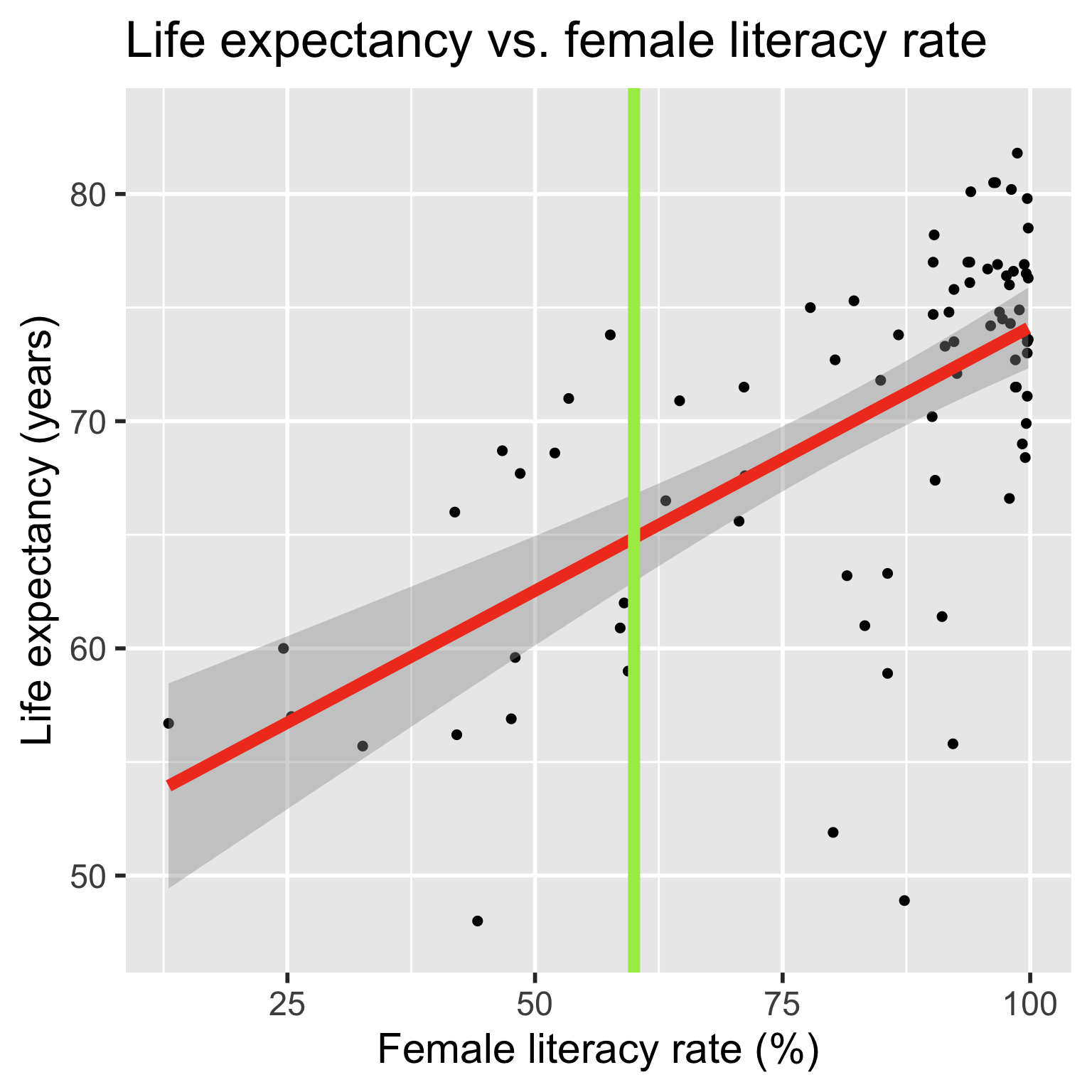
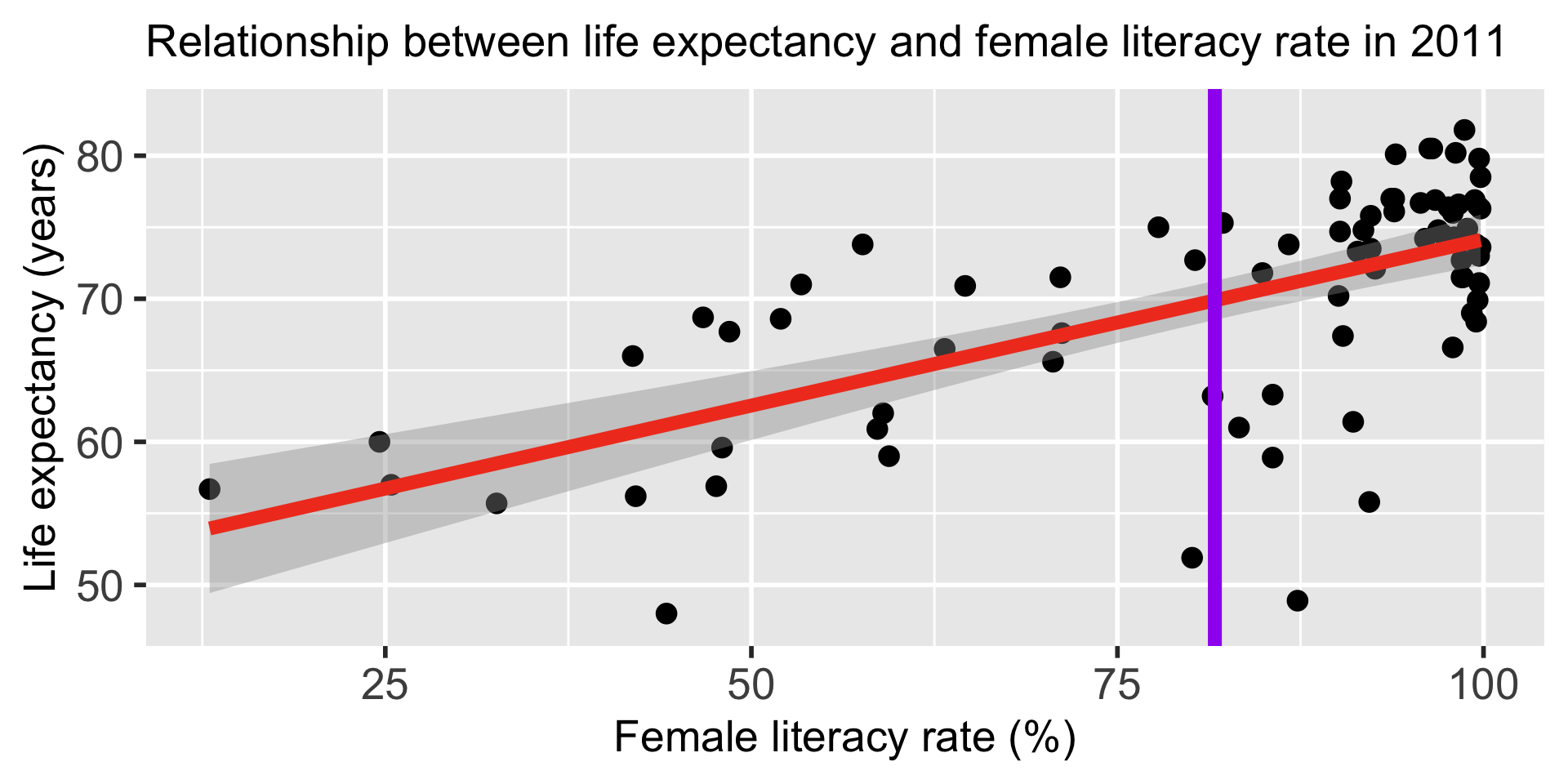
model1 <- lm(life_expectancy_years_2011 ~
female_literacy_rate_2011,
data = gapm)
# Get regression table:
tidy(model1) %>% gt() %>%
tab_options(table.font.size = 40) %>%
fmt_number(decimals = 2)| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 50.93 | 2.66 | 19.14 | 0.00 |
| female_literacy_rate_2011 | 0.23 | 0.03 | 7.38 | 0.00 |