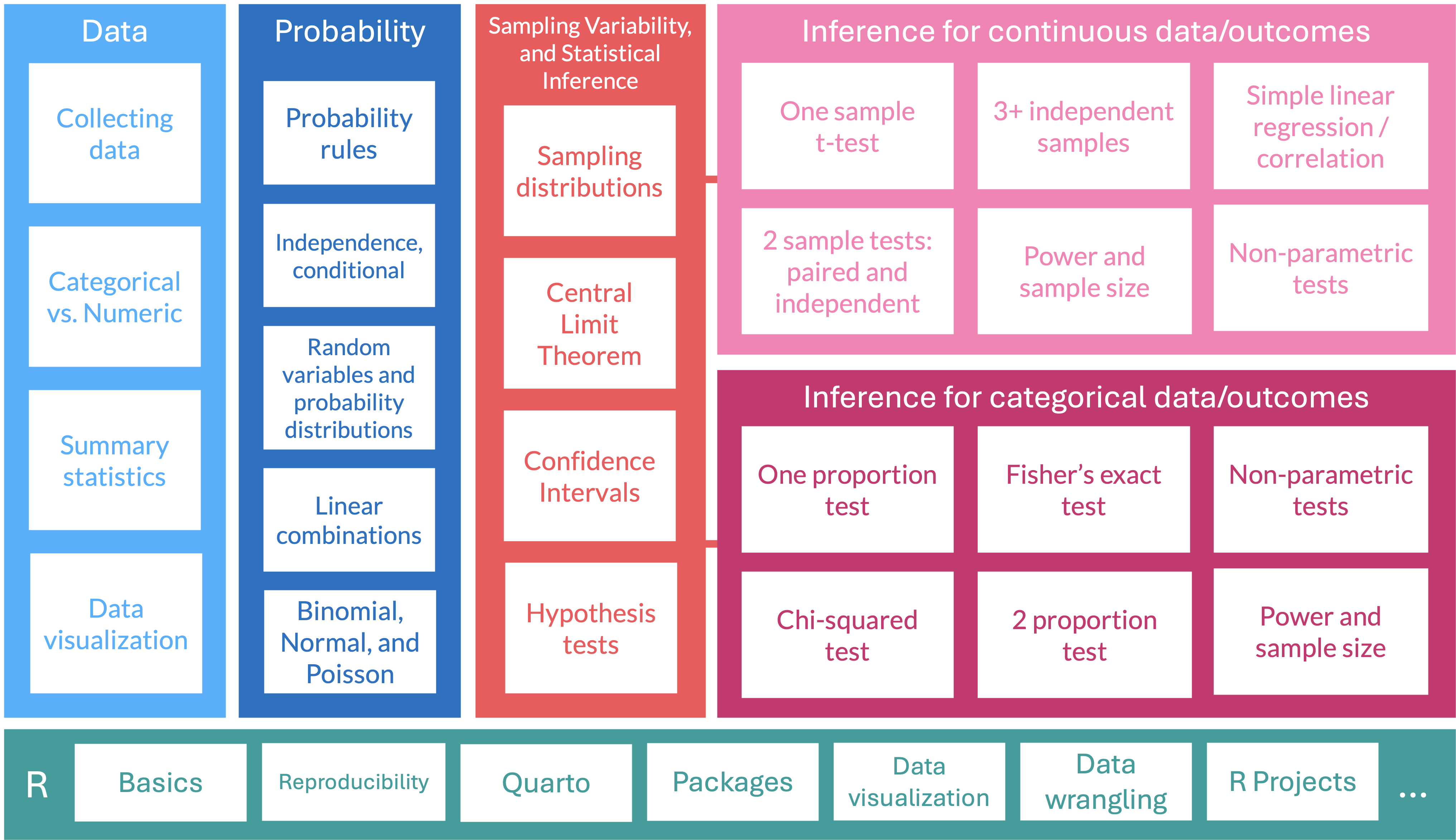



TB sections 5.2
2024-11-11
Inference for a single-sample mean includes:
Single-sample mean:
Single-sample mean:



Paired mean difference:



Calculate CI for the mean difference \(\delta\):

\[\overline{x}_d \pm t^*\cdot\frac{s_d}{\sqrt{n}}\]
Run a hypothesis test:

Hypotheses
\[\begin{align} H_0:& \delta = \delta_0 \\ H_A:& \delta \neq \delta_0 \\ (or&~ <, >) \end{align}\]
Test statistic
\[ t_{\overline{x}_d} = \frac{\overline{x}_d - \delta_0}{\frac{s_d}{\sqrt{n}}} \]
From our example: Recall that \(\overline{x}_d = -21.767\), \(s_d=13.89\), and \(n=43\)
The test statistic is:
\[ t_{\overline{x}_d} = \frac{\overline{x}_d - \delta_0}{\frac{s_d}{\sqrt{n}}} = \frac{-21.767 - 0}{\frac{13.89}{\sqrt{43}}} = -10.276 \]
The p-value is the probability of obtaining a test statistic just as extreme or more extreme than the observed test statistic assuming the null hypothesis \(H_0\) is true.





