Lesson 12: Assessing Model Fit
2024-05-13
Last Class: Reporting results of GLOW Study with interactions
- Remember our main covariate is prior fracture, so we want to focuse on how age changes the relationship between prior fracture and a new fracture!
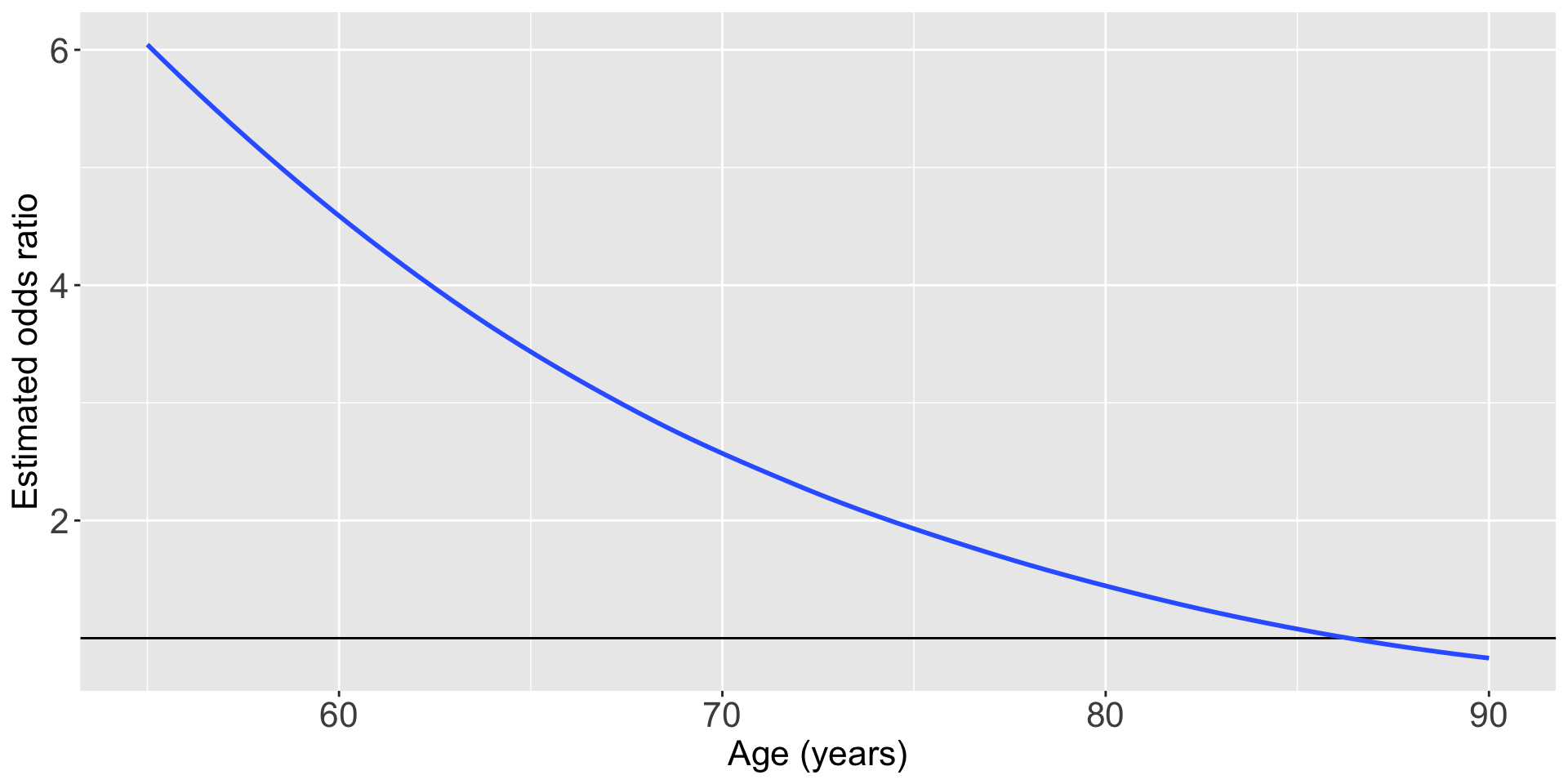
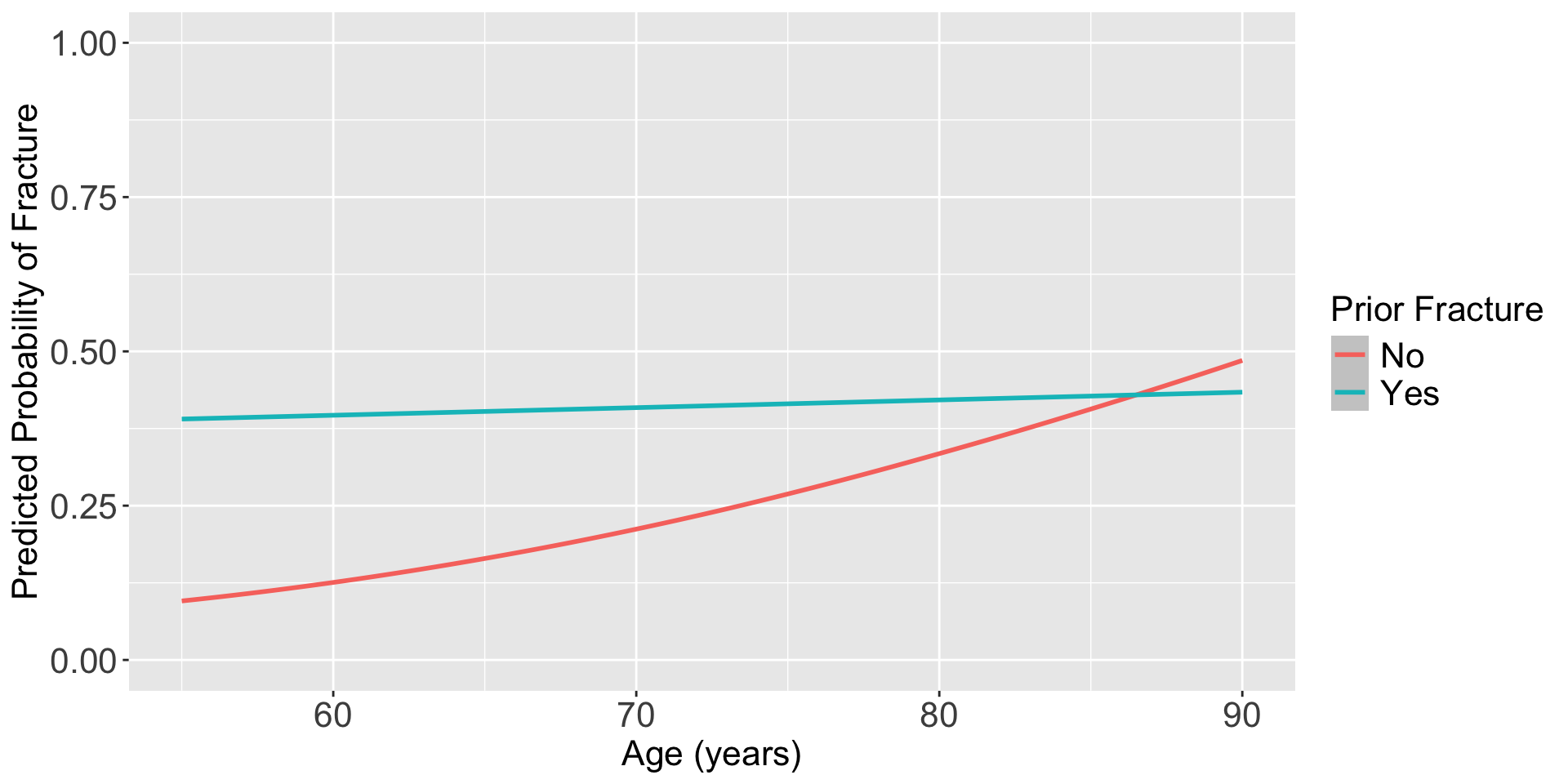
For individuals 69 years old, the estimated odds of a new fracture for individuals with prior fracture is 2.72 times the estimated odds of a new fracture for individuals with no prior fracture (95% CI: 1.70, 4.35). As seen in Figure 1 (a), the odds ratio of a new fracture when comparing prior fracture status decreases with age, indicating that the effect of prior fractures on new fractures decreases as individuals get older. In Figure 1 (b), it is evident that for both prior fracture statuses, the predict probability of a new fracture increases as age increases. However, the predicted probability of new fracture for those without a prior fracture increases at a higher rate than that of individuals with a prior fracture. Thus, the predicted probabilities of a new fracture converge at age [insert age here].
ROC Curve and AUC (1/2)
- Receiver Operating Characteristics (ROC) curve is useful tool to quantify how good is our model predicting binary outcome
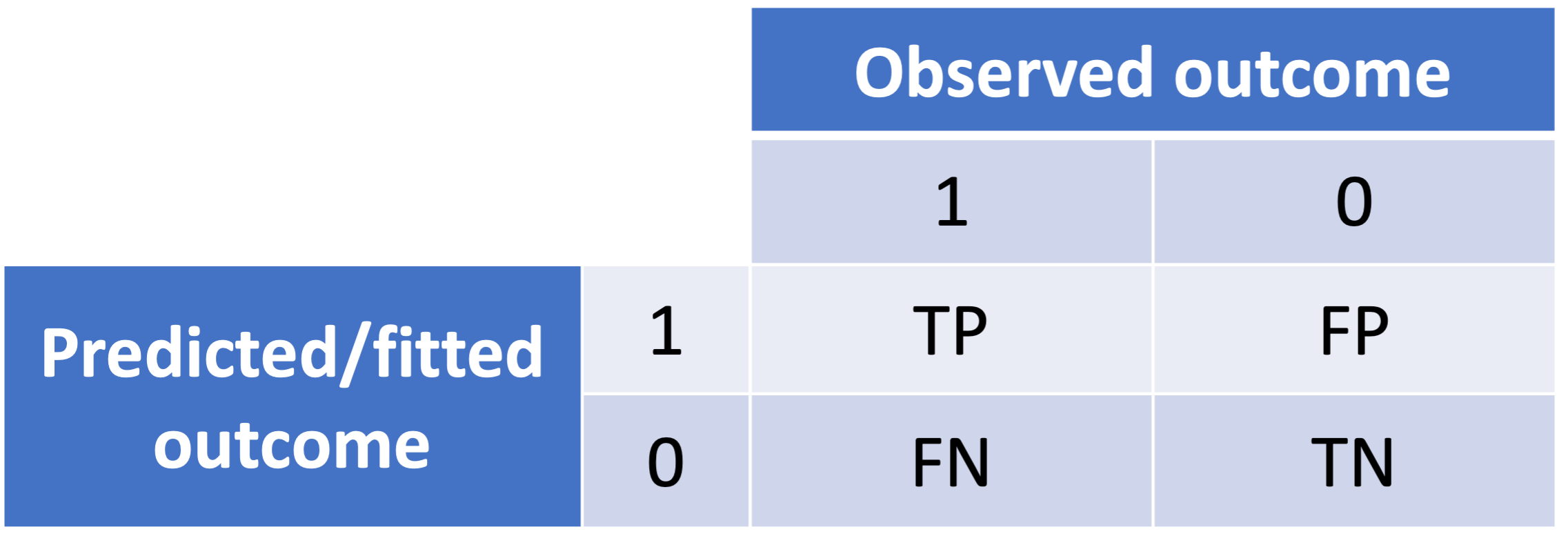
It is a plot of sensitivity (true positive rate) versus (1-specificity) or false positive rate of fitted binary values
True Positive Rate \(= \dfrac{TP}{TP + FN}\)
False Positive Rate \(= \dfrac{FP}{FP + TN}\)
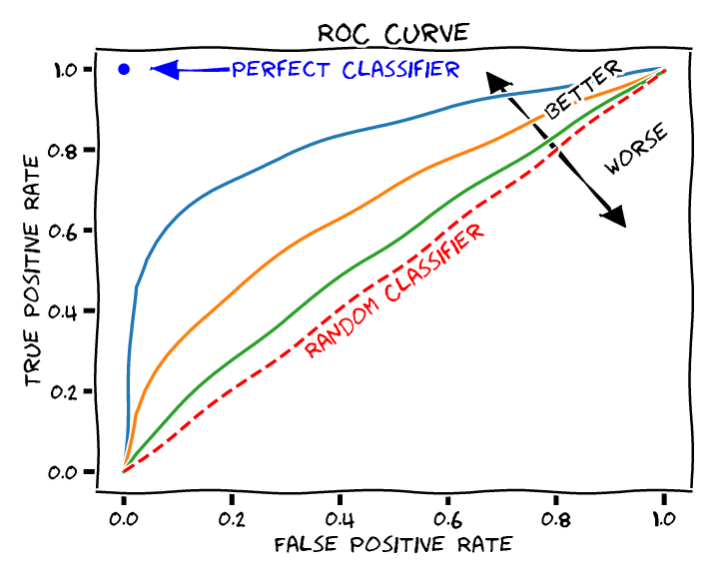
- The ROC curve shows the tradeoff between sensitivity and specificity
ROC Curve and AUC (2/2)
Area under the ROC curve (AUC ROC) is a reasonable summary of the overall predictive accuracy of the test
- Accuracy means how well the predicted value matches the observed value
The closer the curve follows the left-hand border and top border of the ROC space, the more accurate the test
- An AUC =1 represents 100% accuracy
The closer the curve comes to the 45-degree diagonal line, the less accurate the test
An AUC = 0.5 represents an unhelpful model
- Random predictions
ROC Curve and AUC (3/3)
- Often only report the AUC
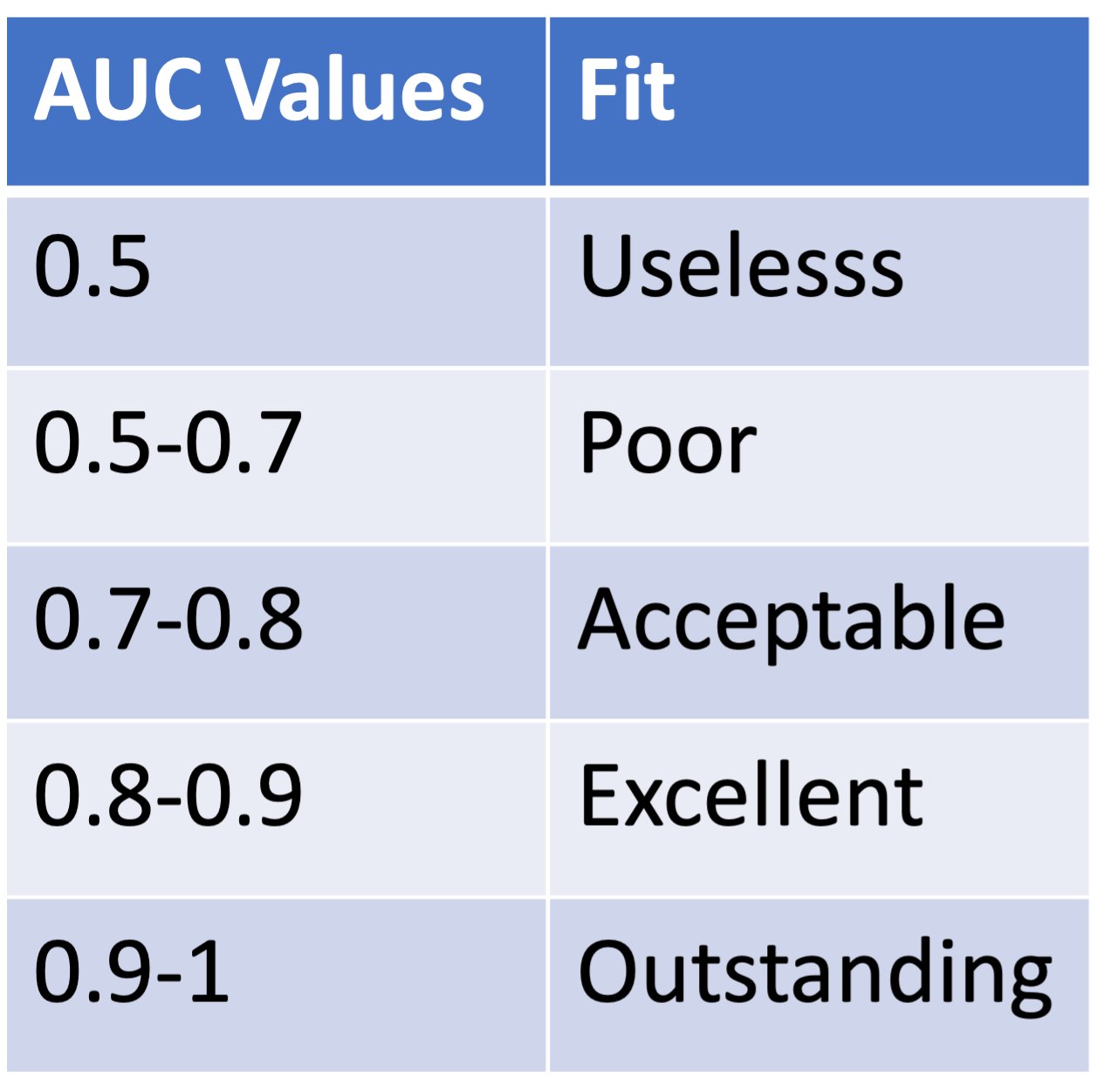
- Suggestions of how to interpret model fit through AUC values:
GLOW Study: ROC of interaction model
library(pROC)
predicted <- predict(glow_m3, glow, type="response")
# define object to plot and calculate AUC
rocobj <- roc(glow$fracture, predicted)
auc <- round(auc(glow$fracture, predicted),4)
#create ROC plot
ggroc(rocobj, colour = 'steelblue',
size = 2, legacy.axes = TRUE) +
ggtitle(paste0('ROC Curve ','(AUC = ',auc,')')) +
theme(text = element_text(size = 23)) +
xlab("False Positive Rate (1 - Specificity)") +
ylab("True Positive Rate (Sensitivity)")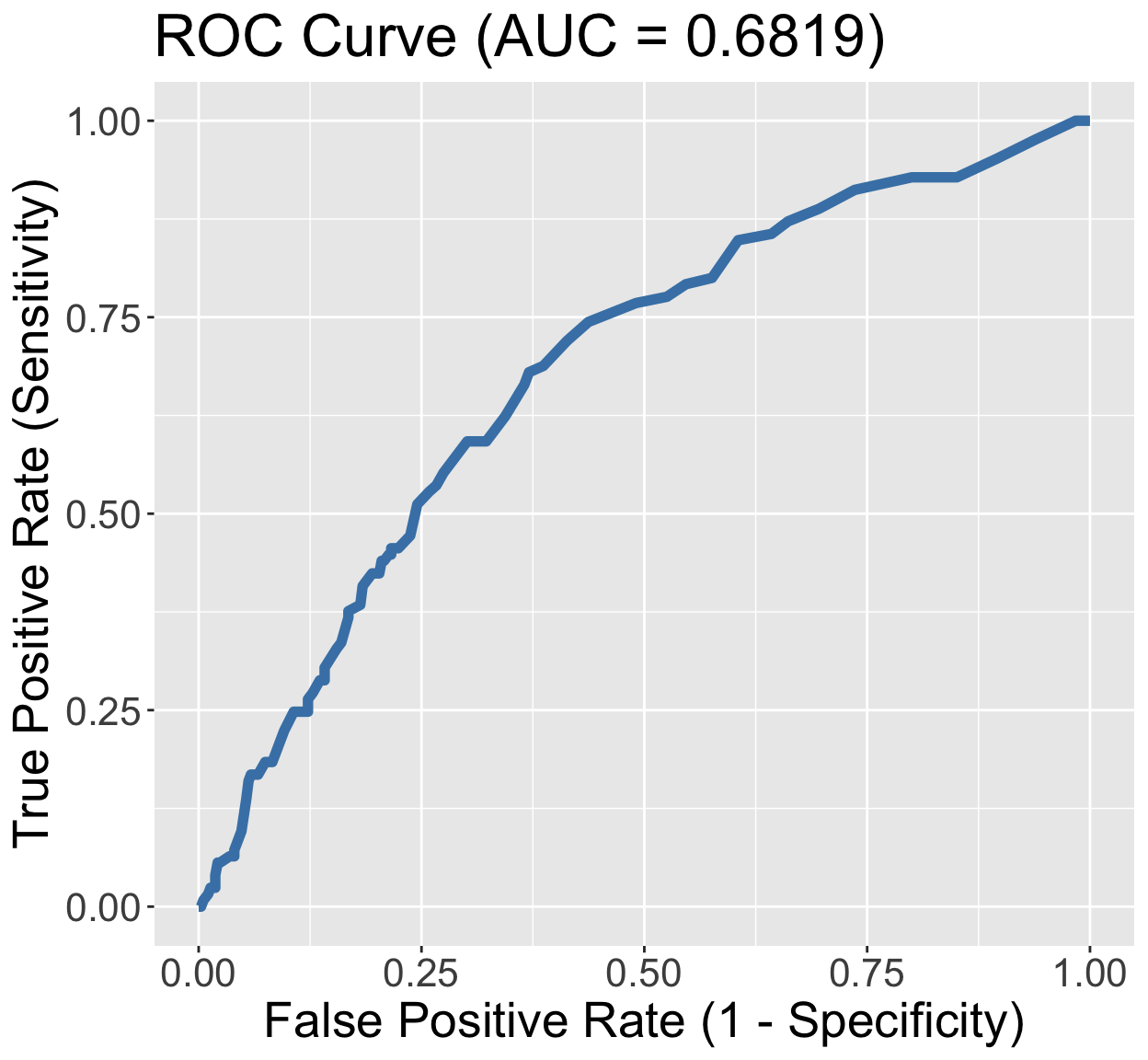
- We have a poorly fitting model
- We can take
aucand compare it to other models: good way to pick a model based on predictive power