Data Management with the tidyverse
Adapted from parts of Mine Çetinkaya-Rundel’s tidyverse course
2023-01-10

Artwork by @allison_horst

What is the tidyverse?
The tidyverse is a collection of R packages designed for data science. All packages share an underlying design philosophy, grammar, and data structures.
- ggplot2 - data visualisation
- dplyr - data manipulation
- tidyr - tidy data
- readr - read rectangular data
- purrr - functional programming
- tibble - modern data frames
- stringr - string manipulation
- forcats - factors
- and many more …
ggplot2 in tidyverse

We talked about this in our review notes
- I want to revisit it: always helps to have more examples!
- This example is closer to the multivariable work we’ll do in this class!
- ggplot2 is tidyverse’s data visualization package
- The
ggin “ggplot2” stands for Grammar of Graphics
- It is inspired by the book Grammar of Graphics by Leland Wilkinson
Tidyverse: Visualizing multiple variables
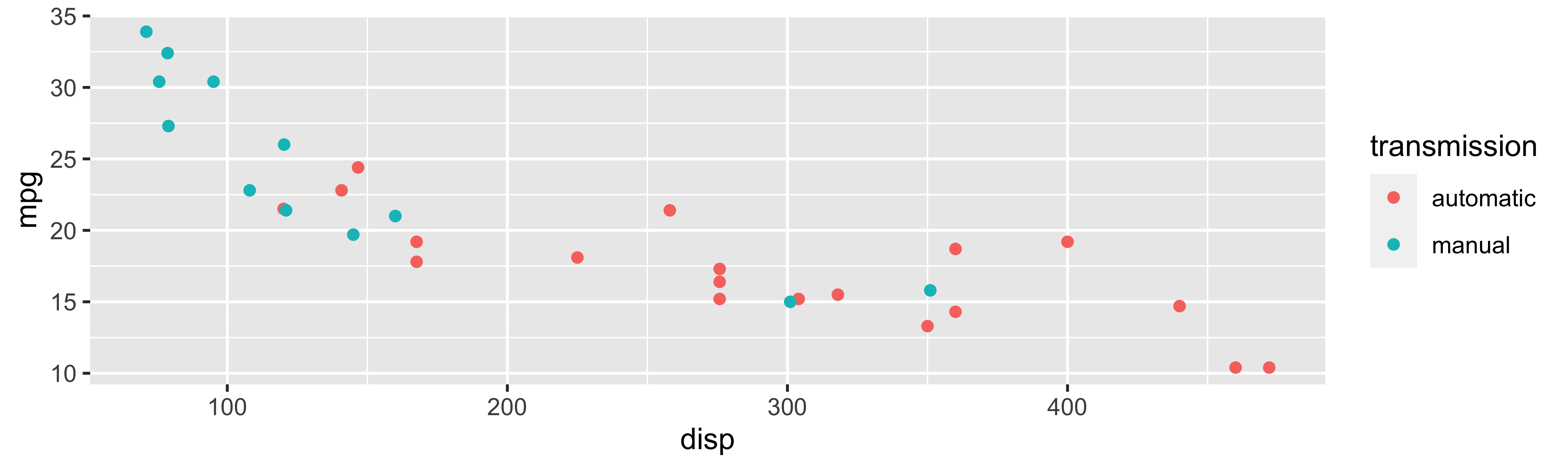
Tidyverse: Visualizing even more variables

Base R: Visualizing even more variables
mtcars$trans_color <- ifelse(mtcars$transmission == "automatic", "green", "blue")
mtcars_cyl4 = mtcars[mtcars$cyl == 4, ]
mtcars_cyl6 = mtcars[mtcars$cyl == 6, ]
mtcars_cyl8 = mtcars[mtcars$cyl == 8, ]
par(mfrow = c(1, 3), mar = c(2.5, 2.5, 2, 0), mgp = c(1.5, 0.5, 0))
plot(mpg ~ disp, data = mtcars_cyl4, col = trans_color, main = "Cyl 4")
plot(mpg ~ disp, data = mtcars_cyl6, col = trans_color, main = "Cyl 6")
plot(mpg ~ disp, data = mtcars_cyl8, col = trans_color, main = "Cyl 8")
legend("topright", legend = c("automatic", "manual"), pch = 1, col = c("green", "blue"))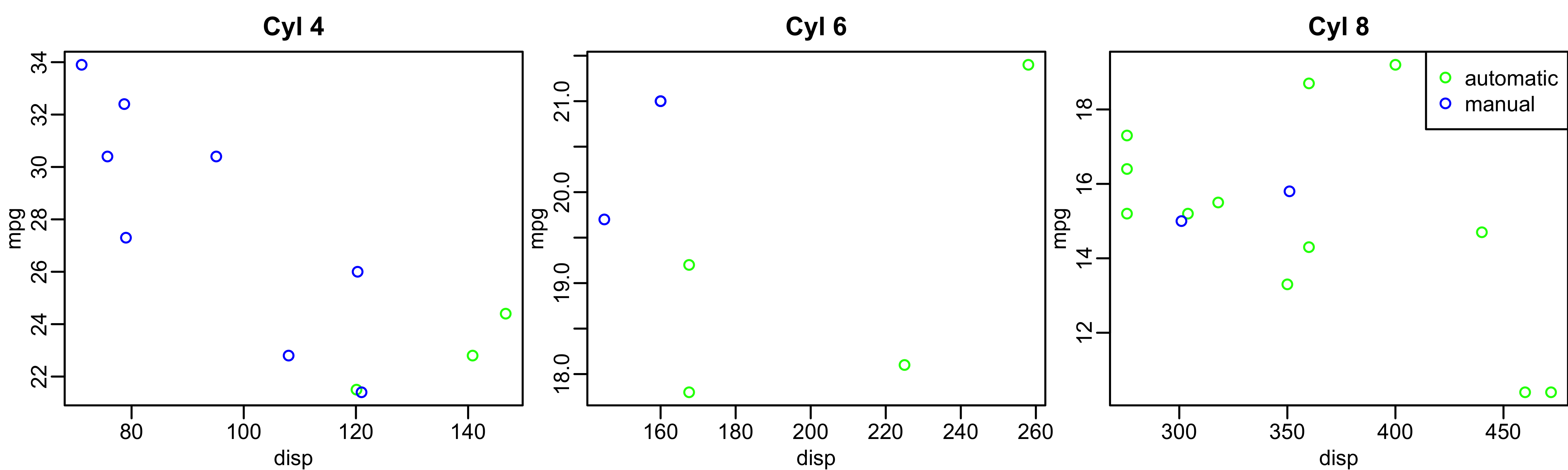
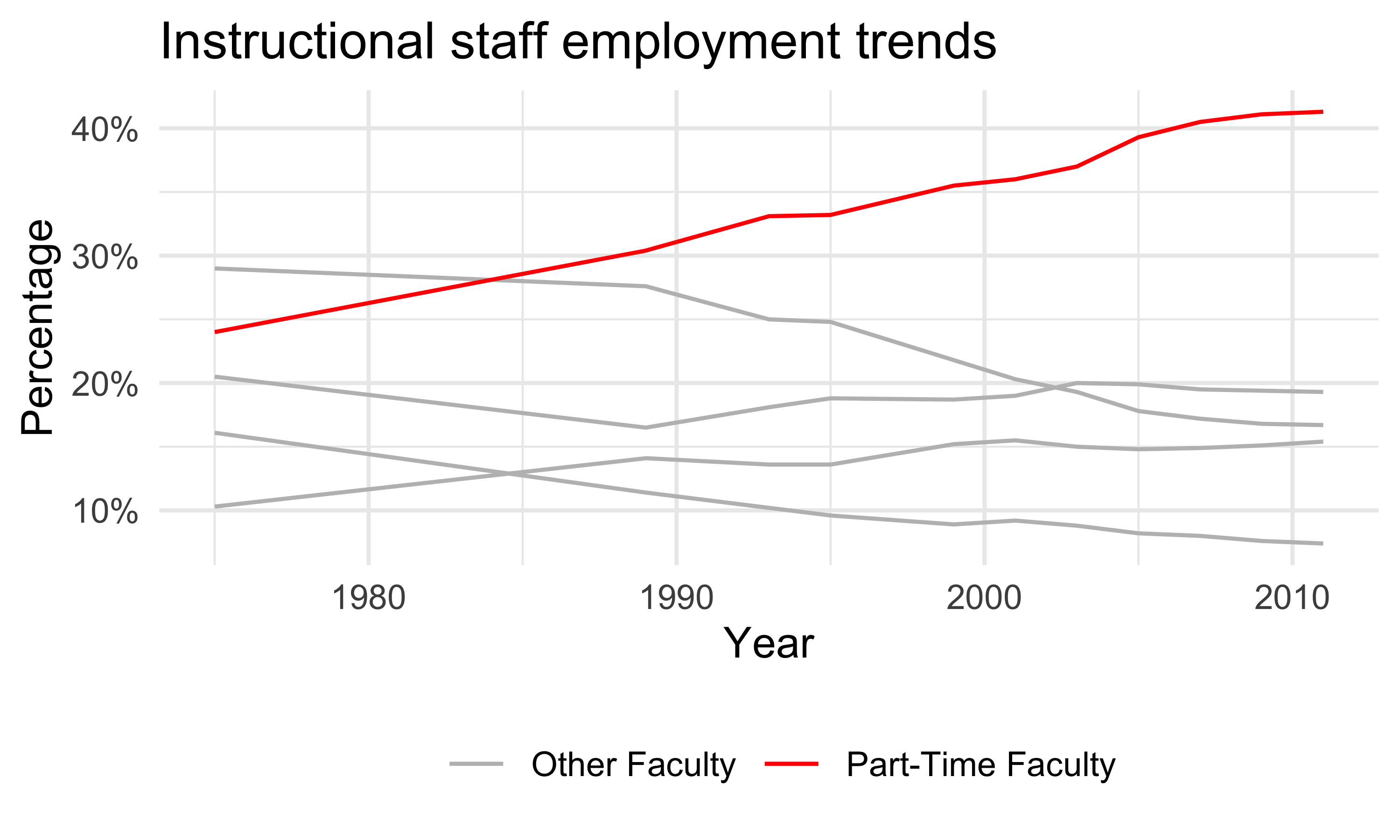
Example for pivot_longer(): Instructional staff employment trends
The American Association of University Professors (AAUP) is a nonprofit membership association of faculty and other academic professionals. This report by the AAUP shows trends in instructional staff employees between 1975 and 2011, and contains an image very similar to the one given below.
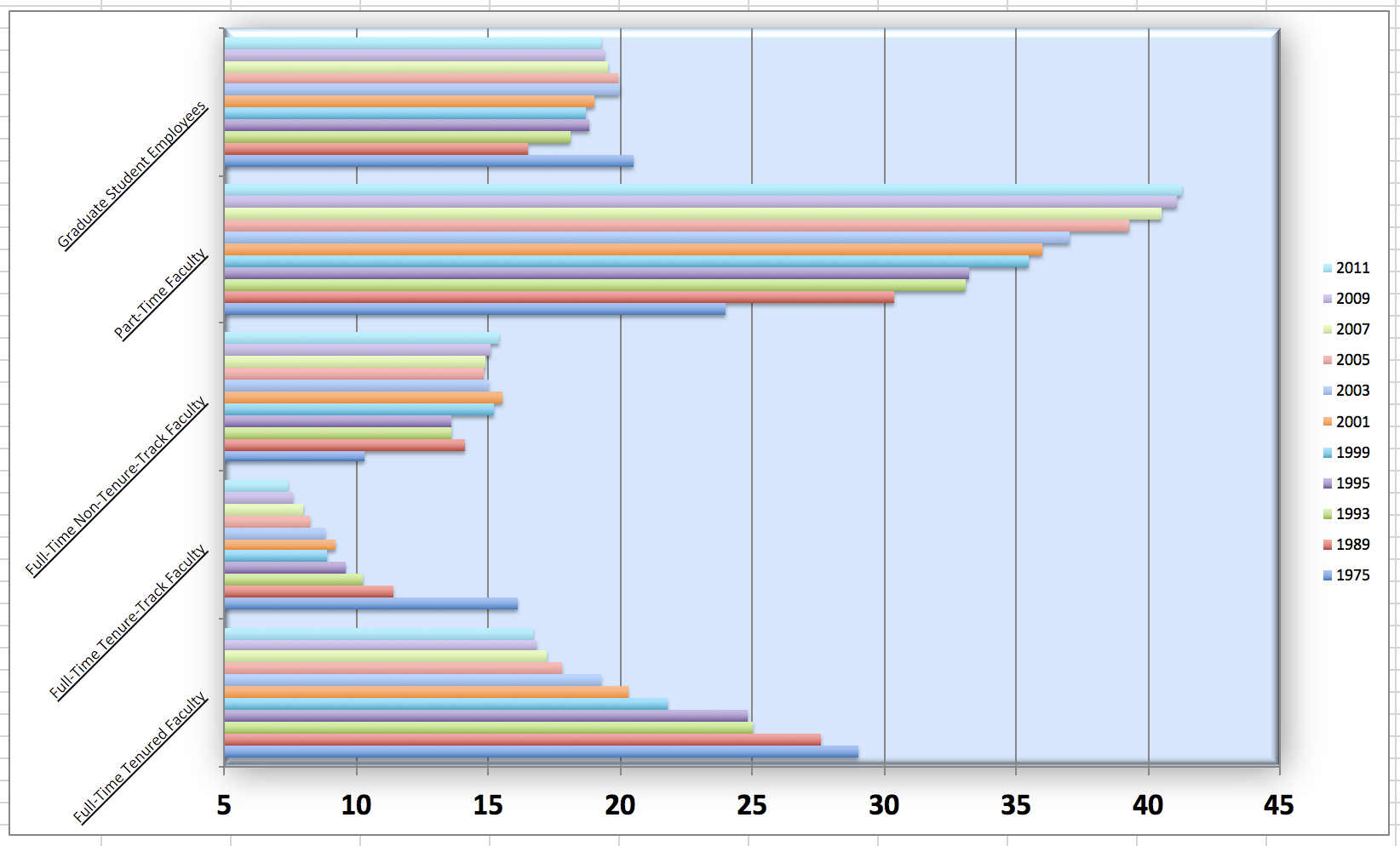

pivot_*() functions

A “meh” plot over the years
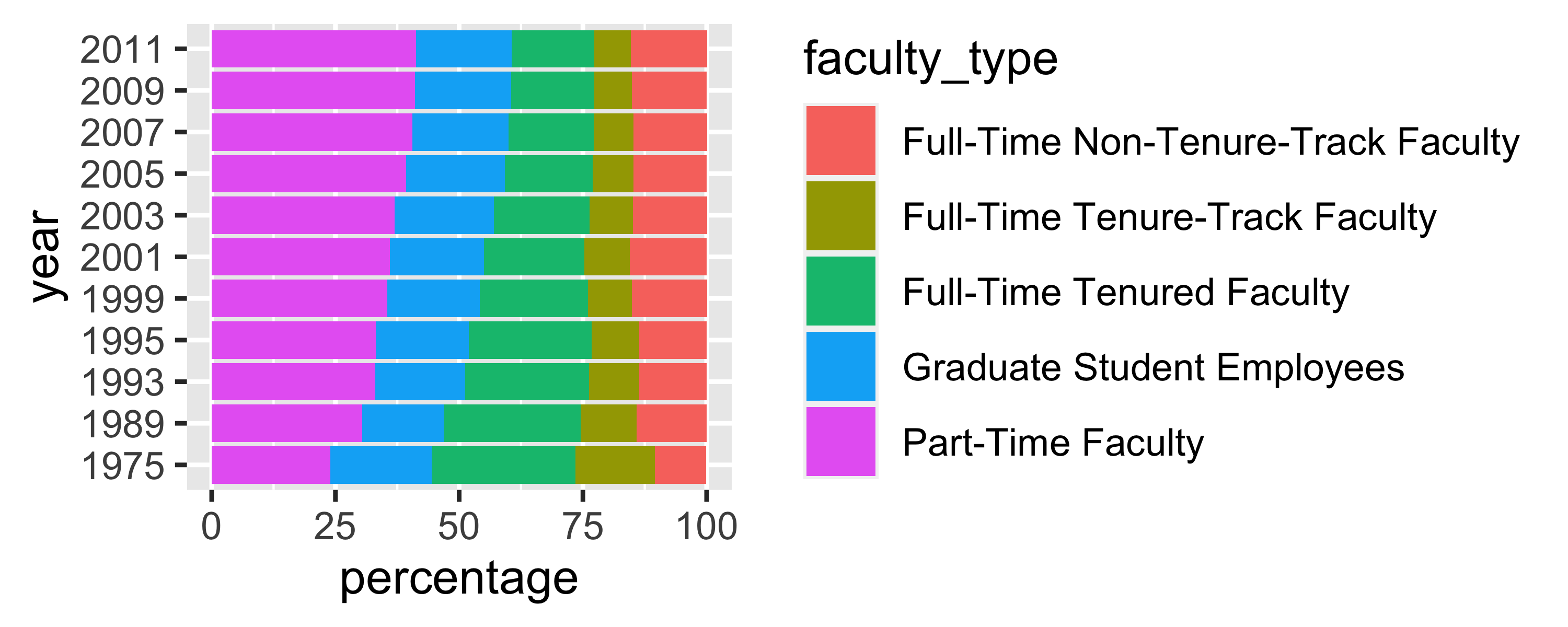
More improvement
staff_long %>%
mutate(
part_time = if_else(faculty_type == "Part-Time Faculty",
"Part-Time Faculty", "Other Faculty"),
year = as.numeric(year)) %>%
ggplot(
aes(x = year, y = percentage/100, group = faculty_type, color = part_time)) +
geom_line() +
scale_color_manual(values = c("gray", "red")) +
scale_y_continuous(labels = label_percent(accuracy = 1)) +
theme_minimal() +
labs(
title = "Instructional staff employment trends",
x = "Year", y = "Percentage", color = NULL) +
theme(legend.position = "bottom")