Lesson 16: Poisson Regression
2024-05-29
Review: Generalized Linear Models (GLMs)
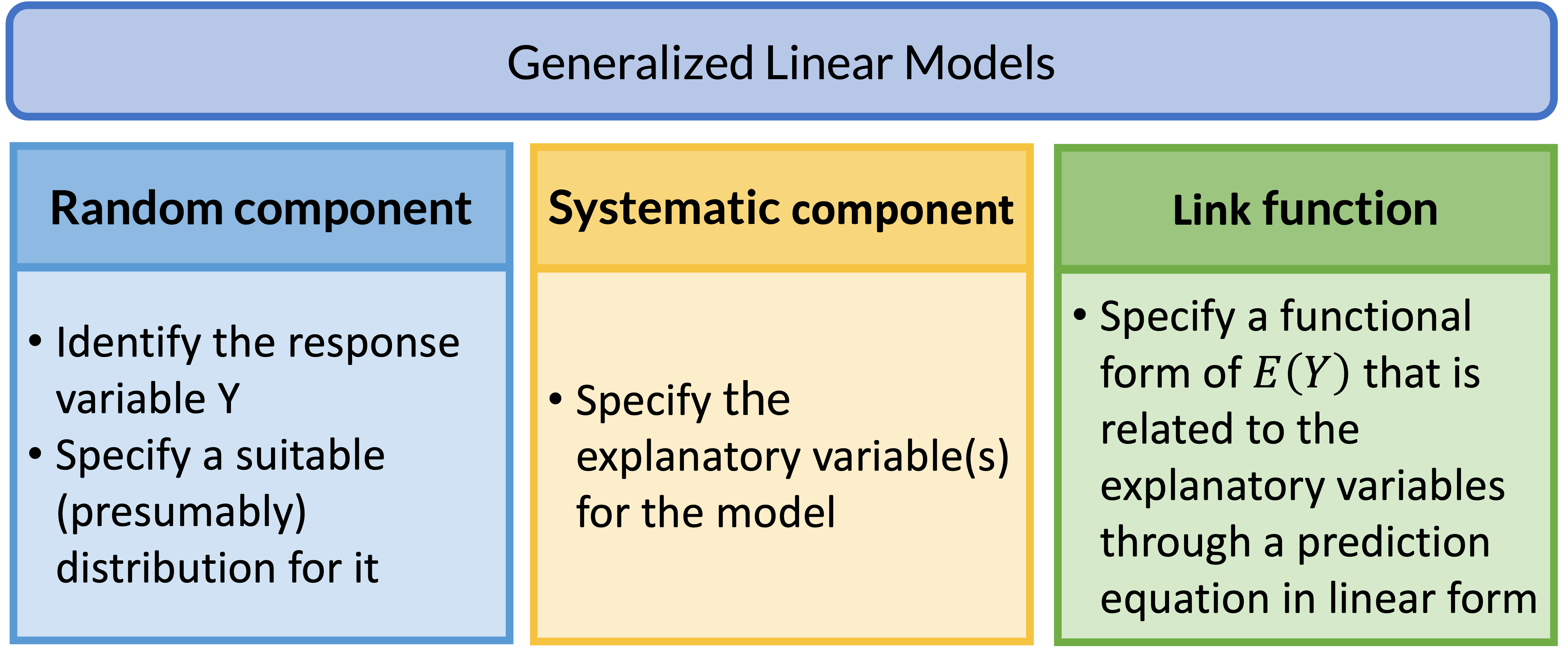
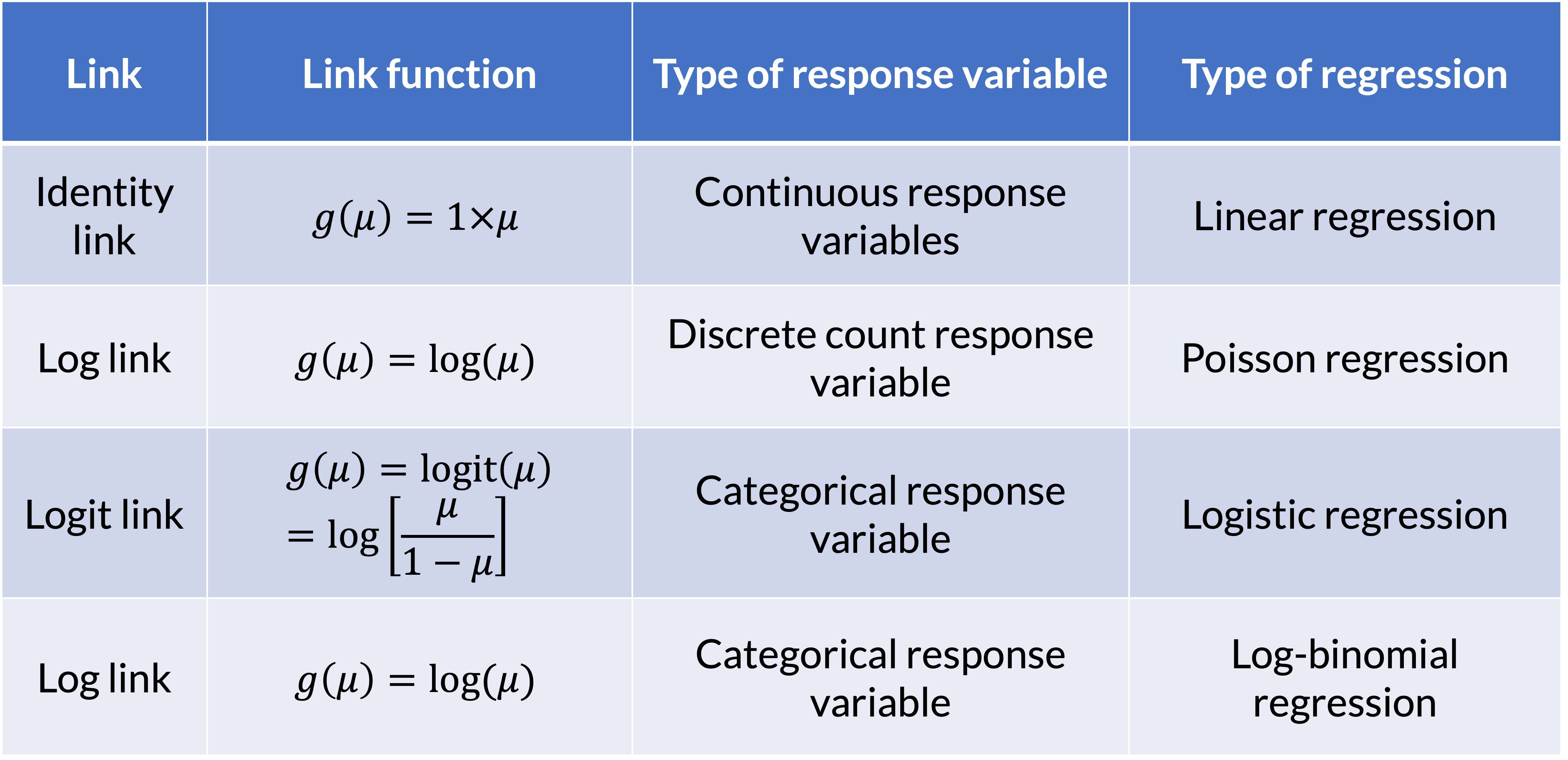
GLM: Link Function
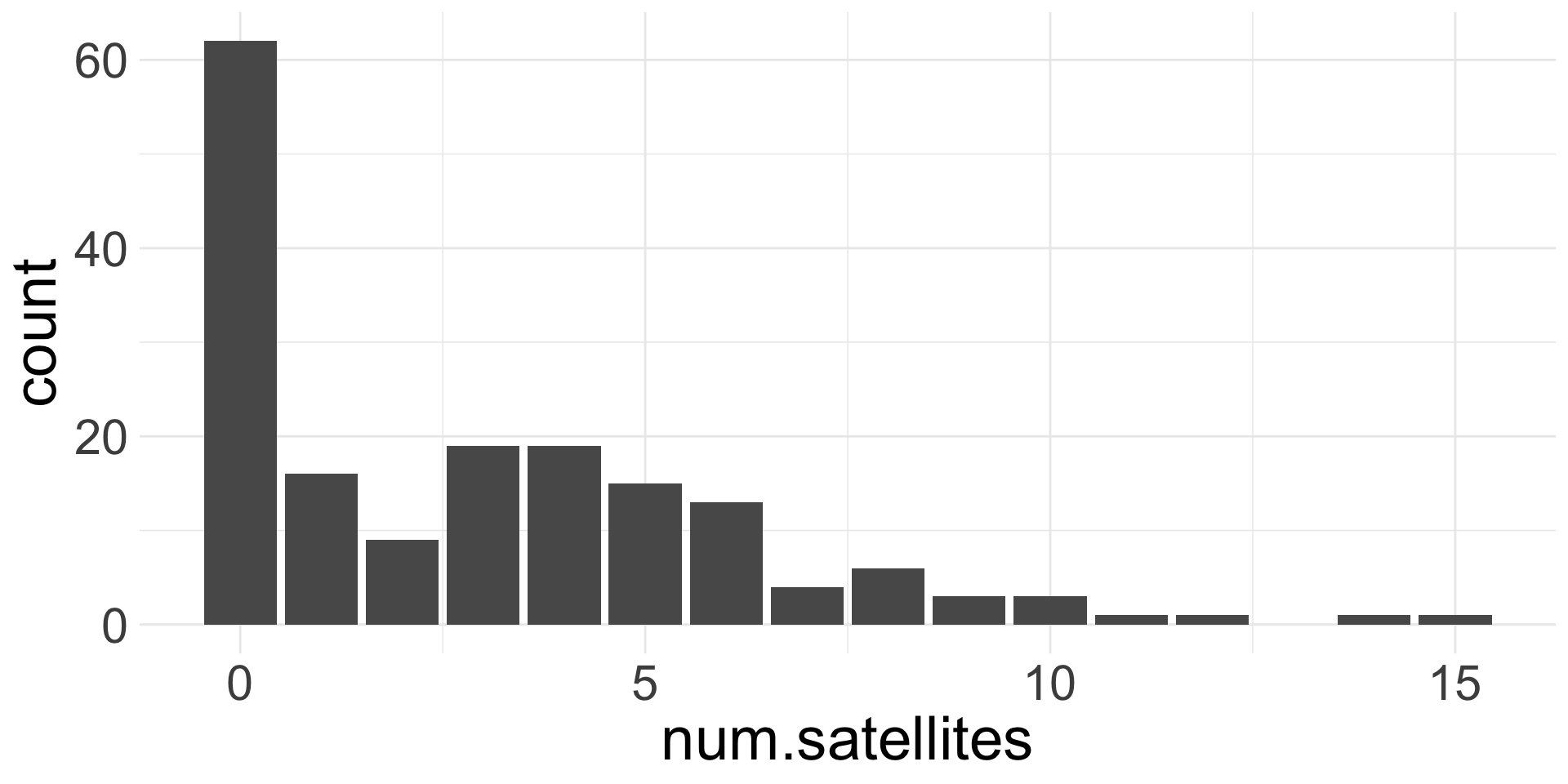
Example 1: Horseshoe Crabs and Satellites
Example of count data:
Each female horseshoe crab in the study had a male crab attached to her in her nest. The study investigated factors that affect whether the female crab had any other males, called satellites, residing near her. Explanatory variables that are thought to affect this included the female crab’s color, spine condition, and carapace width, and weight. The response outcome for each female crab is the number of satellites. There are 173 females in this study.

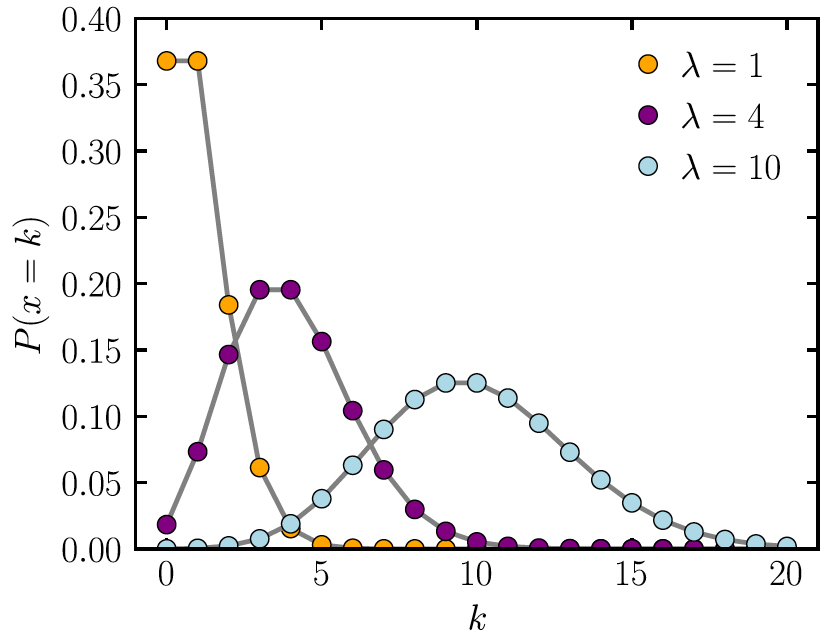
Poisson Distribution with a count
- The probability function of Poisson distribution: \[P(Y = y | \mu) = \dfrac{\mu^y e^{-\mu}}{y!}\]
- Where \(y\)’s are non-negative integers \(y=0, 1, 2,...\)
- Where \(\mu\) is the mean of \(Y\), that is \(E(Y)=\mu\)
- And also, \(\text{var}(Y)=\mu\)
- For a Poisson distribution, \(Y \sim \text{Poisson}(\mu)\)
- Range: \([0, \infty)\)
Example 1: Horseshoe Crabs and Satellites
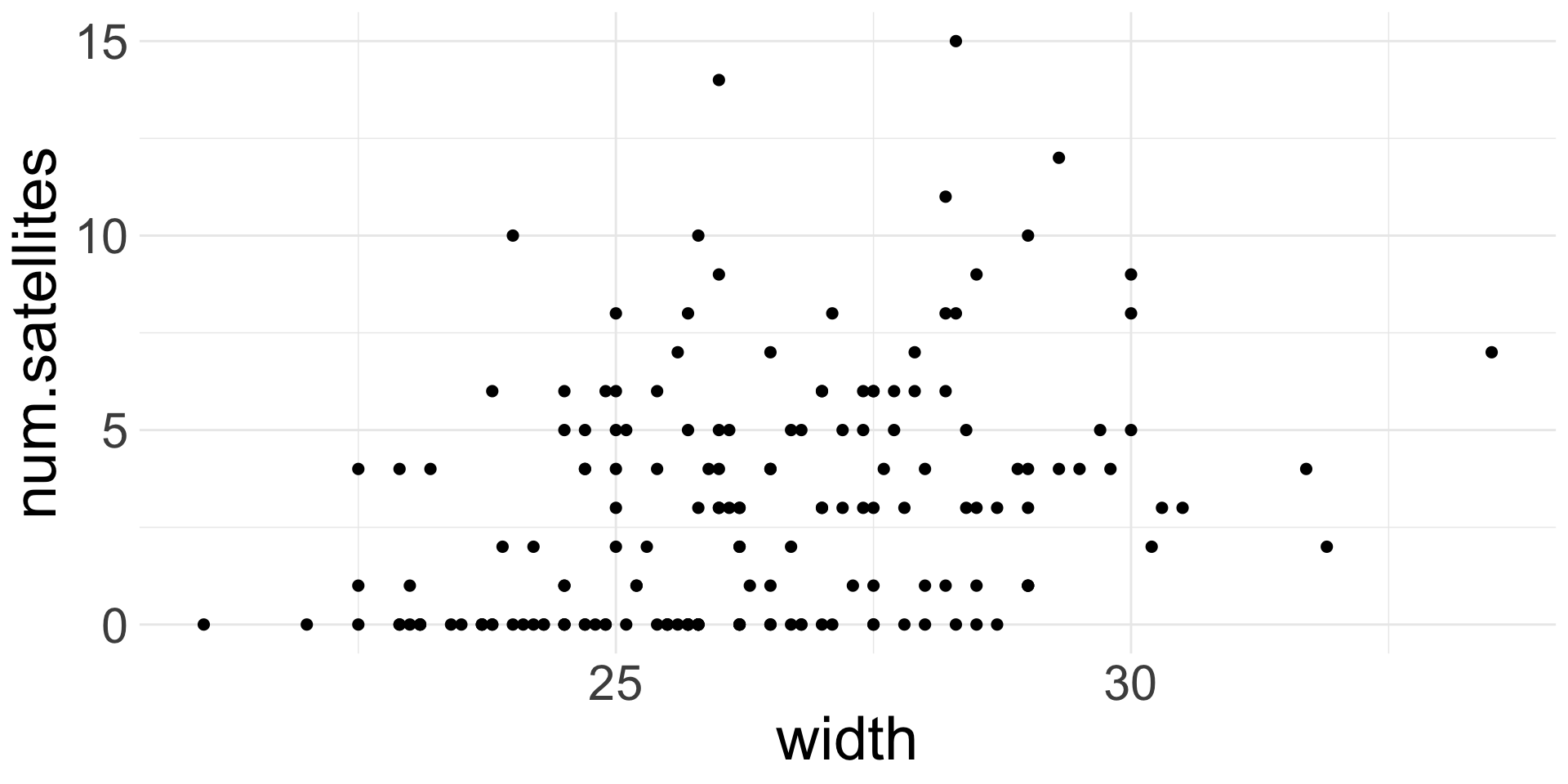
crab_mod = glm(num.satellites ~ width,
family=poisson,
data=hcrabs)
tidy(crab_mod, conf.int=T,
exponentiate=T) %>%
gt() %>%
tab_options(table.font.size = 35) %>%
fmt_number(decimals = 2)| term | estimate | std.error | statistic | p.value | conf.low | conf.high |
|---|---|---|---|---|---|---|
| (Intercept) | 0.04 | 0.54 | −6.09 | 0.00 | 0.01 | 0.11 |
| width | 1.18 | 0.02 | 8.22 | 0.00 | 1.13 | 1.23 |
Interpretation: For every 1-cm increase in carapace width, the expected number of satellites increases by 18% (95% CI: 13%, 23%).
Example 2: Lung Cancer Incidence
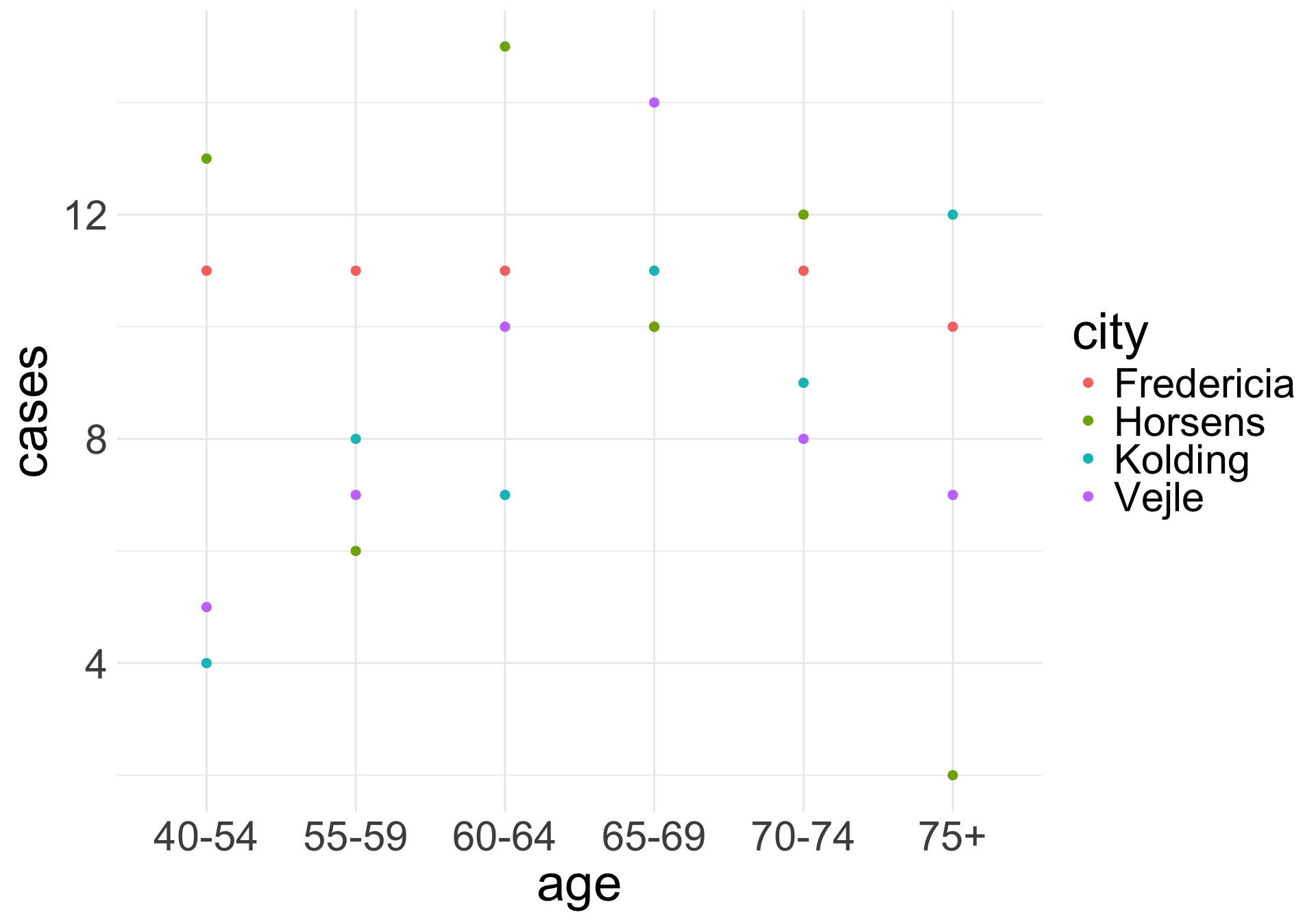
Regression table
| term | estimate | std.error | statistic | p.value | conf.low | conf.high |
|---|---|---|---|---|---|---|
| (Intercept) | 0.004 | 0.200 | −28.125 | 0.000 | 0.002 | 0.005 |
| cityHorsens | 0.719 | 0.182 | −1.818 | 0.069 | 0.503 | 1.026 |
| cityKolding | 0.690 | 0.188 | −1.978 | 0.048 | 0.476 | 0.995 |
| cityVejle | 0.762 | 0.188 | −1.450 | 0.147 | 0.525 | 1.099 |
| age55-59 | 3.007 | 0.248 | 4.434 | 0.000 | 1.843 | 4.901 |
| age60-64 | 4.566 | 0.232 | 6.556 | 0.000 | 2.907 | 7.236 |
| age65-69 | 5.857 | 0.229 | 7.704 | 0.000 | 3.748 | 9.249 |
| age70-74 | 6.404 | 0.235 | 7.891 | 0.000 | 4.043 | 10.212 |
| age75+ | 4.136 | 0.250 | 5.672 | 0.000 | 2.523 | 6.762 |