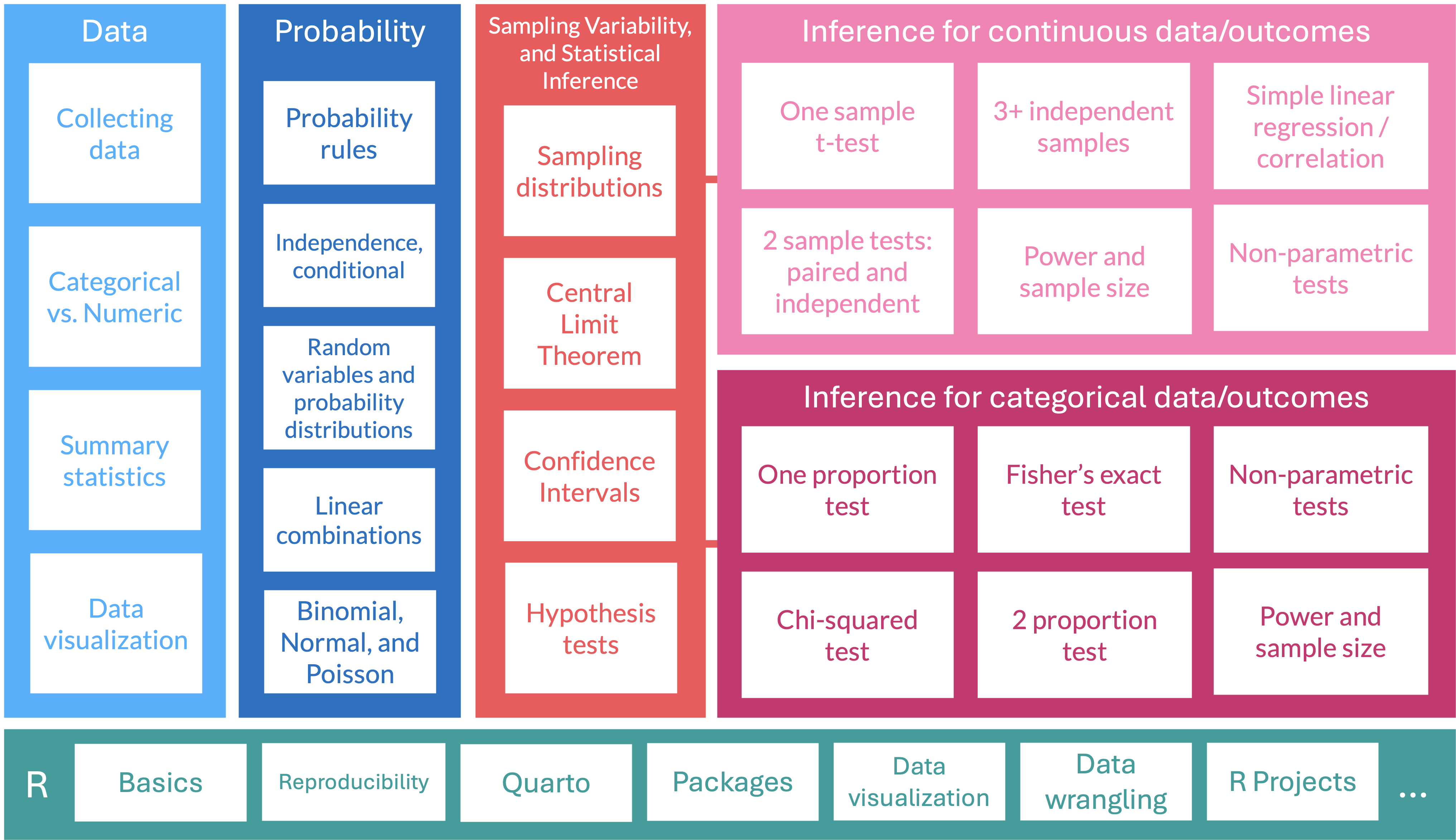
Lesson 14: Power and sample size calculations for means
TB sections 5.4
2024-11-20
Where are we?
We started looking at the taps/min for each group

What if the following were the true population distributions? Case 1
- Difference in population means is 5
- Both have a standard deviation of 2

- When we take two samples from these groups, do you think it would be easy to distinguish between the mean taps/min?
- Depends on the number of samples we get: we might need a lot
What if the following were the true population distributions? Case 2
- Difference in population means is 5
- Both have a standard deviation of 1

- When we take two samples from these groups, do you think it would be easy to distinguish between the mean taps/min?
- Seems easier to distinguish here. How did the standard deviation decrease?
What if the following were the true population distributions? Case 3
- Difference in population means is 10
- Both have a standard deviation of 2

- When we take two samples from these groups, do you think it would be easy to distinguish between the mean taps/min?
- Also seems easier to distinguish here
Significance levels and critical values
- Critical values are the cutoff values that determine whether a test statistic is statistically significant or not
- Determined by the significance level
- If a test statistic is greater in absolute value than the critical value, we reject \(H_0\)

- Critical values are determined by
- the significance level \(\alpha\),
- whether a test is 1- or 2-sided, &
- the probability distribution being used to calculate the p-value (such as normal or t-distribution)
- We have been referring to critical values from the t-distribution as \(t^*\)
- See how we calculate a specific confidence interval in Lesson 10
Rejection region, significance levels, and critical values
- If the absolute value of the test statistic is greater than the critical value, we reject \(H_0\)
- In this case the test statistic is in the rejection region.
- Otherwise it’s in the non-rejection region.
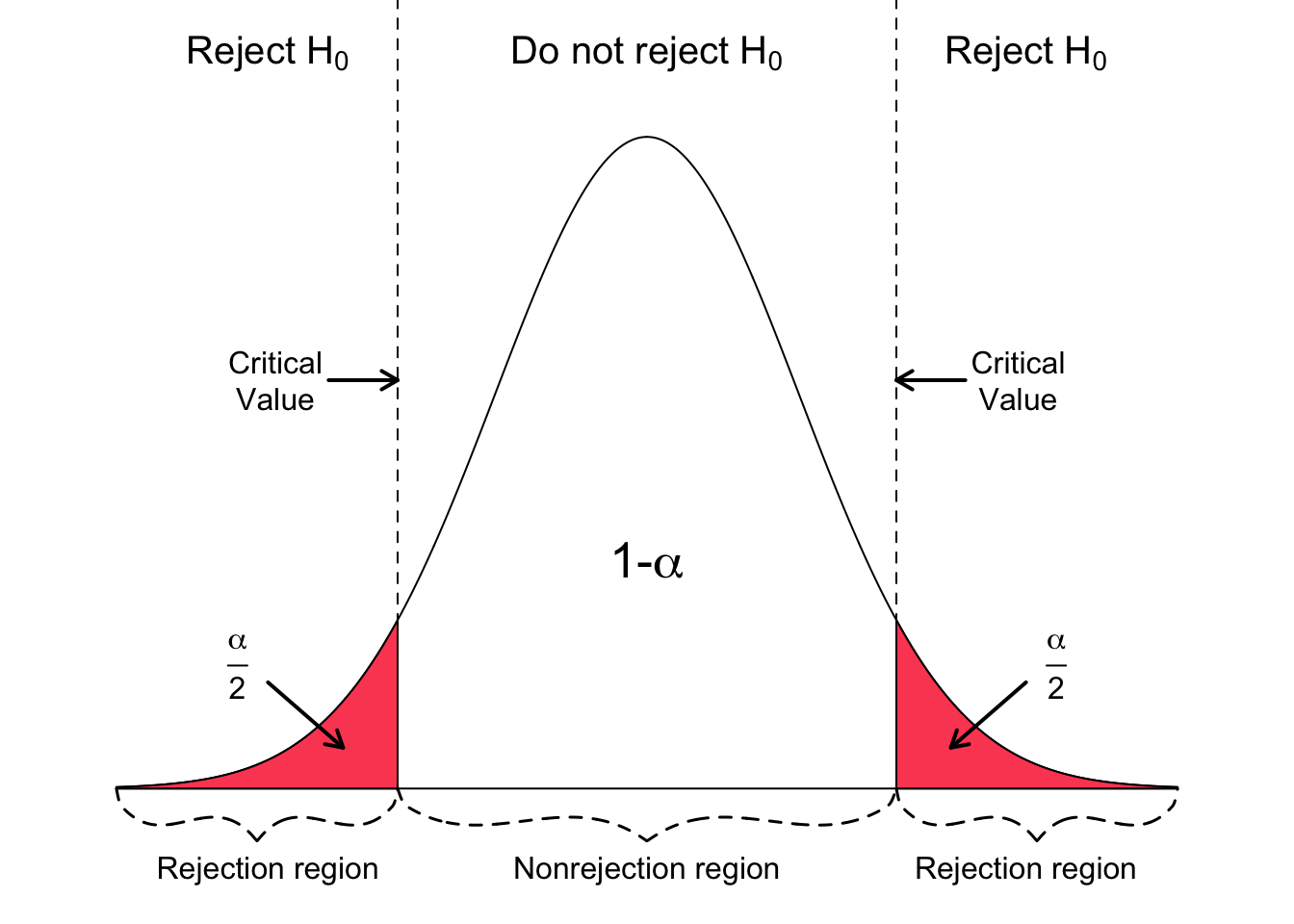
- What do rejection regions look like for 1-sided tests?
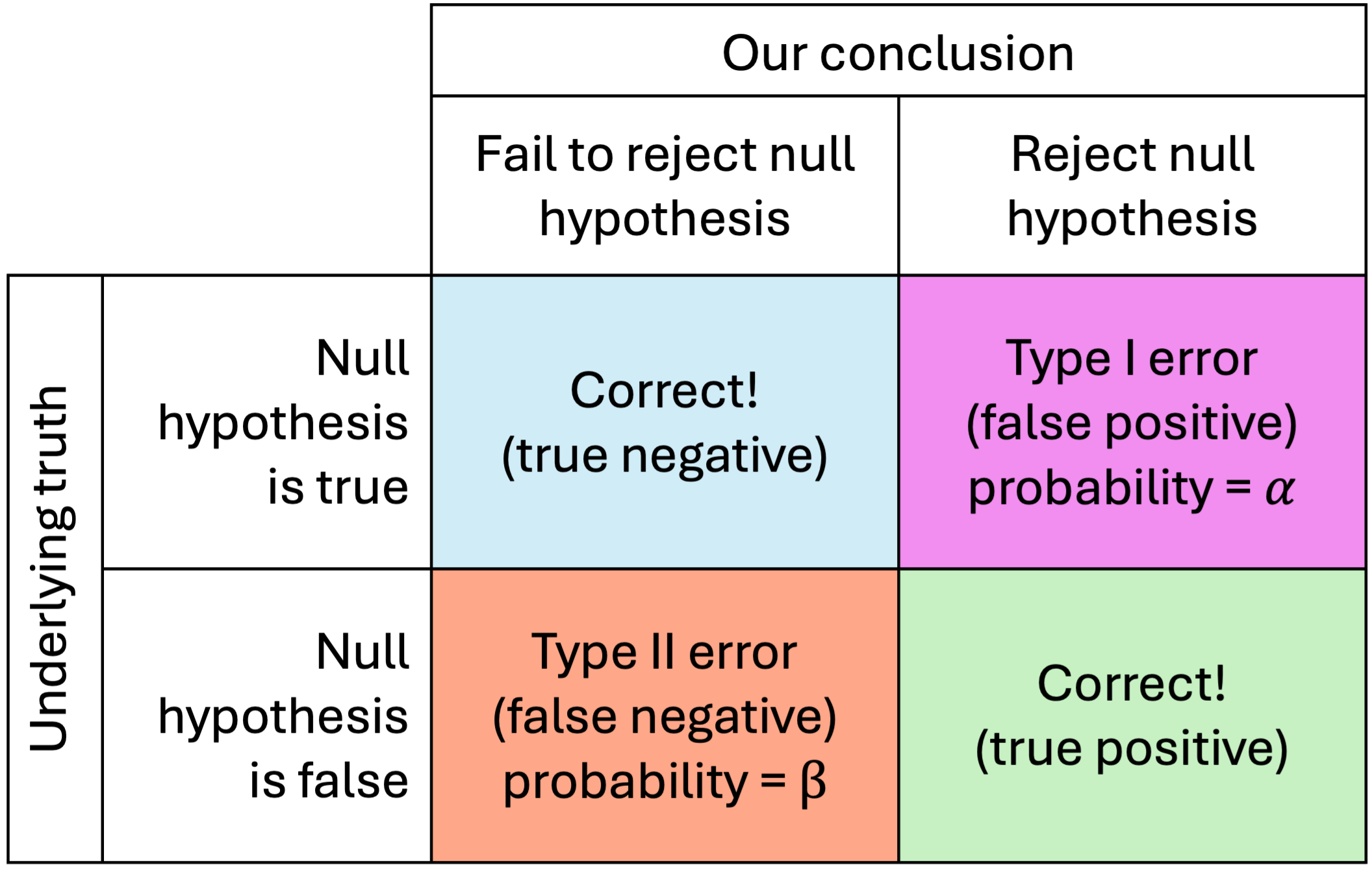
Let’s start with some important definitions in words
- Type I error (\(\alpha\)): Probability of rejecting the null hypothesis given that the null is true
- Type II error (\(\beta\)): Probability of failing to reject the null hypothesis given that the null hypothesis is false
- Power (or sensitivity) (\(1 - \beta\)): Probability of rejecting the null hypothesis given that the null is false (correct)
- Specificity (\(1-\alpha\)): Probability of failing to reject the null hypothesis given that the null is true (correct)
What does that look like with our two populations?
- \(\alpha\) = probability of making a Type I error
- This is the significance level (usually 0.05)
- Set before study starts
- \(\beta\) = probability of making a Type II error
- Ideally we want
- small Type I & II errors and
- big power

Power (or sensitivity) (\(1 - \beta\)): Probability of rejecting the null hypothesis given that the null is false (correct)
- Power is the correct region that is usually in line with our study design: studies are often seeing if there is a distinction between two populations
Power
- Power (or sensitivity) (\(1 - \beta\)): Probability of rejecting the null hypothesis given that the null is false (correct)
- Power is also called the
- true positive rate,
- probability of detection, or
- the sensitivity of a test
- Typically, we aim for 80% or 90% power

If you want to keep revisiting these concepts!
From the applet at https://rpsychologist.com/d3/NHST/
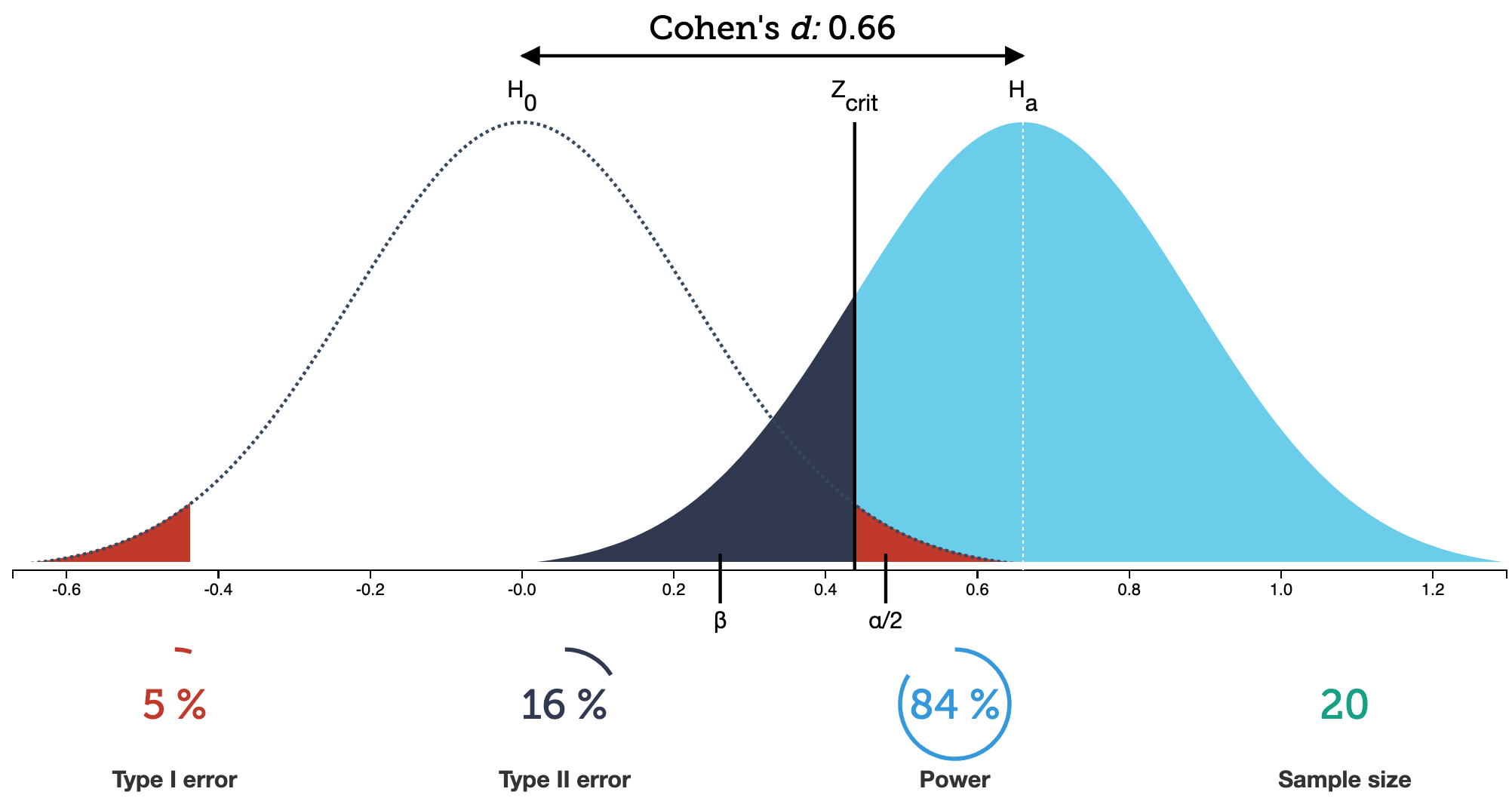
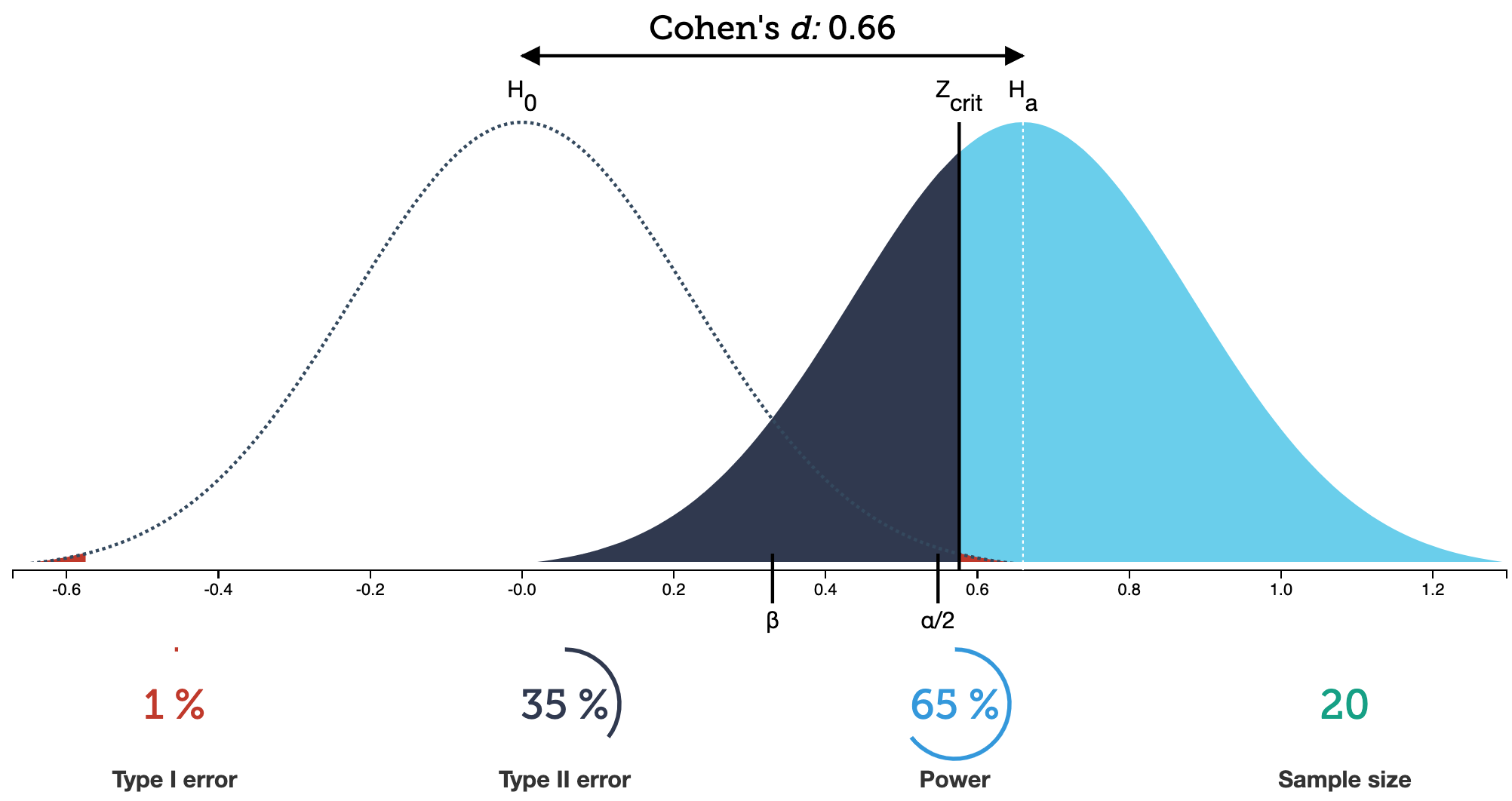
- Cohen’s d is just a stanardized value to represent the difference in means: \[d = \dfrac{\overline{x}_1 - \overline{x}_2}{s}\]
Example calculating power (2/3)
Let’s say we have:
- a null population with a normal distribution, centered at 0 with a standard error of 1 (\(X_0 \sim Norm(0,1)\))
- an alternative population, centered at 3 with a standard error of 1 (\(X_A \sim Norm(3,1)\))
Find the power of a 2-sided test if the actual mean is \(3\) and our significance level is 0.05.

- Power = \(P\) (Reject \(H_0\) when alternative pop is true)
- Correctly reject null
- When \(\alpha\) = 0.05, we reject \(H_0\) when the test statistic z is at least 1.96 (critical value is 1.96 under the null distribution)
- Then we need to calculate the probability that we are in the rejection regions given we are actually in the alternative population
- Thus under the alternative population, we need to calculate \(P(X_A \le -1.96) + P(X_A \ge 1.96)\)
Example calculating power (3/3)

Thus under the alternative population, we need to calculate \(P(X_A \le -1.96) + P(X_A \ge 1.96)\)
Under the alternative population we have \(X_A \sim Norm(3,1)\)
# left tail + right tail:
pnorm(-1.96, mean=3, sd=1,
lower.tail=TRUE) +
pnorm(1.96, mean=3, sd=1,
lower.tail=FALSE)[1] 0.8508304Answer: The power is 85%
- The left tail probability
pnorm(-1.96, mean=3, sd=1, lower.tail=TRUE)is essentially 0 in this case. - Note that this power calculation specified the value of the SE instead of the standard deviation and sample size \(n\) individually.
pwr: sample size for one mean test
Specify all parameters except for the sample size:

pwr: power for one mean test
Specify all parameters except for the power:

pwr: Two-sample t-test: sample size
Example: Let’s revisit our caffeine taps study. Investigators want to know what sample size they would need to detect a 2 point difference between the two groups. Assume the SD in both group samples is 2.6.
Specify all parameters except for the sample size:

::::::
pwr: Two-sample t-test: power
Example: Let’s revisit our caffeine taps study. Investigators want to know what power they have to detect a 2 point difference between the two groups. The two groups are both size 35 (like in our previous example). Assume the SD in both group samples is 2.6.
Specify all parameters except for the power:
