Lesson 10: Confidence intervals
TB sections 4.2
2024-11-04
Where are we?
Last time: Central Limit Theorem applied to sampling distribution
- CLT tells us that we can model the sampling distribution of mean heights using a normal distribution

\[\overline{X} \sim \text{Normal}\big(\mu_{\overline{X}}=65, SE = 0.424 \big)\]
Last time: Sampling Distribution of Sample Means (with the CLT)
The sampling distribution is the distribution of sample means calculated from repeated random samples of the same size from the same population
It is useful to think of a particular sample statistic as being drawn from a sampling distribution
- So the red sample with \(\overline{x} = 65.1\) is just one sample mean in the sampling distribution
With CLT and \(\overline{X}\) as the RV for the sampling distribution
- Theoretically (using only population values): \(\overline{X} \sim \text{Normal} \big(\mu_{\overline{X}} = \mu, \sigma_{\overline{X}}= SE = \frac{\sigma}{\sqrt{n}} \big)\)
- In real use (using sample values for SE): \(\overline{X} \sim \text{Normal} \big(\mu_{\overline{X}} = \mu, \sigma_{\overline{X}}= SE = \frac{s}{\sqrt{n}} \big)\)

\[ \mu_{\overline{X}} = 65 \text{ inches}\] \[ SE = 0.424 \text{ inches}\]
Last time: point estimates


Point estimates with their confidence intervals for \(\mu\)


Do these confidence intervals include \(\mu\)?
How do we interpret confidence intervals? (1/2)
Simulating Confidence Intervals: http://www.rossmanchance.com/applets/ConfSim.html
The figure shows CI’s from 100 simulations:
- The true value of \(\mu =65\) is the vertical black line
- The horizontal lines are 95% CI’s from 100 samples
- Blue: the CI “captured” the true value of \(\mu\)
- Red: the CI did not “capture” the true value of \(\mu\)
What percent of CI’s captured the true value of \(\mu\)?

What if we don’t know \(\sigma\) ? (1/2)
Simulating Confidence Intervals: http://www.rossmanchance.com/applets/ConfSim.html
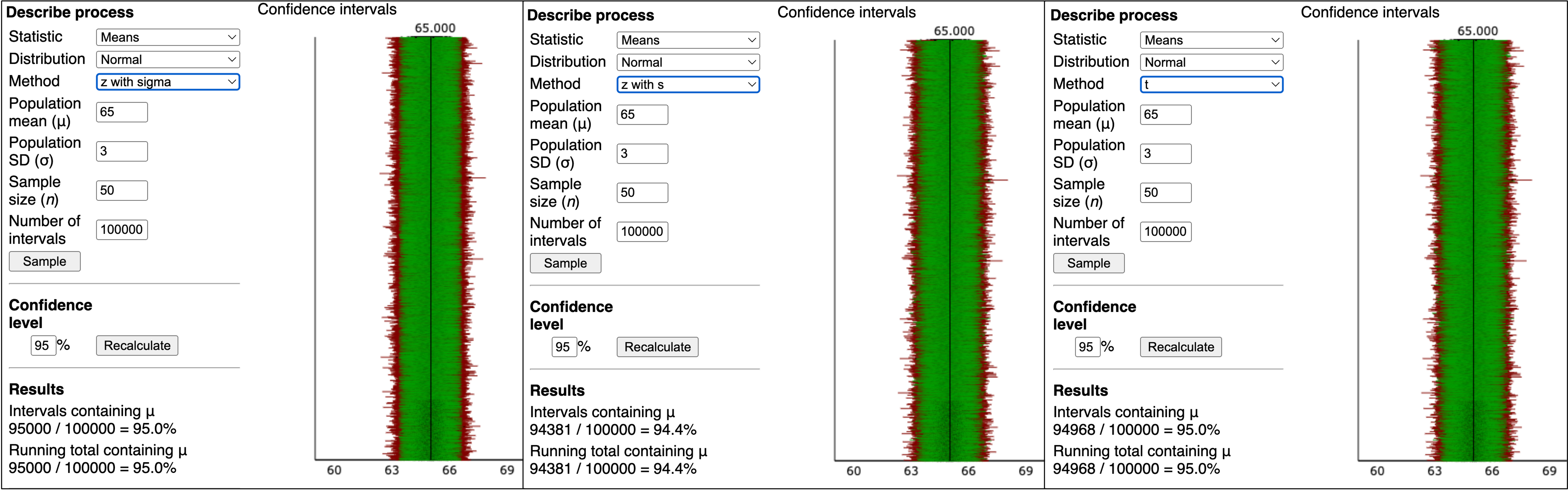
- The normal distribution doesn’t have a 95% “coverage rate” when using \(s\) instead of \(\sigma\)
- There’s another distribution, called the t-distribution, that does have a 95% “coverage rate” when we use \(s\)
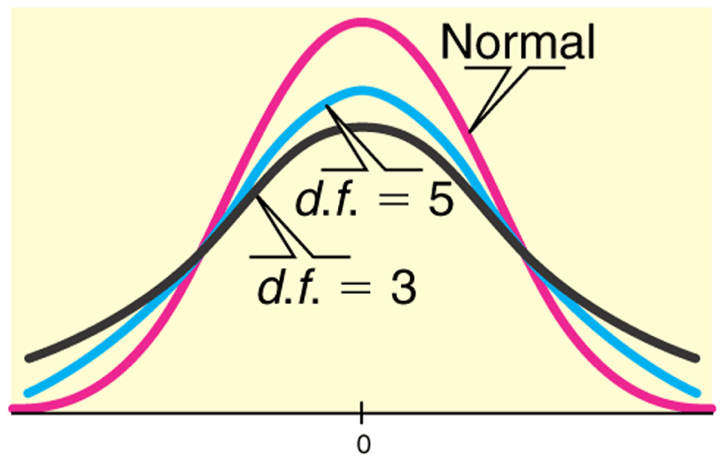
Student’s t-distribution
- Is bell shaped and symmetric
- A “generalized” version of the normal distribution
- Its tails are a thicker than that of a normal distribution
- The “thickness” depends on its degrees of freedom: \(df = n–1\) , where n = sample size
- As the degrees of freedom (sample size) increase,
- the tails are less thick, and
- the t-distribution is more like a normal distribution
- in theory, with an infinite sample size the t-distribution is a normal distribution.