Lesson 17: Comparing Means with ANOVA
TB sections 5.5
2024-12-02
Where are we?
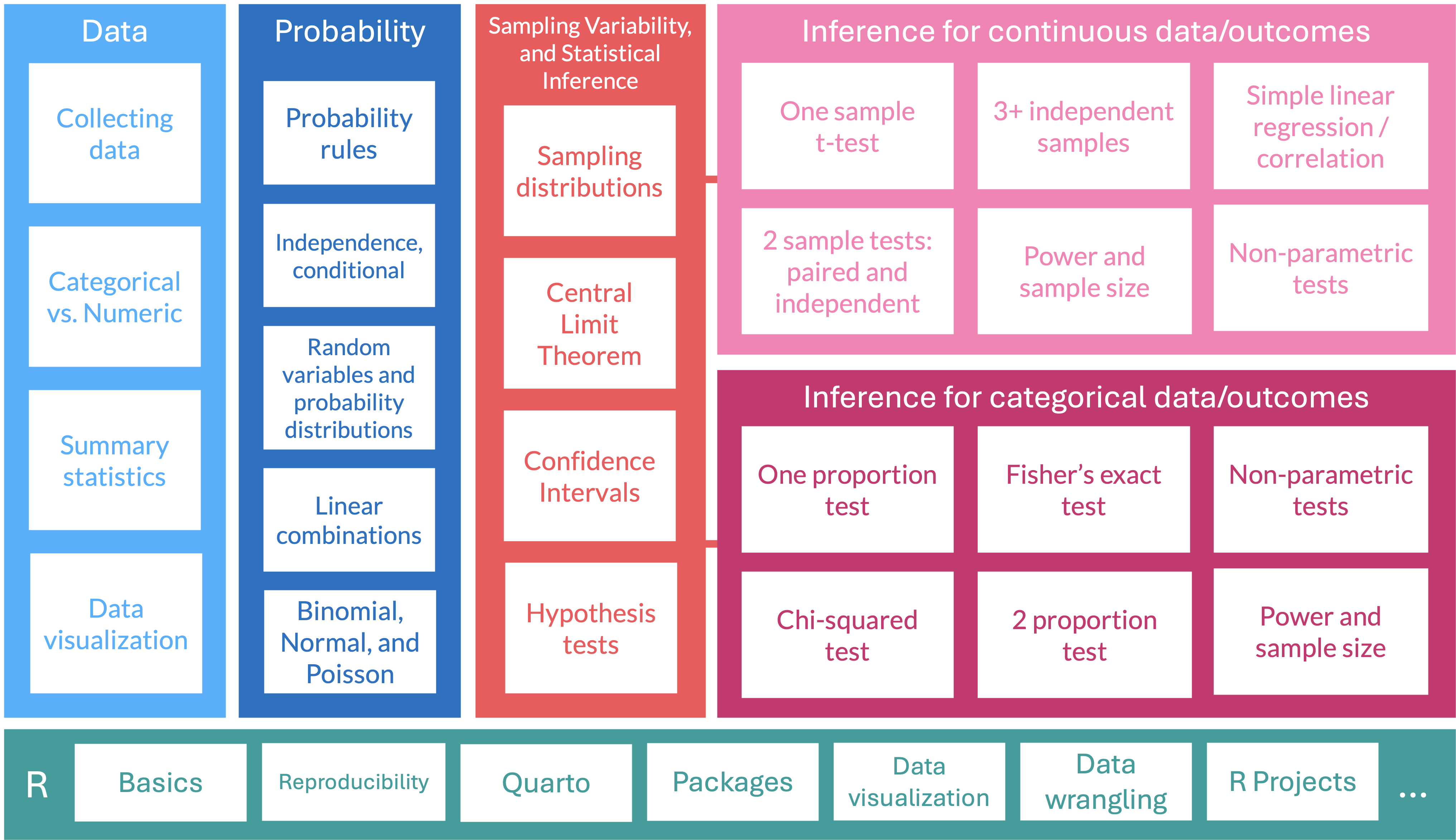
From Lesson 8: Side-by-side boxplots with data points
- We can look at the boxplot of percent change for each genotype with points shown so we can see the distribution of observations better

From Lesson 8: Ridgeline plot
- Overlapped densities were easy enough to see with 3 genotypes
- If you have many categories, a ridgeline plot might make it easier to see

Comparing means
Whether or not two means are significantly different depends on:
- How far apart the means are
- How much variability there is within each group
Questions:
- How to measure variability between groups?
- How to measure variability within groups?
- How to compare the two measures of variability?
- How to determine significance?
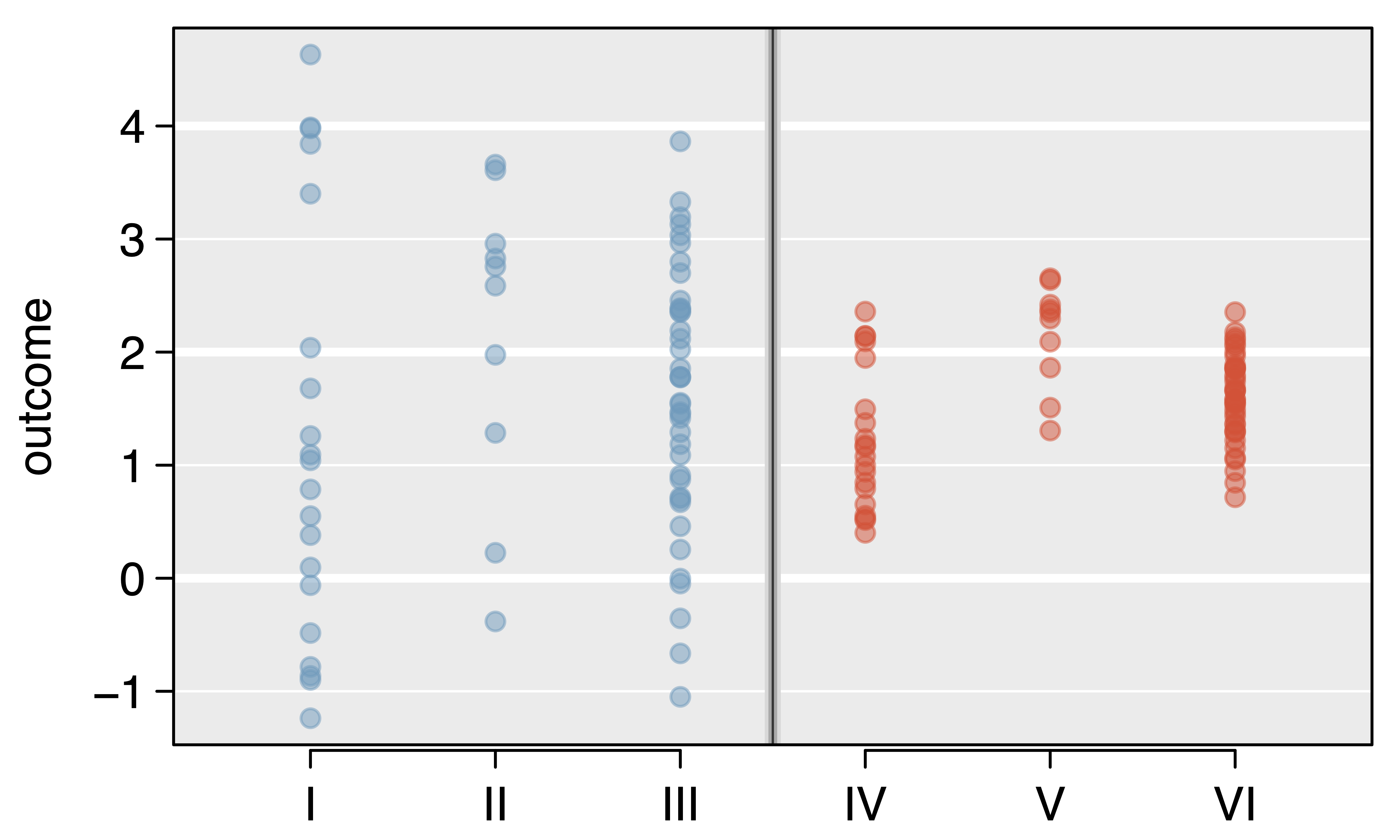
Generic ANOVA table
ANOVA: Analysis of Variance
ANOVA compares the variability between groups to the variability within groups




ANOVA: Analysis of Variance
Analysis of Variance (ANOVA) compares the variability between groups to the variability within groups
\[\sum_{i = 1}^k \sum_{j = 1}^{n_i}(x_{ij} -\bar{x})^2 \ \ = \ \sum_{i = 1}^k n_i(\bar{x}_{i}-\bar{x})^2 \ \ + \ \ \sum_{i = 1}^k\sum_{j = 1}^{n_i}(x_{ij}-\bar{x}_{i})^2\]

Total Sums of Squares (SST)

Total Sums of Squares:
\[SST = \sum_{i = 1}^k \sum_{j = 1}^{n_i}(x_{ij} -\bar{x})^2 = (N-1)s^2\]
where
- \(N=\sum_{i=1}^{k}n_i\) is the total sample size and
- \(s^2\) is the grand standard deviation of all the observations
This is the sum of the squared differences between each observed \(x_{ij}\) value and the grand mean, \(\bar{x}\).
That is, it is the total deviation of the \(x_{ij}\)’s from the grand mean.
Sums of Squares due to Groups (SSG)

Sums of Squares due to Groups:
\[SSG = \sum_{i = 1}^k n_i(\bar{x}_{i}-\bar{x})^2\]
This is the sum of the squared differences between each group mean, \(\bar{x}_{i}\), and the grand mean, \(\bar{x}\).
That is, it is the deviation of the group means from the grand mean.
Also called the Model SS, or \(SS_{model}.\)
Sums of Squares Error (SSE)

Sums of Squares Error:
\[SSE = \sum_{i = 1}^k\sum_{j = 1}^{n_i}(x_{ij}-\bar{x}_{i})^2 = \sum_{i = 1}^k(n_i-1)s_{i}^2\] where \(s_{i}\) is the standard deviation of the \(i^{th}\) group
This is the sum of the squared differences between each observed \(x_{ij}\) value and its group mean \(\bar{x}_{i}\).
That is, it is the deviation of the \(x_{ij}\)’s from the predicted ndrm.ch by group.
Also called the residual sums of squares, or \(SS_{residual}.\)
ANOVA table to hypothesis test?
- Okay, so how do we use all these types of variability to run a test?
- How do we determine, statistically, if the groups have different means or not?
- Answer: We use the F-statistic in a hypothesis test!
Thinking about the F-statistic
If the groups are actually different, then which of these is more accurate?
- The variability between groups should be higher than the variability within groups
- The variability within groups should be higher than the variability between groups
If there really is a difference between the groups, we would expect the F-statistic to be which of these:
- Higher than we would observe by random chance
- Lower than we would observe by random chance
The F-distribution
- The F-distribution is skewed right
- The F-distribution has two different degrees of freedom:
- one for the numerator of the ratio (k – 1) and
- one for the denominator (N – k)
- \(p\)-value
- \(P(F > F_{stat})\)
- is always the upper tail
- (the area as extreme or more extreme)
