Lesson 5: Simple Logistic Regression
2024-04-15
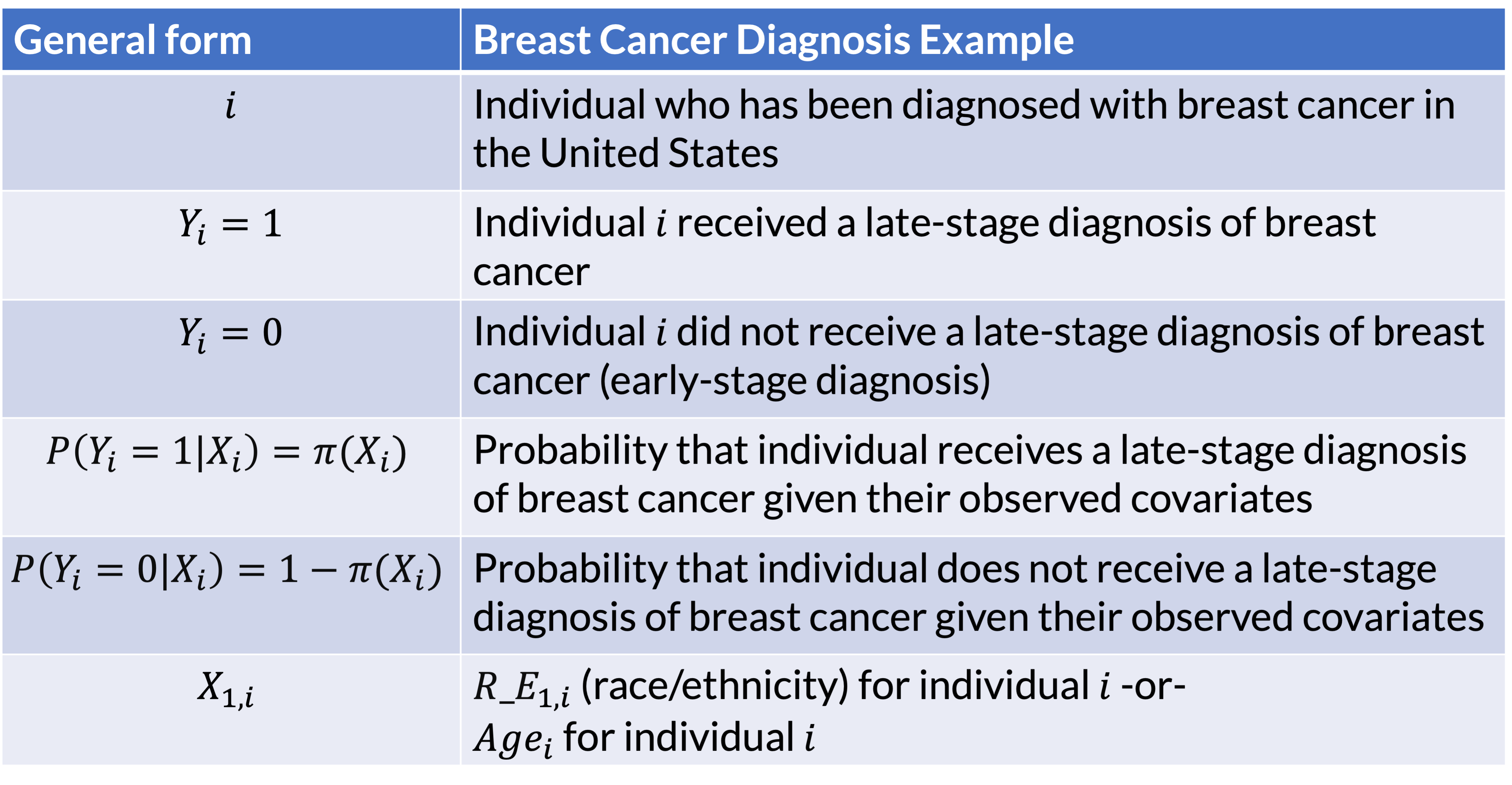
Example: Health disparities in breast cancer diagnosis (1/2)
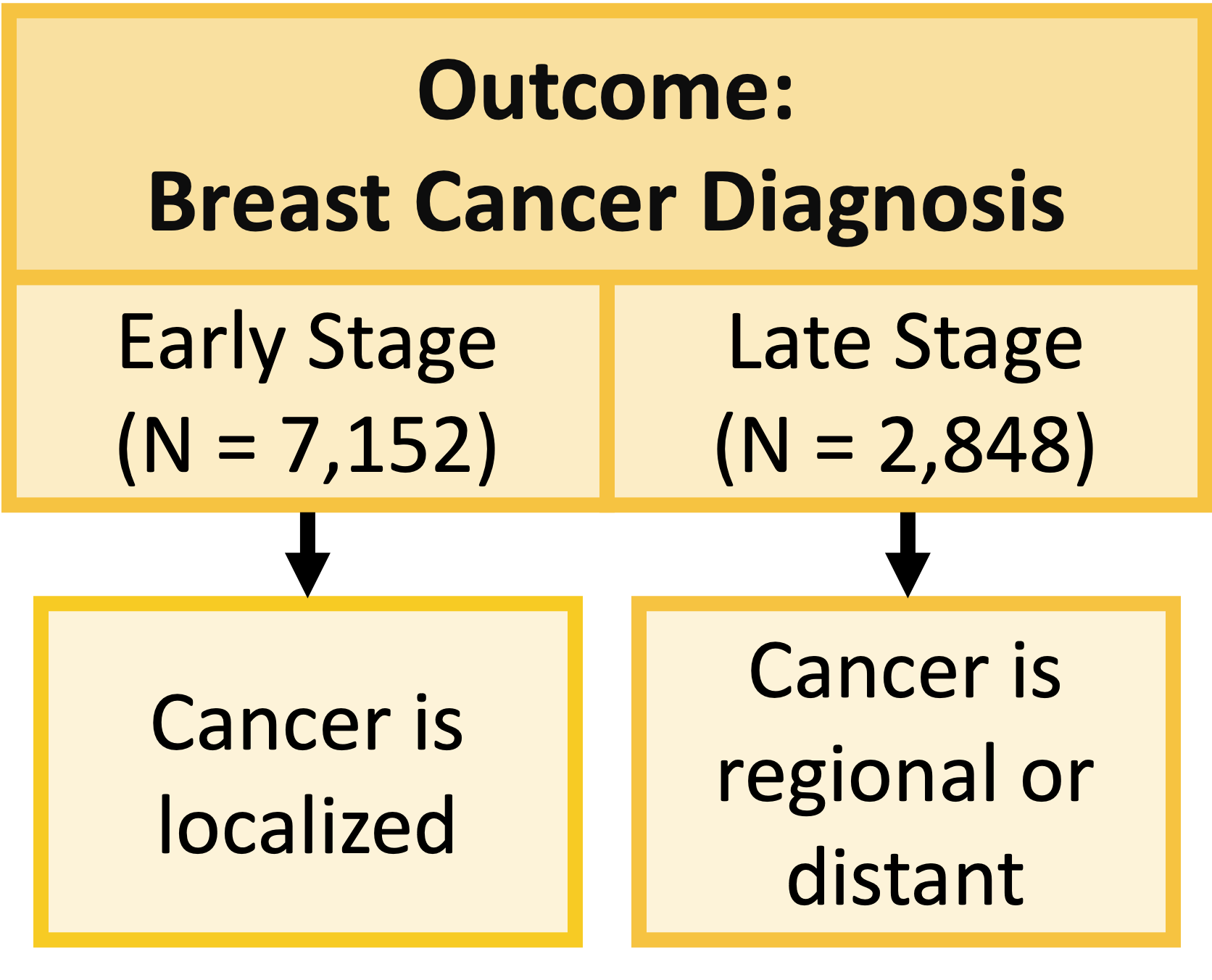
Example: Health disparities in breast cancer diagnosis (2/2)


How do we determine differences in diagnosis? (1/2)
- Breast cancer diagnosis study: two variables that are categorical
- We could use a contingency table (or two-way table)
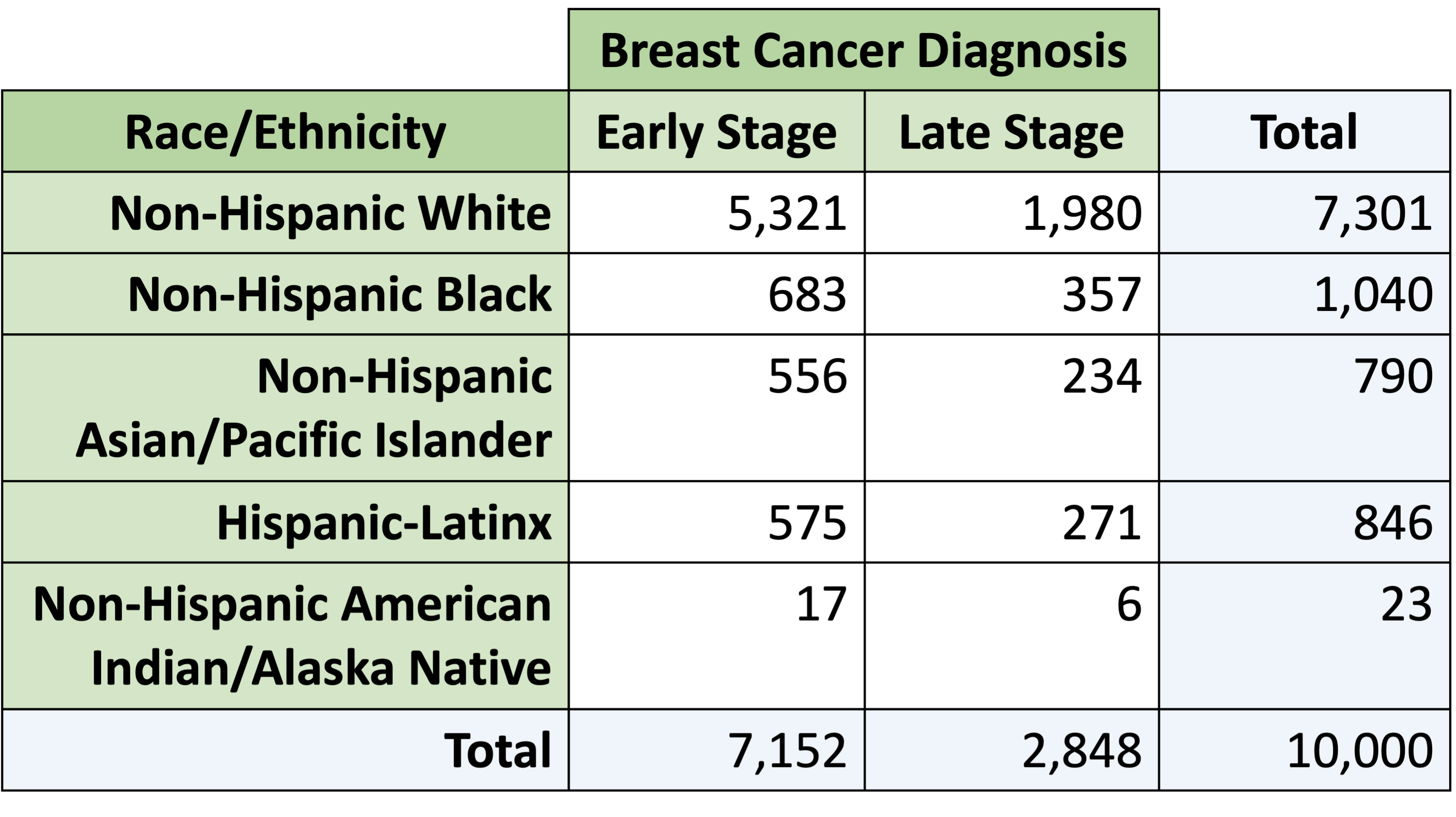
How do we determine differences in diagnosis? (2/2)
Contingency table does not work for…
- Continuous covariates
- Multiple covariates
- Logistic regression models can handle multiple covariates that are continuous or categorical

How do we determine differences in diagnosis? (2/2)
Contingency table does not work for…
- Continuous covariates
- Multiple covariates
- Logistic regression models can handle multiple covariates that are continuous or categorical
Reference: individual components
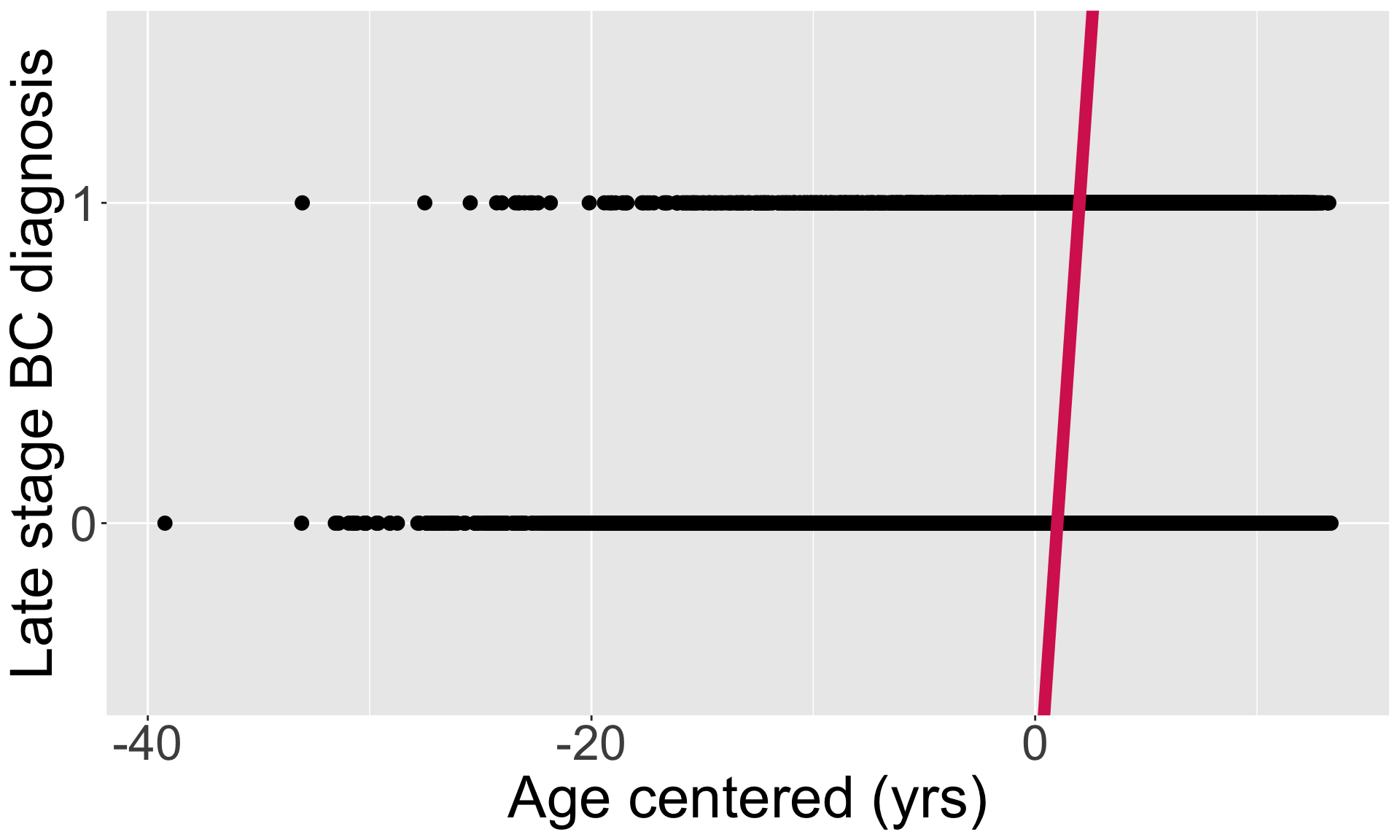
Violated: Linearity
The relationship between the variables is linear (a straight line):
- \(E[Y|X]\) or \(\pi(X)\), is a straight-line function of \(X\)
The independent variable \(X\) can take any value, while \(\pi(X)\) is a probability that should be bounded by [0,1]
- We cannot use linear mapping to translate \(X\) to \(\pi(X)\)
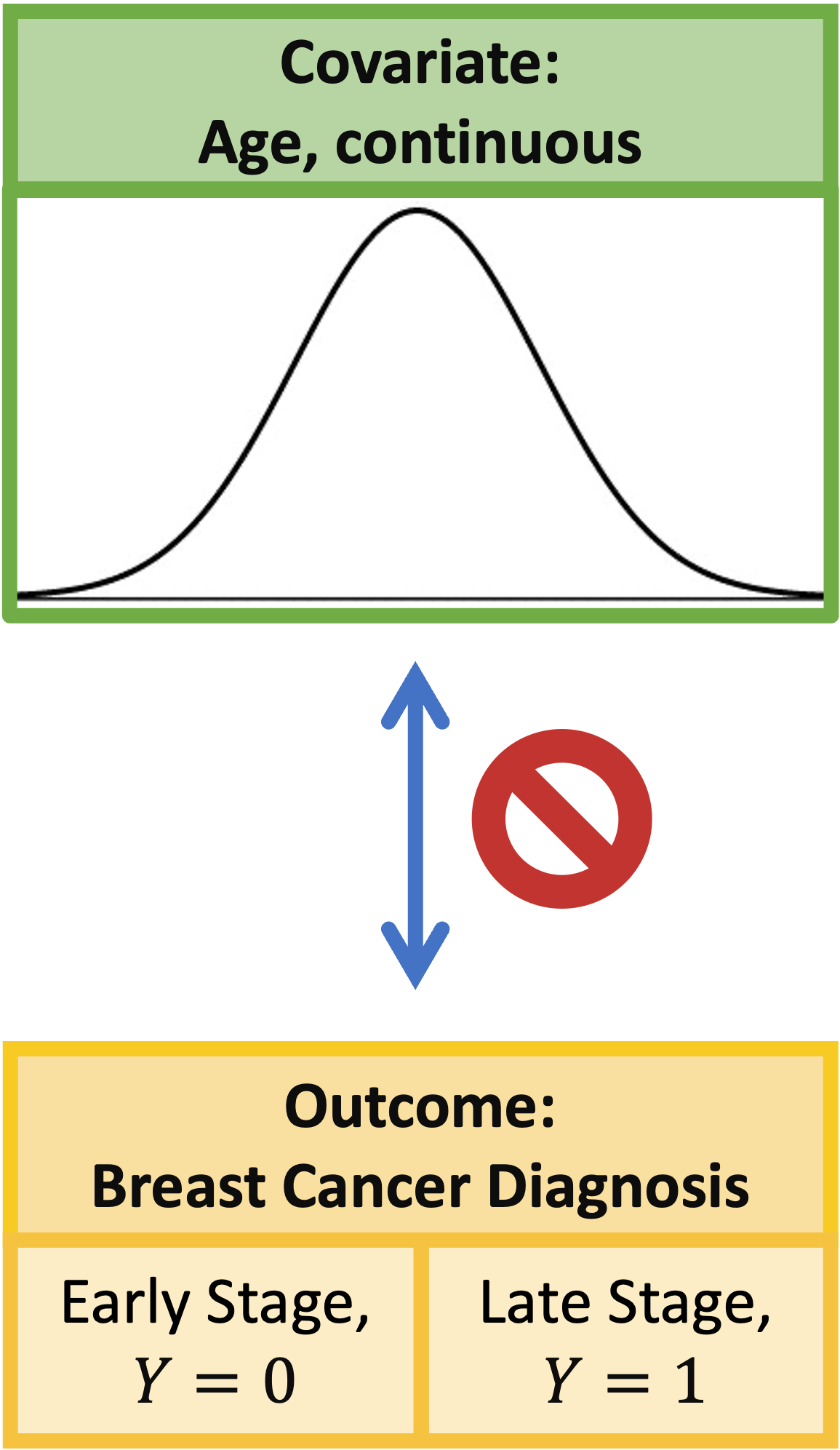
Violated: Normality
- In linear regression, \(\epsilon\) is distributed normally
- Recall that \(Y\) can take only one of the two values: 0 or 1
- And the fitted \(Y\), \(\widehat{Y}\) can also only take values 0 or 1
- Thus, \(\epsilon = Y - \widehat{Y}\) can only take values -1, 0, or 1
- Then \(\epsilon\) cannot follow a normal distribution, which would require \(\epsilon\) to have a continuum of values and no upper or lower bound

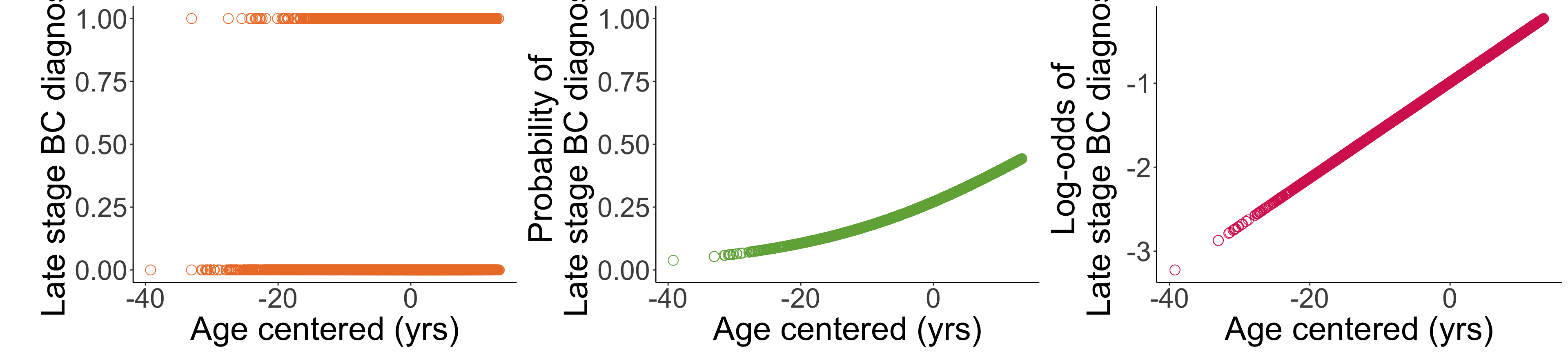
How do we transform our outcome? (1/2)
How do we transform our outcome? (2/2)
![]()
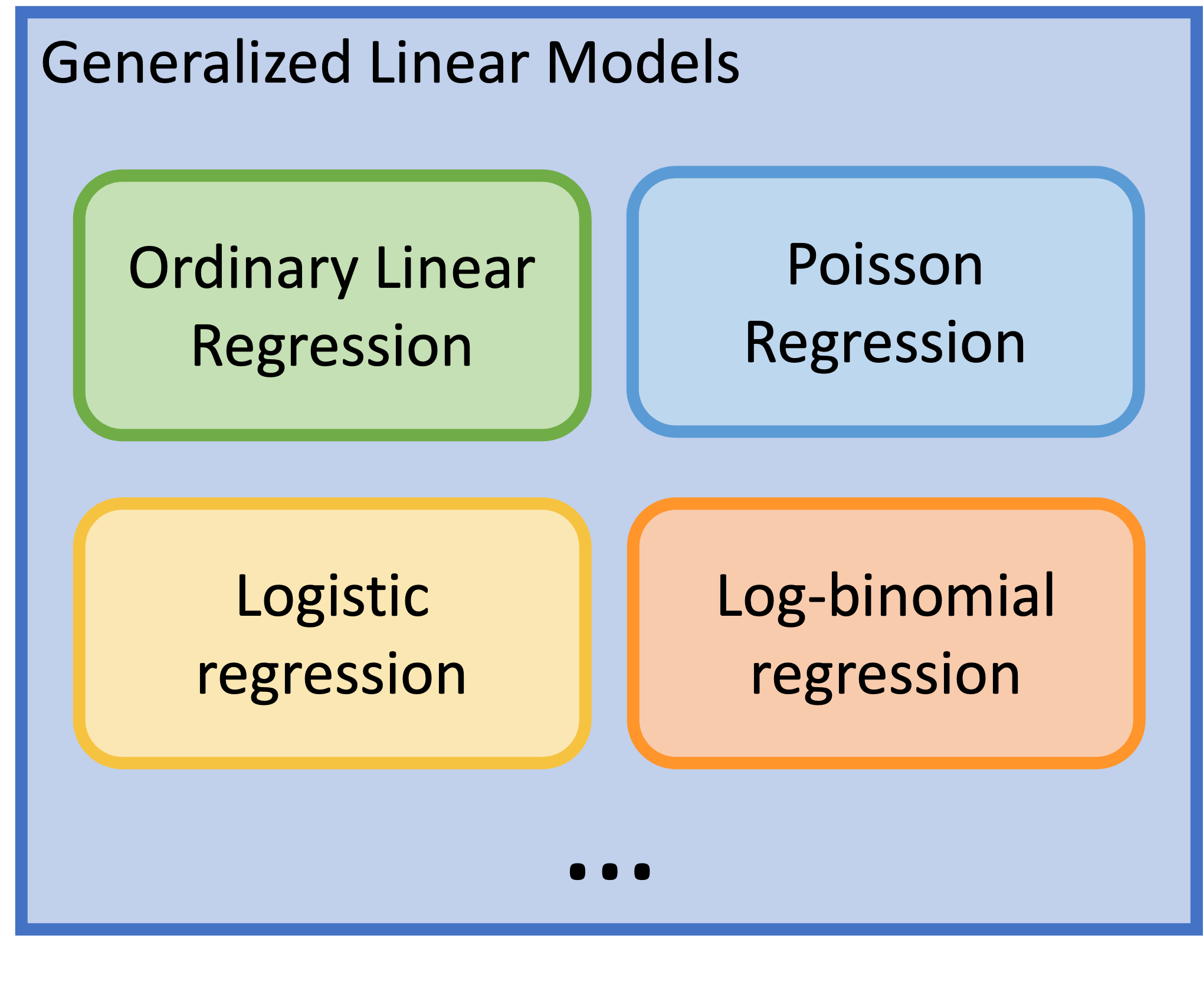
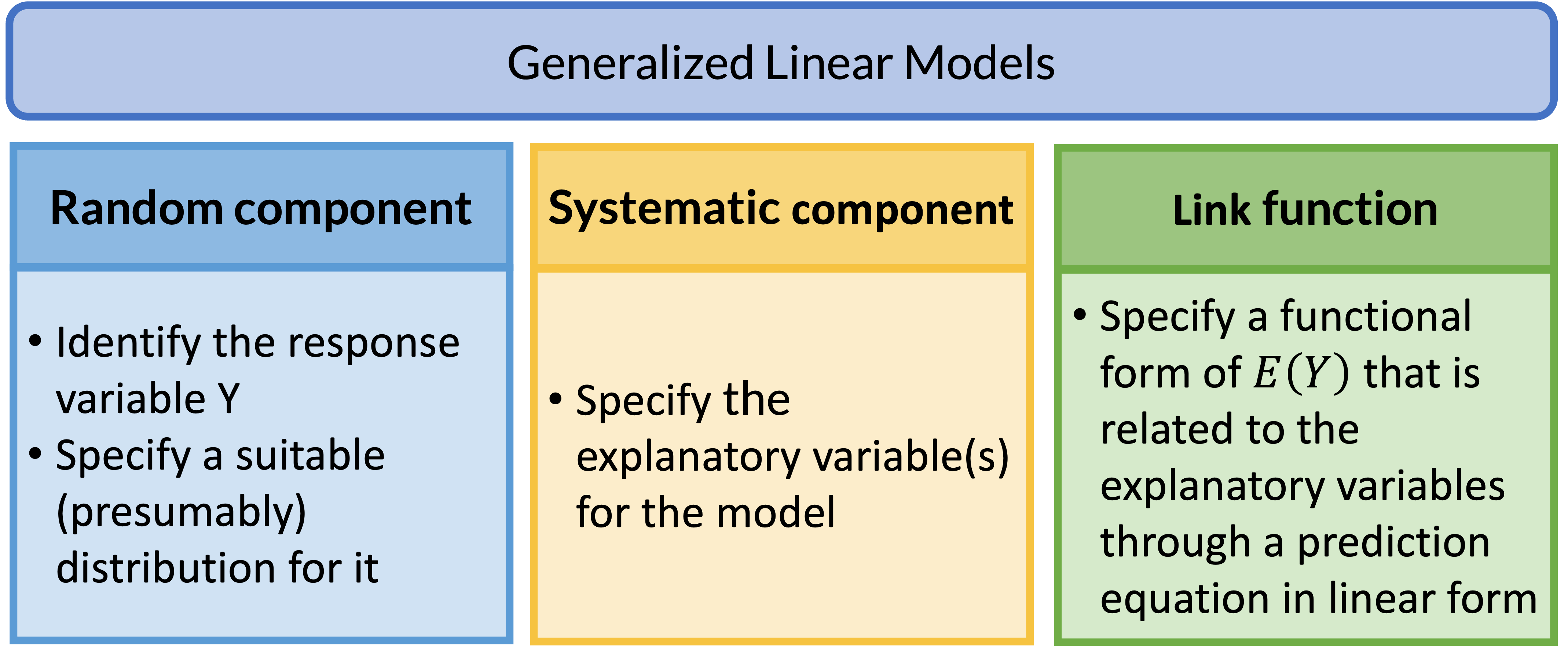
Generalized Linear Models (GLMs) (1/2)
Generalized Linear Models are a class of models that includes regression models for continuous and categorical responses
- Responses follow exponential family distribution
- Helps us set up other types of regressions using each outcome’s needed transformations
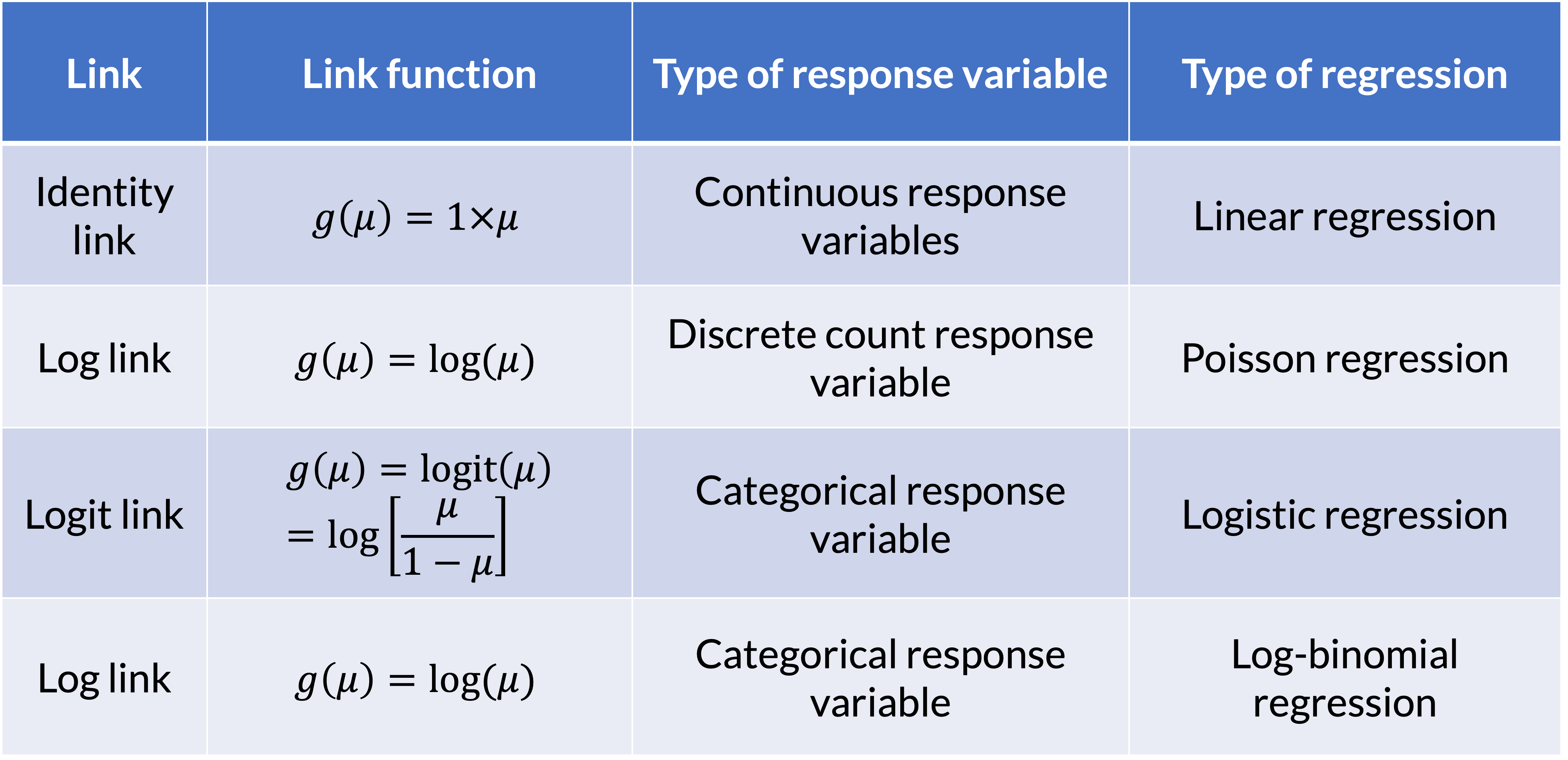
Here we will focus on the GLMs for categorical/count data
Logistic regression is just a one type of GLM
Poisson regression – for counts
Log-binomial can be used to focus on risk ratio
Generalized Linear Models (GLMs) (2/2)
GLM: Link Function
Example: Breast cancer diagnosis (3/3)
Translate the results back to an equation!
Just going to pull the coefficients so I have a reference as I create the fitted regression model:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.9894225 0.0232055 -42.63742 0.000000e+00
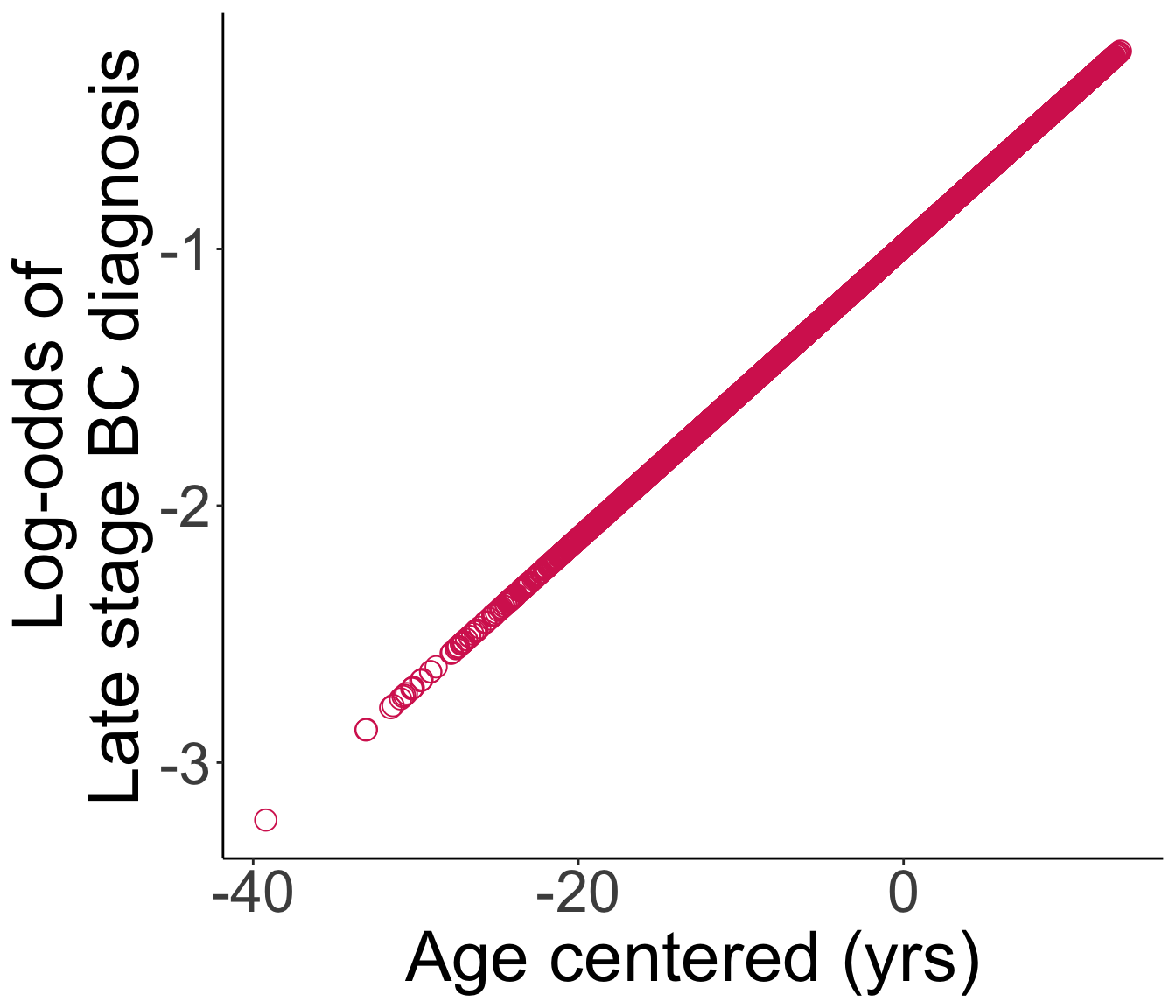
Age_c 0.0569645 0.0032039 17.77974 1.014557e-70- Fitted logistic regression model: \[\text{logit}(\widehat{\pi}(Age)) = -0.989 + 0.057 \cdot Age\]
We will need to reverse the transformation process in slide 24-25 to find the odds ratios
- Will do in next week’s lessons
- This is the fitted line: