Simple Linear Regression (SLR)
2023-01-17
Reference: How did I code that?

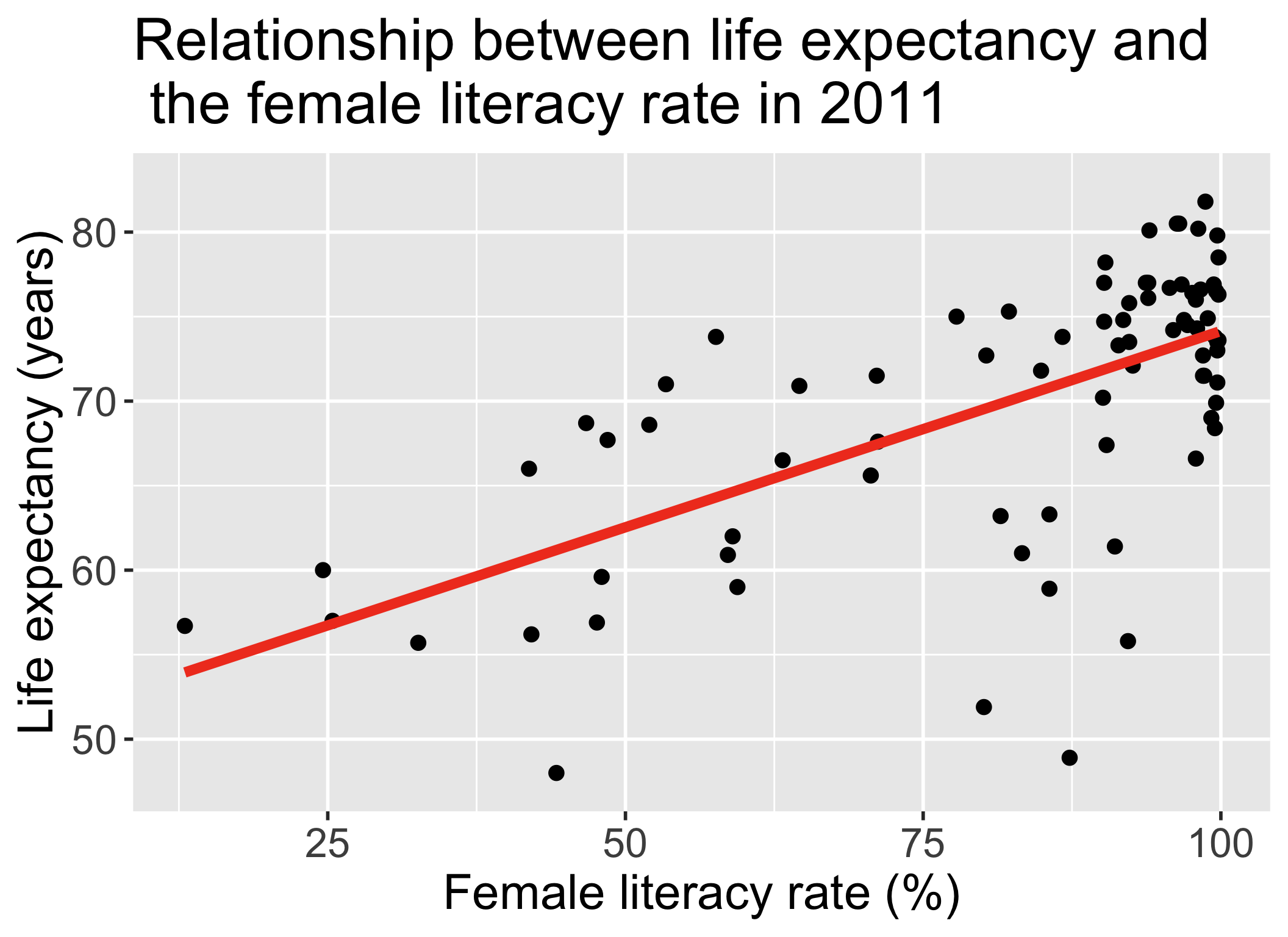
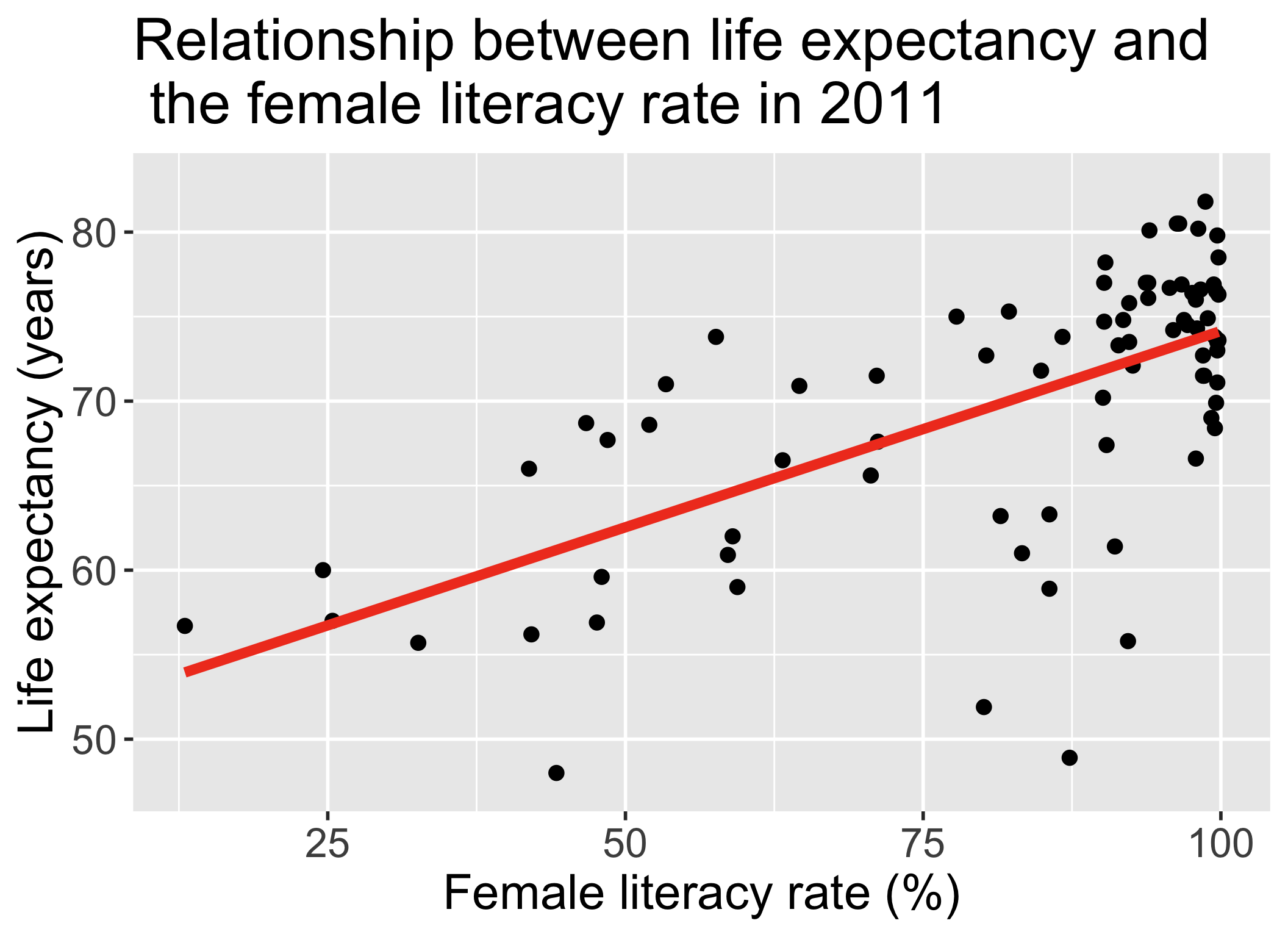
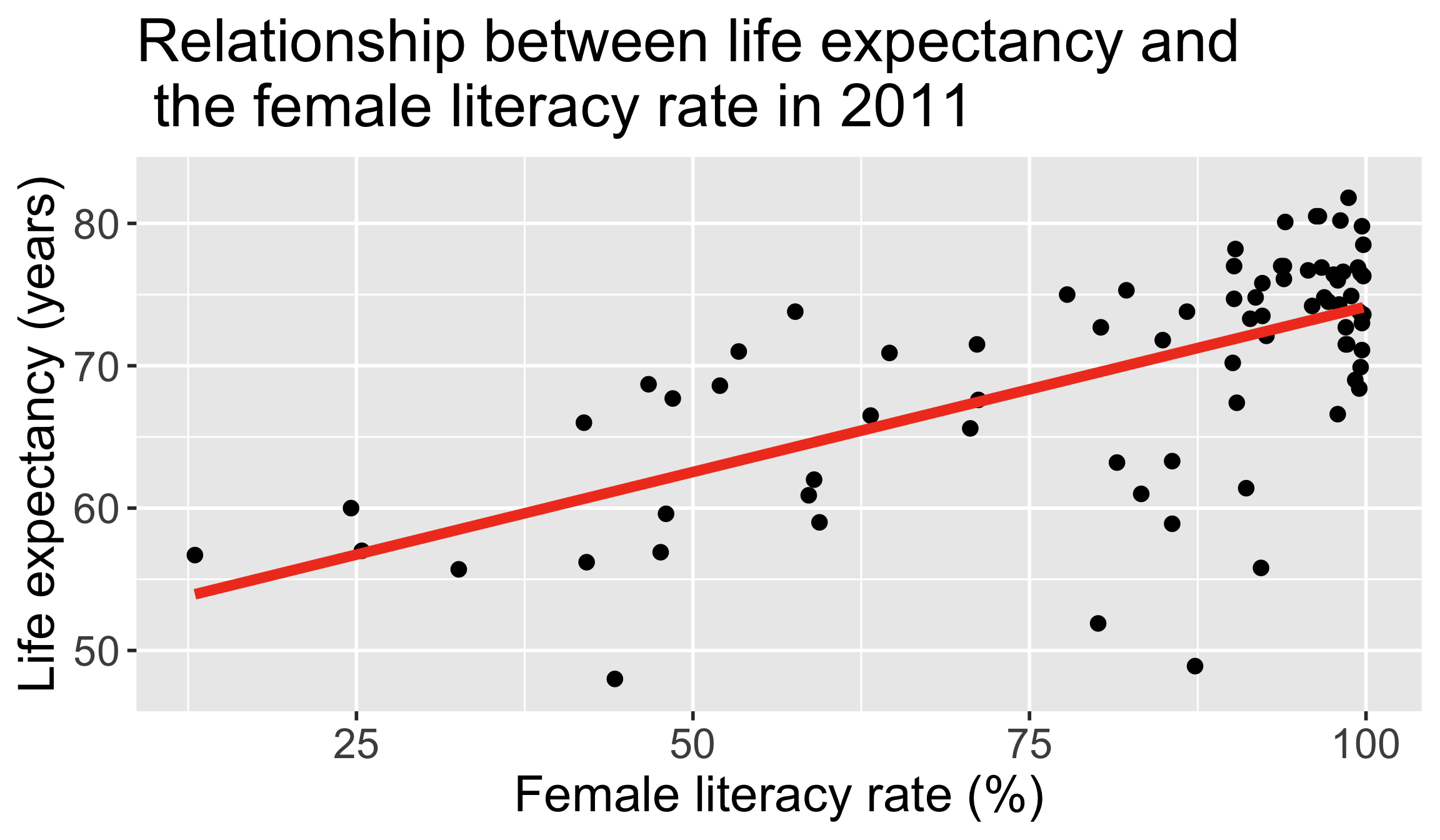
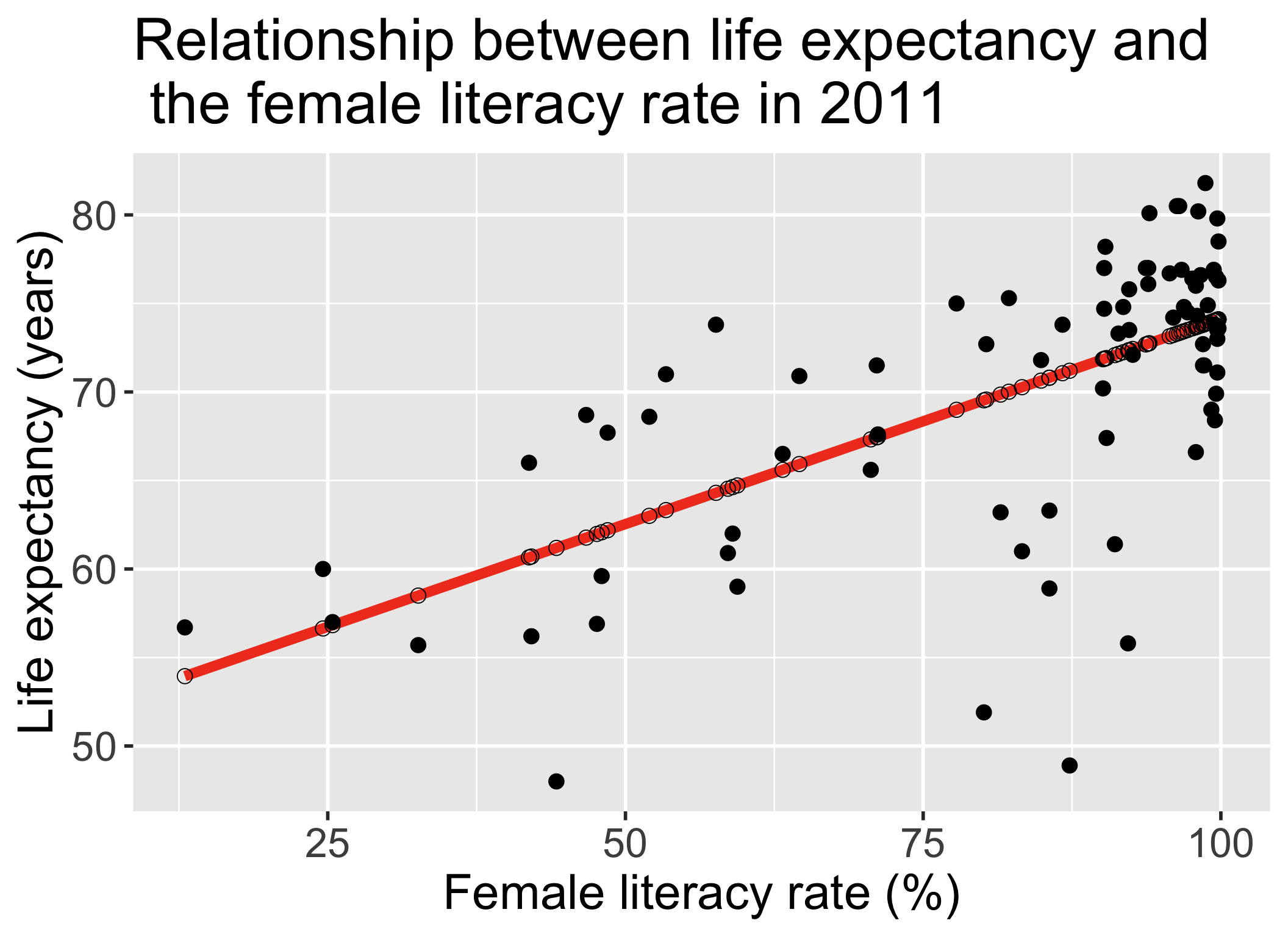
ggplot(gapm, aes(x = female_literacy_rate_2011,
y = life_expectancy_years_2011)) +
geom_point(size = 4) +
geom_smooth(method = "lm", se = FALSE, size = 3, colour="#F14124") +
labs(x = "Female literacy rate (%)",
y = "Life expectancy (years)",
title = "Relationship between life expectancy and \n the female literacy rate in 2011") +
theme(axis.title = element_text(size = 30),
axis.text = element_text(size = 25),
title = element_text(size = 30))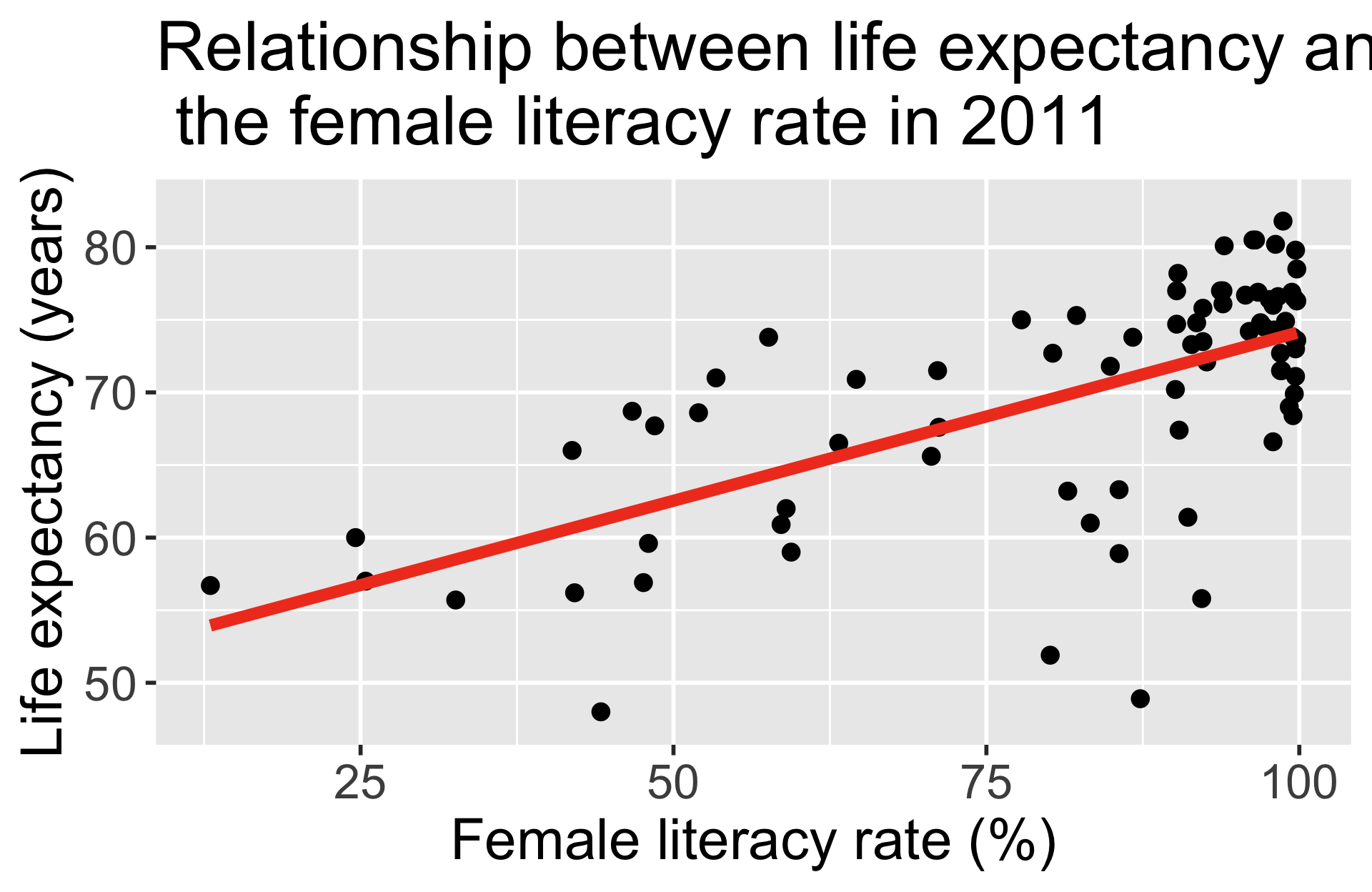
Questions we can ask with a simple linear regression model
- How do we…
- calculate slope & intercept?
- interpret slope & intercept?
- do inference for slope & intercept?
- CI, p-value
- do prediction with regression line?
- CI for prediction?
- Does the model fit the data well?
- Should we be using a line to model the data?
- Should we add additional variables to the model?
- multiple/multivariable regression
\[\widehat{\text{life expectancy}} = 50.9 + 0.232\cdot\text{female literacy rate}\]
Association vs. prediction
Association
- What is the association between countries’ life expectancy and female literacy rate?
- Use the slope of the line or correlation coefficient
Prediction
- What is the expected average life expectancy for a country with a specified female literacy rate?
\[\widehat{\text{life expectancy}} = 50.9 + 0.232\cdot\text{female literacy rate}\]
Let’s revisit the regression analysis process

![]()
Model Selection
Building a model
Prediction vs interpretation
Comparing models
Model Fitting
Parameter estimation
Interpret model parameters
Hypothesis tests for coefficients
Categorical covariates
Interactions
Model Evaluation
- Evaluation of full and reduced models
- Testing model assumptions
- Residuals
- Transformations
- Influential points
- Multicollinearity
If the population parameters are unobservable, how did we get the line for life expectancy?
Note: the population model is the true, underlying model that we are trying to estimate using our sample data
- Our goal in simple linear regression is to estimate \(\beta_0\) and \(\beta_1\)
Regression line = best-fit line
\[\widehat{Y} = \widehat{\beta}_0 + \widehat{\beta}_1 X \]
- \(\widehat{Y}\) is the predicted outcome for a specific value of \(X\)
- \(\widehat{\beta}_0\) is the intercept of the best-fit line
- \(\widehat{\beta}_1\) is the slope of the best-fit line, i.e., the increase in \(\widehat{Y}\) for every increase of one (unit increase) in \(X\)
- slope = rise over run
It all starts with a residual…
Recall, one characteristic of our population model was that the residuals, \(\epsilon\), were Normally distributed: \(\epsilon \sim N(0, \sigma^2)\)
In our population regression model, we had: \[Y = \beta_0 + \beta_1X + \epsilon\]
We can also take the average (expected) value of the population model
We take the expected value of both sides and get:
\[\begin{aligned} E[Y] & = E[\beta_0 + \beta_1X + \epsilon] \\ E[Y] & = E[\beta_0] + E[\beta_1X] + E[\epsilon] \\ E[Y] & = \beta_0 + \beta_1X + E[\epsilon] \\ E[Y|X] & = \beta_0 + \beta_1X \\ \end{aligned}\]
- We call \(E[Y|X]\) the expected value of \(Y\) given \(X\)
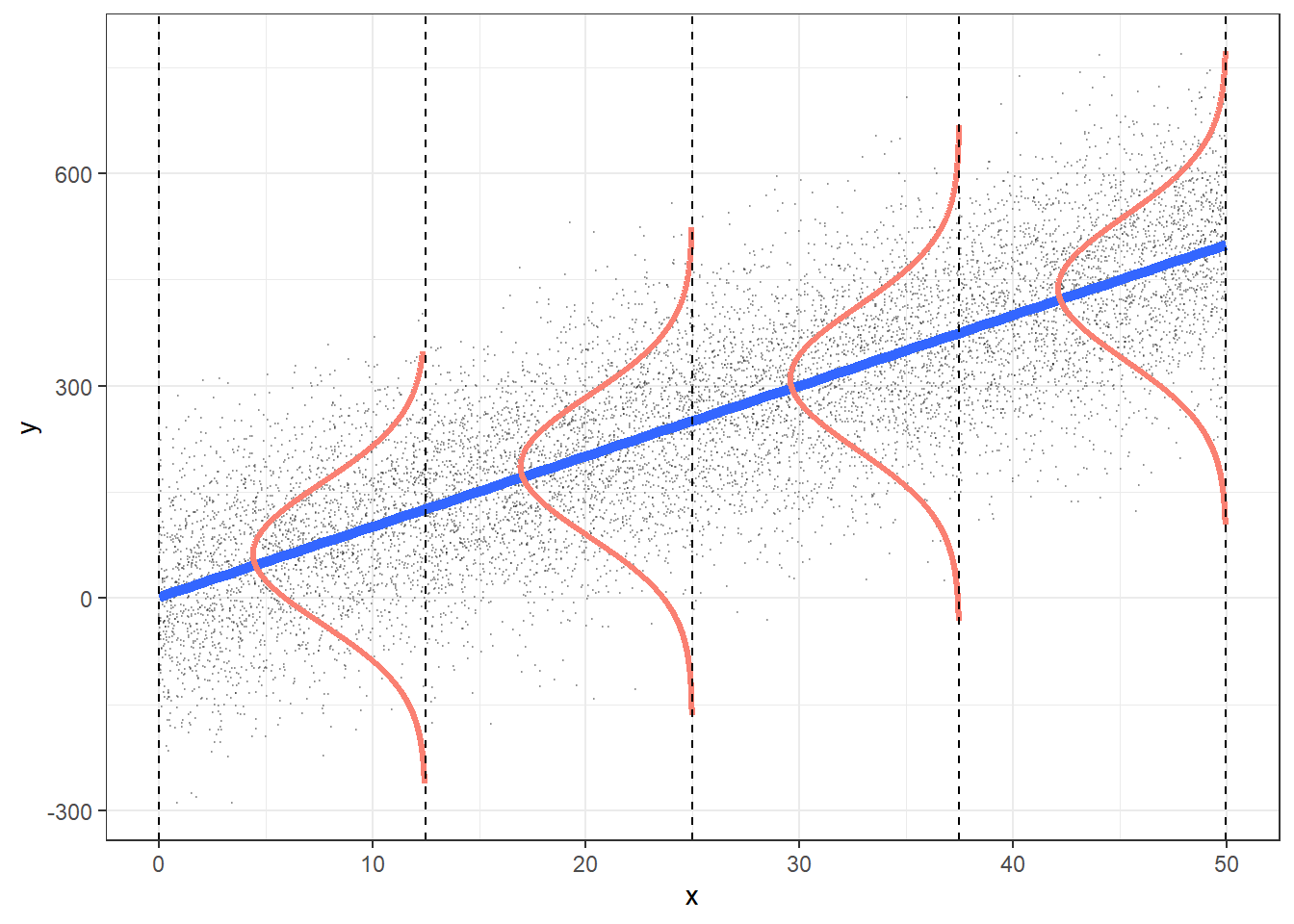
Individual \(i\) residuals in the estimated/fitted model
- Observed values for each individual \(i\): \(Y_i\)
- Value in the dataset for individual \(i\)
- Fitted value for each individual \(i\): \(\widehat{Y}_i\)
- Value that falls on the best-fit line for a specific \(X_i\)
- If two individuals have the same \(X_i\), then they have the same \(\widehat{Y}_i\)
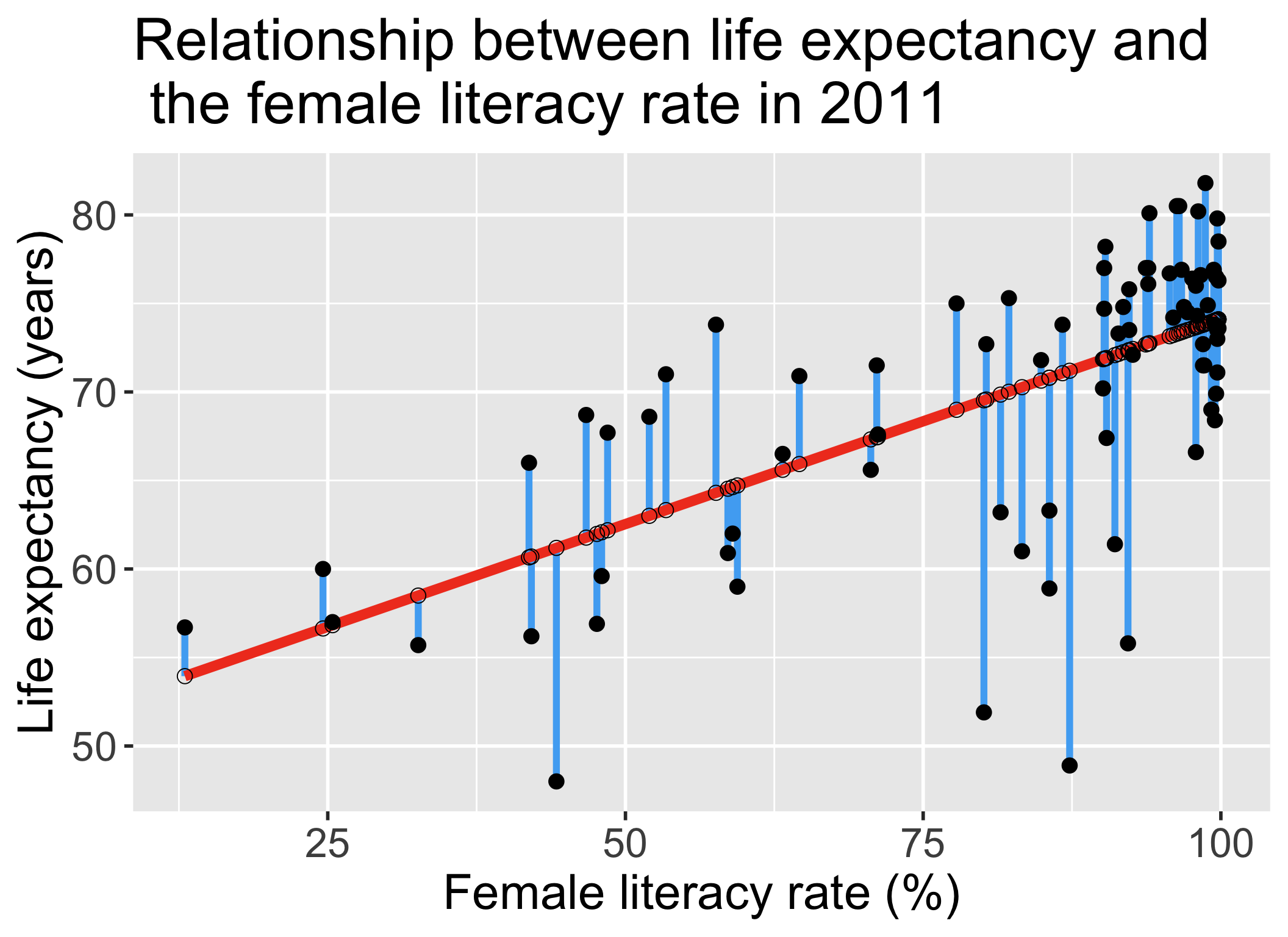
Individual \(i\) residuals in the estimated/fitted model
Observed values for each individual \(i\): \(Y_i\)
- Value in the dataset for individual \(i\)
Fitted value for each individual \(i\): \(\widehat{Y}_i\)
- Value that falls on the best-fit line for a specific \(X_i\)
- If two individuals have the same \(X_i\), then they have the same \(\widehat{Y}_i\)
Residual for each individual: \(\widehat\epsilon_i = Y_i - \widehat{Y}_i\)
- Difference between the observed and fitted value
Do I need to do all that work every time??

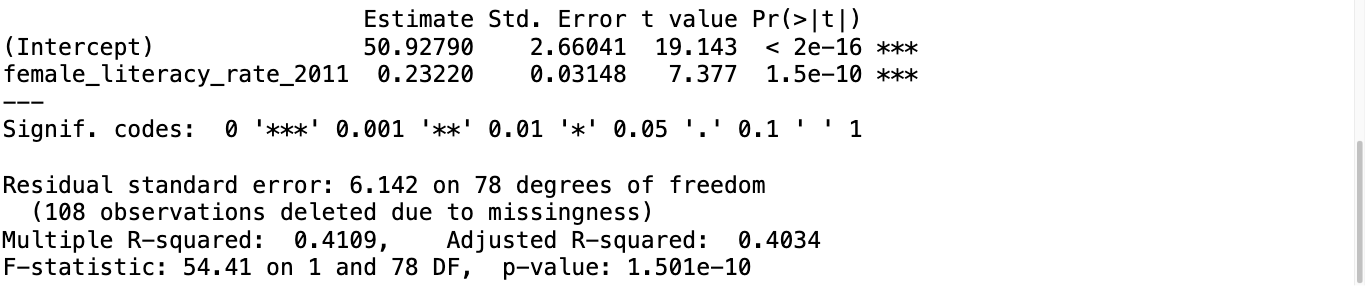
Regression in R: lm() + summary()
Call:
lm(formula = life_expectancy_years_2011 ~ female_literacy_rate_2011,
data = gapm)
Residuals:
Min 1Q Median 3Q Max
-22.299 -2.670 1.145 4.114 9.498
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 50.92790 2.66041 19.143 < 2e-16 ***
female_literacy_rate_2011 0.23220 0.03148 7.377 1.5e-10 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.142 on 78 degrees of freedom
(108 observations deleted due to missingness)
Multiple R-squared: 0.4109, Adjusted R-squared: 0.4034
F-statistic: 54.41 on 1 and 78 DF, p-value: 1.501e-10