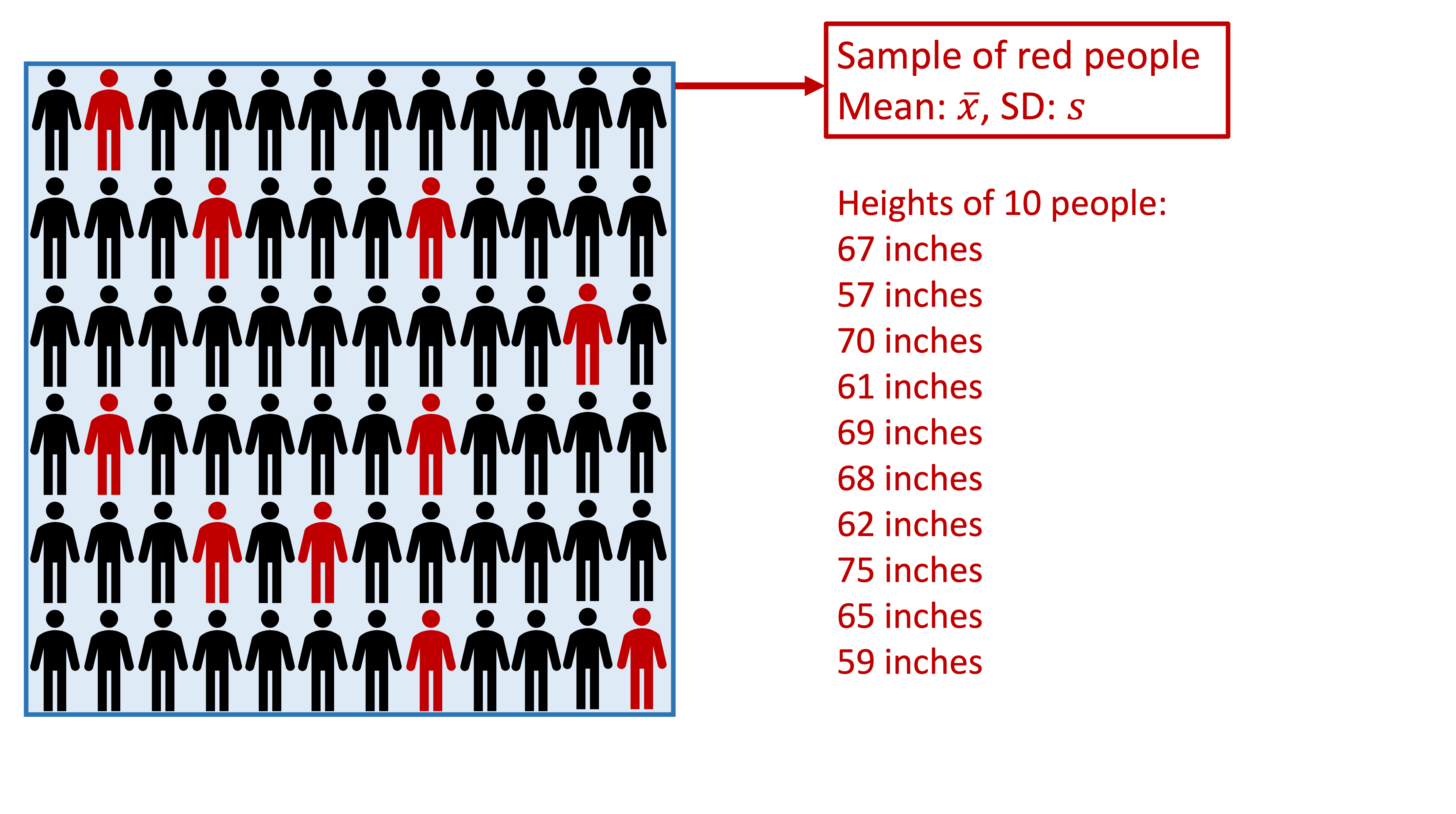
Take one sample
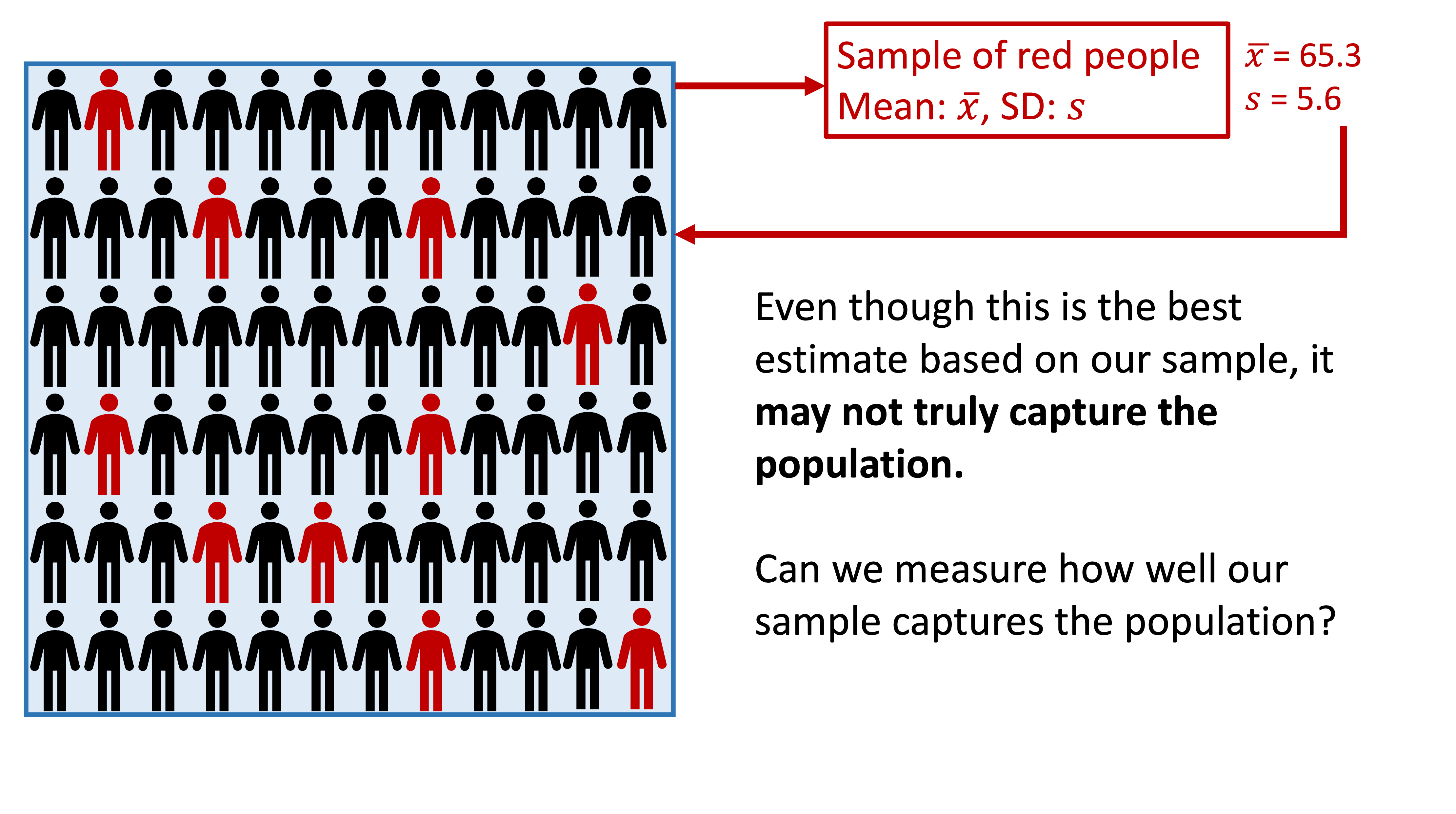
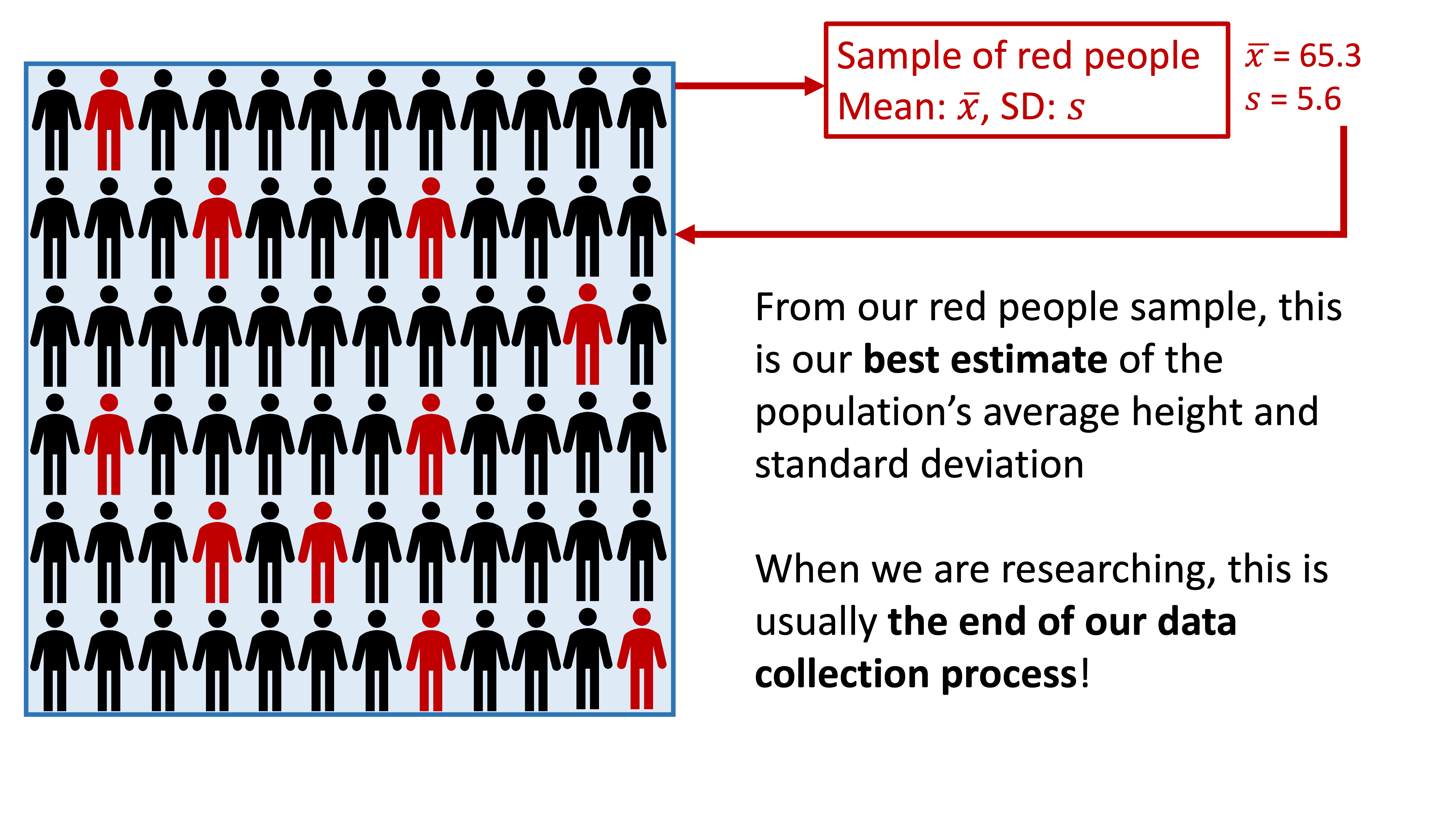
Take one sample
Take another sample
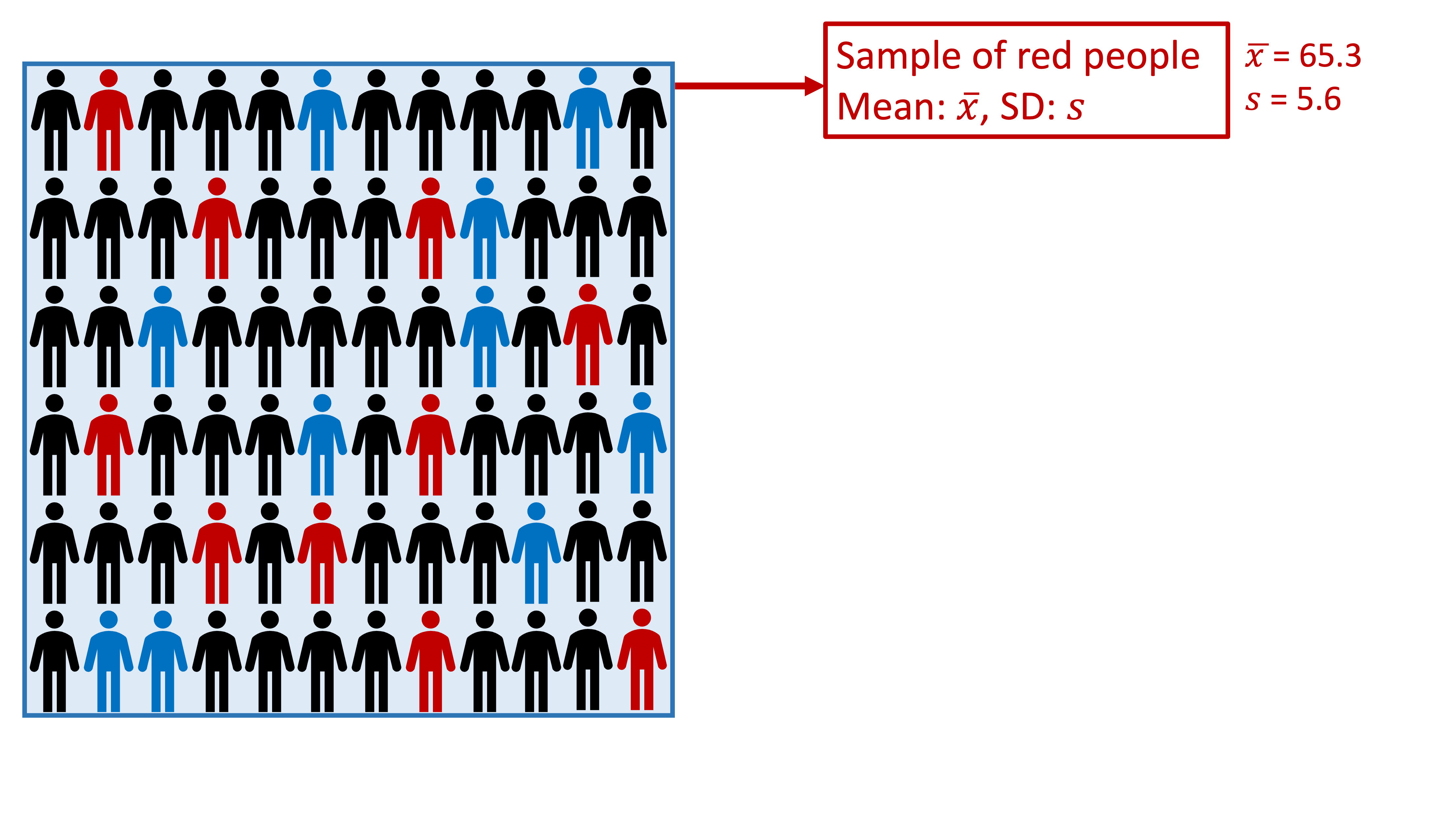
Take another sample
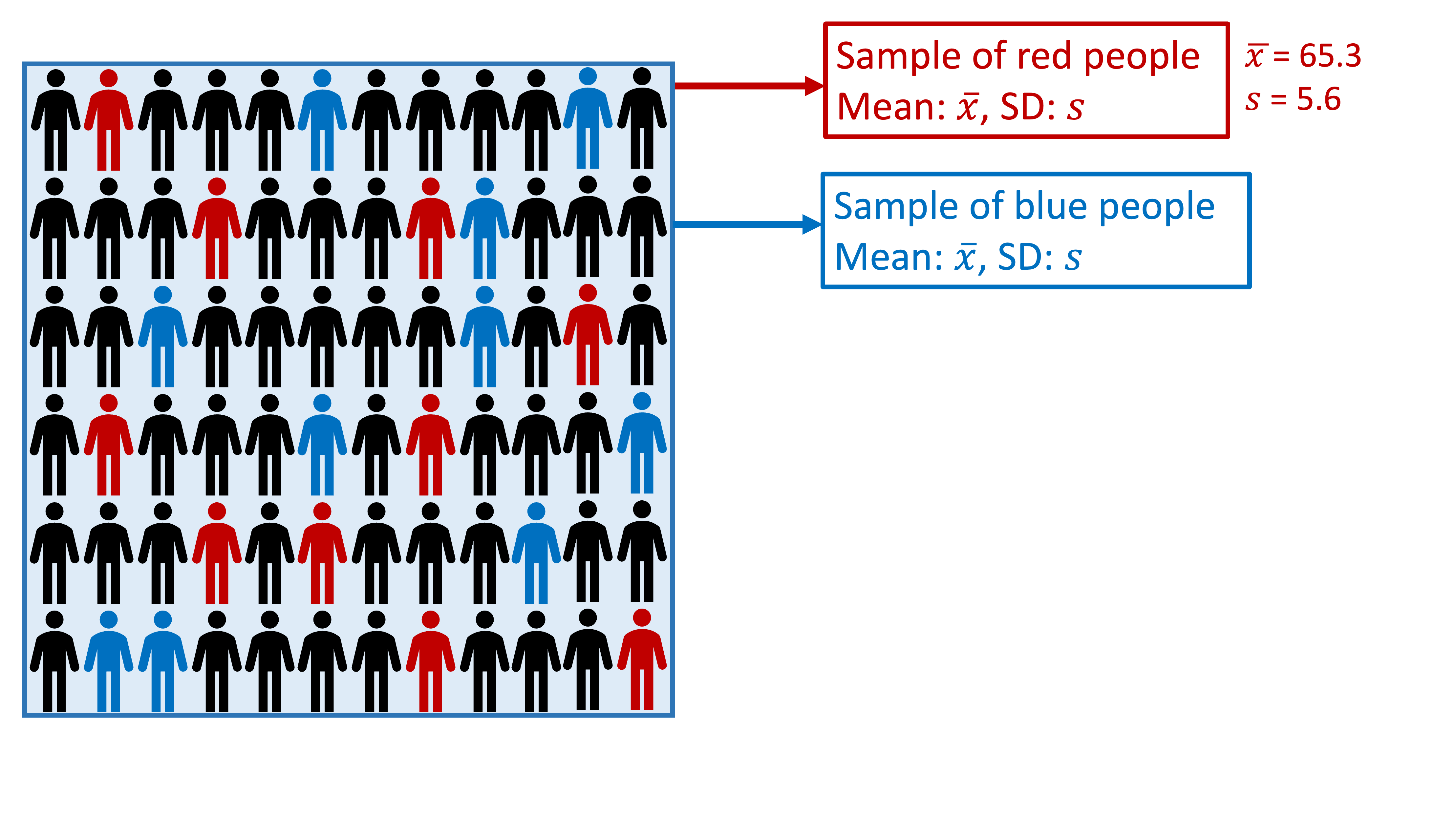
Take another sample
Take another sample
Take several samples
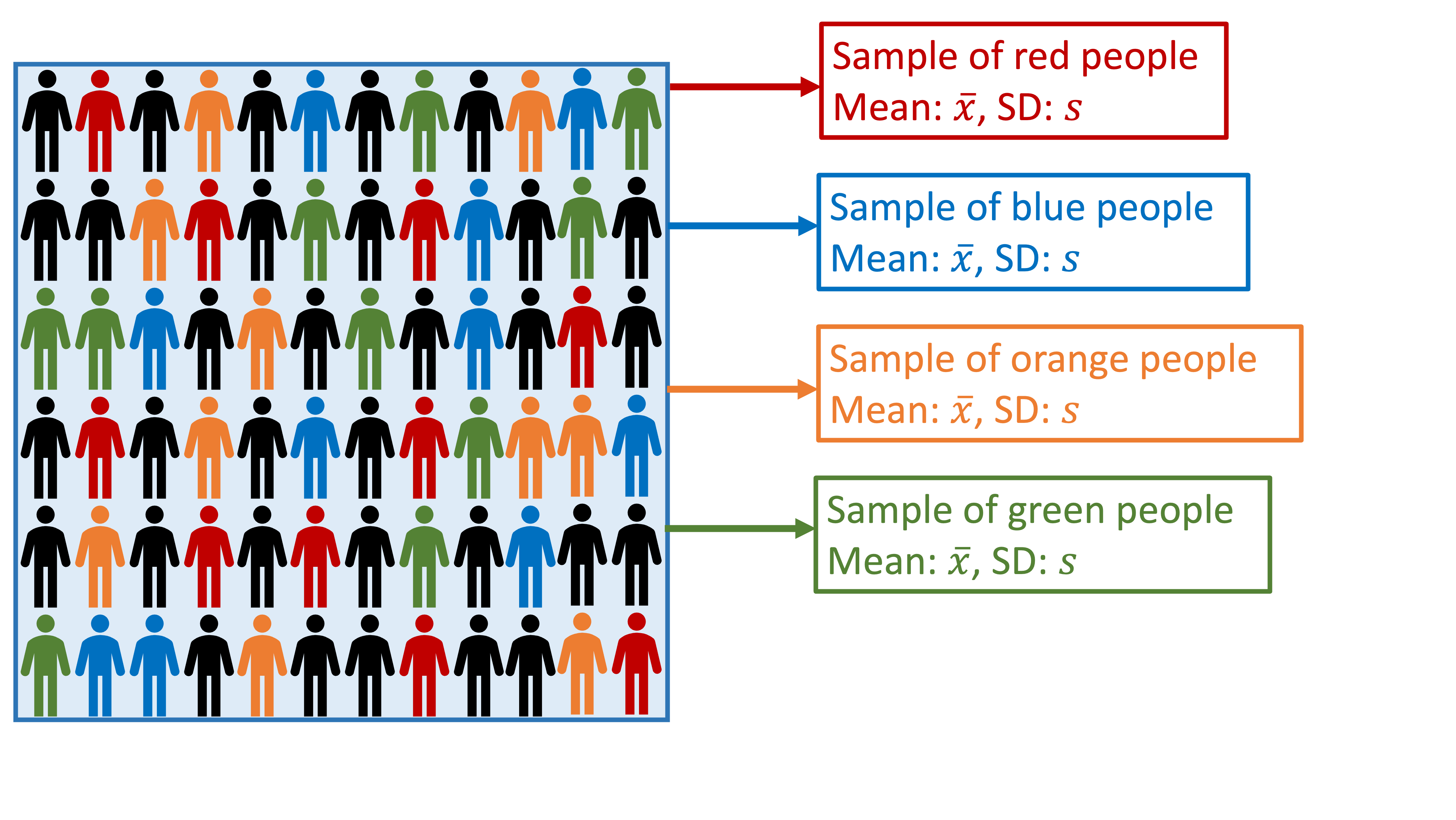
Difference between samples?

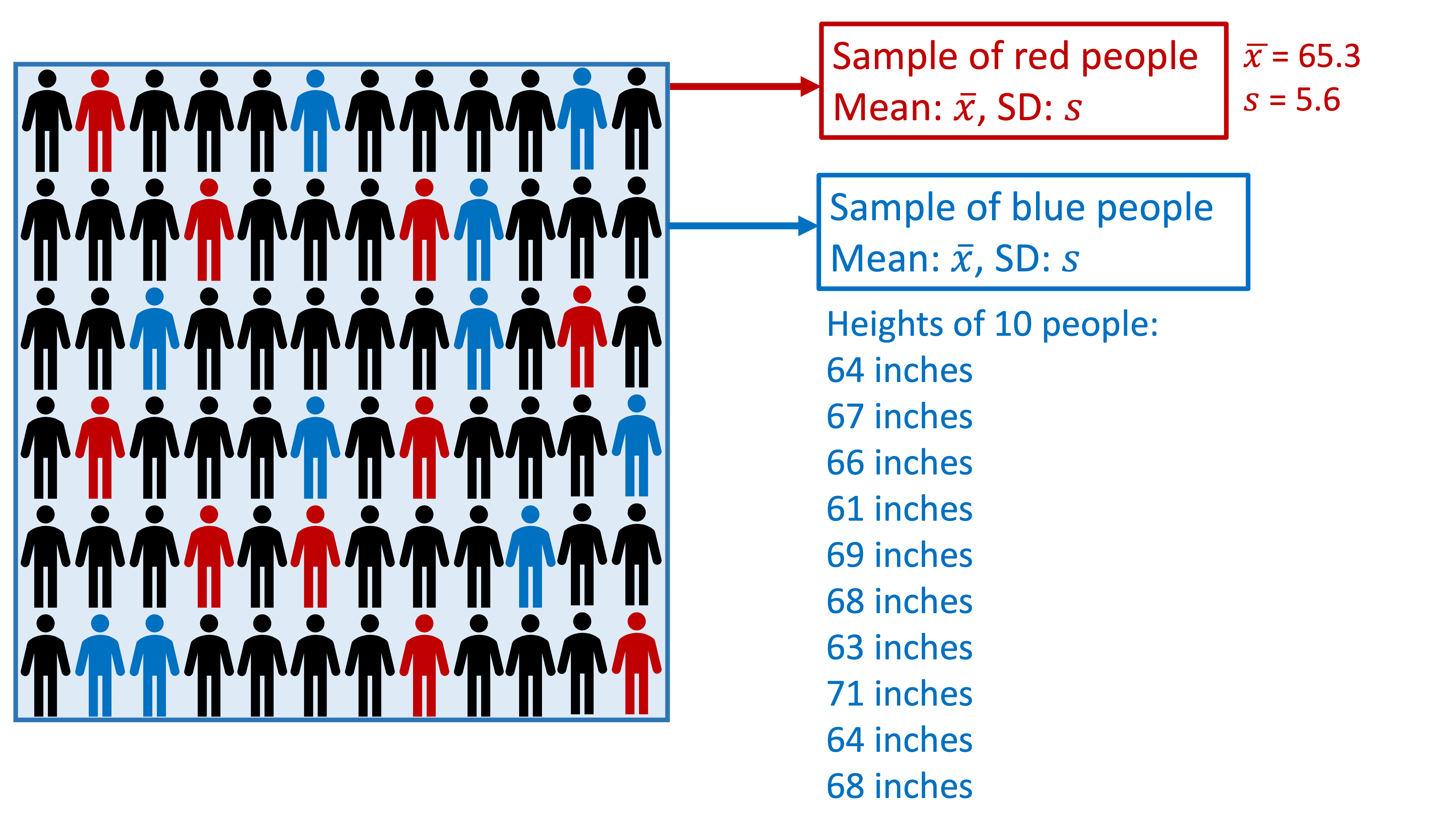
More concrete example with height (1/3)
Variation in population (\(\sigma\)):

\[ \mu = 65 \text{ inches}\] \[ \sigma = 3 \text{ inches}\]
More concrete example with height (2/3)
Variation in population (\(\sigma\)):

\[ \mu = 65 \text{ inches}\] \[ \sigma = 3 \text{ inches}\]
Variation within samples (\(s\)):

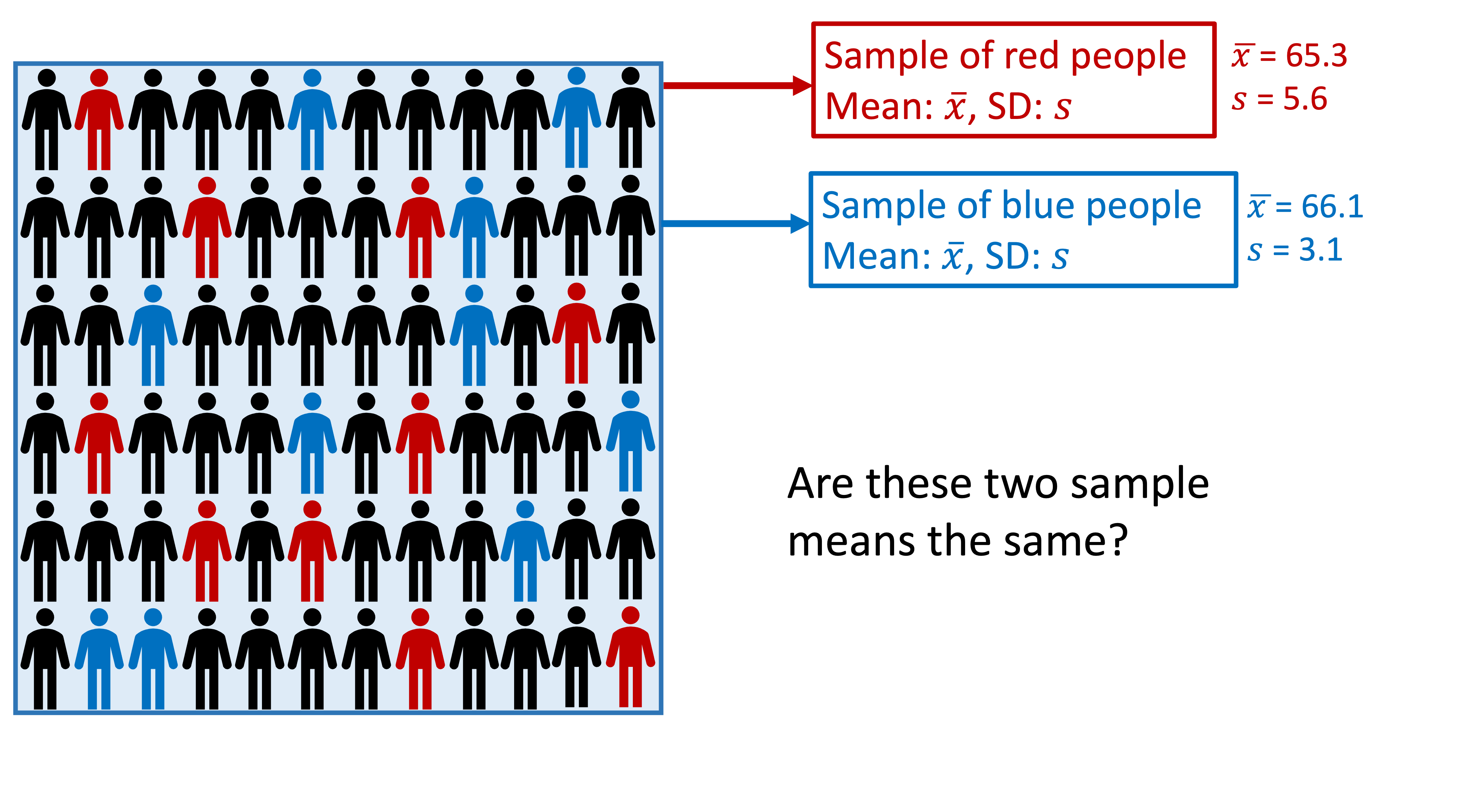
More concrete example with height (3/3)
Variation in population (\(\sigma\)):

\[ \mu = 65 \text{ inches}\] \[ \sigma = 3 \text{ inches}\]
Variation within samples (\(s\)):
Variation between samples (\(SE\)):

\[ \mu_{\overline{X}} = 65.002 \text{ inches}\] \[ SE = 0.421 \text{ inches}\]
Sampling Distribution of Sample Means
The sampling distribution is the distribution of sample means calculated from repeated random samples of the same size from the same population
It is useful to think of a particular sample statistic as being drawn from a sampling distribution
- So the red sample with \(\overline{x} = 65.1\) is just one sample mean in the sampling distribution
Variation between samples (\(SE\)):

\[ \mu_{\overline{X}} = 65.002 \text{ inches}\] \[ SE = 0.421 \text{ inches}\]
For following Poll Everywhere Question
How are the center, shape, and spread similar and/or different?


Sampling Distribution of Sample Means (with the CLT)
The sampling distribution is the distribution of sample means calculated from repeated random samples of the same size from the same population
It is useful to think of a particular sample statistic as being drawn from a sampling distribution
- So the red sample with \(\overline{x} = 65.1\) is just one sample mean in the sampling distribution
With CLT and \(\overline{X}\) as the RV for the sampling distribution
- Theoretically (using only population values): \(\overline{X} \sim \text{Normal} \big(\mu_{\overline{X}} = \mu, \sigma_{\overline{X}}= SE = \frac{\sigma}{\sqrt{n}} \big)\)
- In real use (using sample values for SE): \(\overline{X} \sim \text{Normal} \big(\mu_{\overline{X}} = \mu, \sigma_{\overline{X}}= SE = \frac{s}{\sqrt{n}} \big)\)
Variation between samples (\(SE\)):

\[ \mu_{\overline{X}} = 64.996 \text{ inches}\] \[ SE = 0.291 \text{ inches}\]
Let’s apply the CLT to our sampling distribution when n = 50 (1/2)
CLT tells us that we can model the sampling distribution of mean heights using a normal distribution:


Let’s apply the CLT to our sampling distribution when n = 50 (2/2)
Mean and SD of population: \[ \mu = 65 \text{ inches} \text{, } \sigma = 3 \text{ inches}\]
From the CLT, we can figure out the theoretical mean and standard deviation of our sampling distribution:
\[ \mu = 65 \text{ inches}\] \[ SE = \frac{\sigma}{\sqrt{n}} \text{ inches} = \frac{3}{\sqrt{50}} \text{ inches} = 0.424 \text{ inches}\]
I simulated the data, so I can calculate mean and SE of the sampling distribution:

Applying the CLT (2/2)
Example 1
For a random sample of 100 people, what is the probability that their mean height is greater than 65 inches? We happen to know the population mean is 64 inches and population standard deviation is 4 inches.
- Calculate the probability from a Normal distribution: \(P(H \geq 65)\)

Check out this video explanation of CLT
- Bunnies, Dragons and the ‘Normal’ World: Central Limit Theorem
- Creature Cast from the New York Times
- https://www.youtube.com/watch?v=jvoxEYmQHNM&feature=youtu.be
