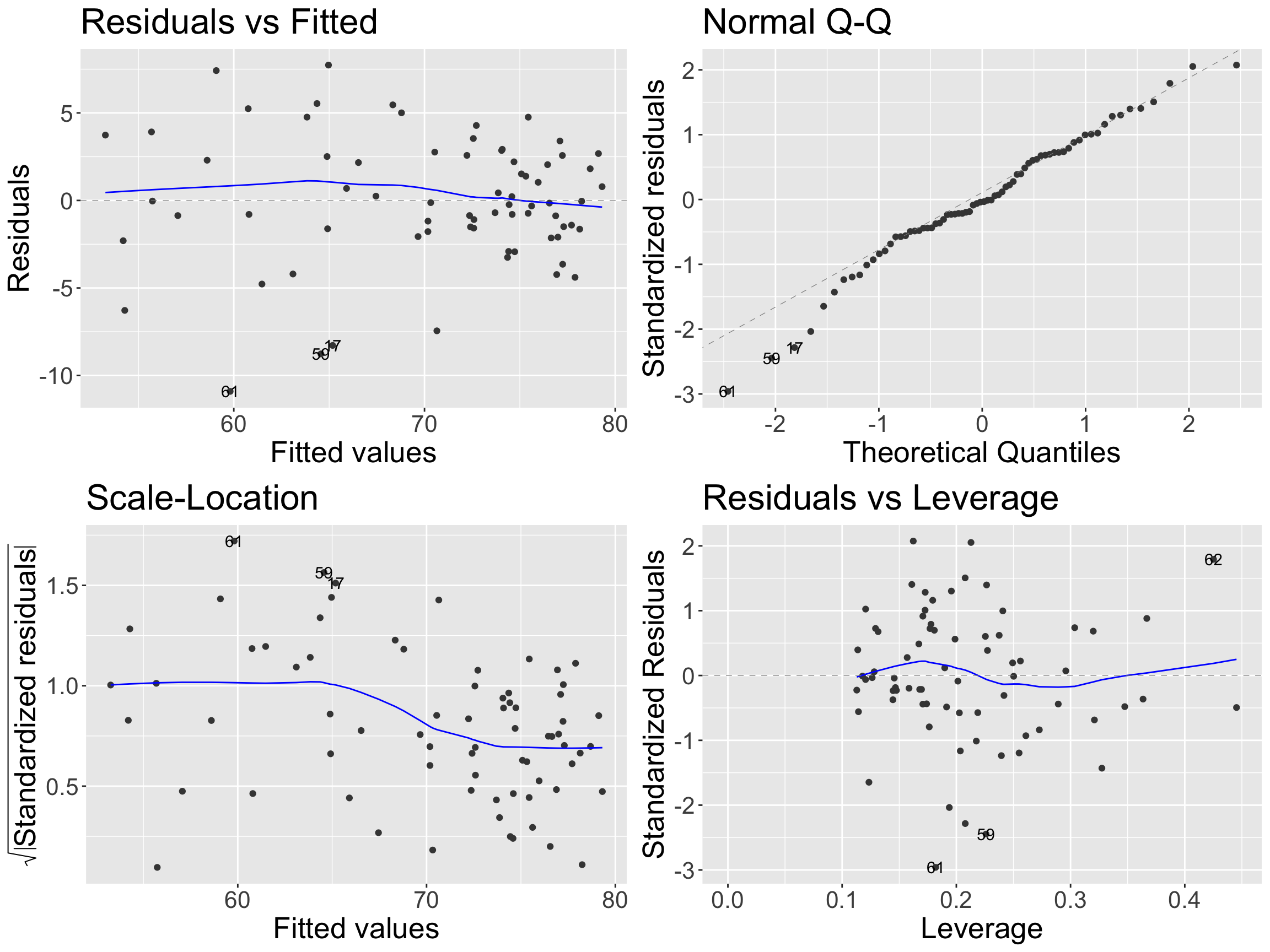
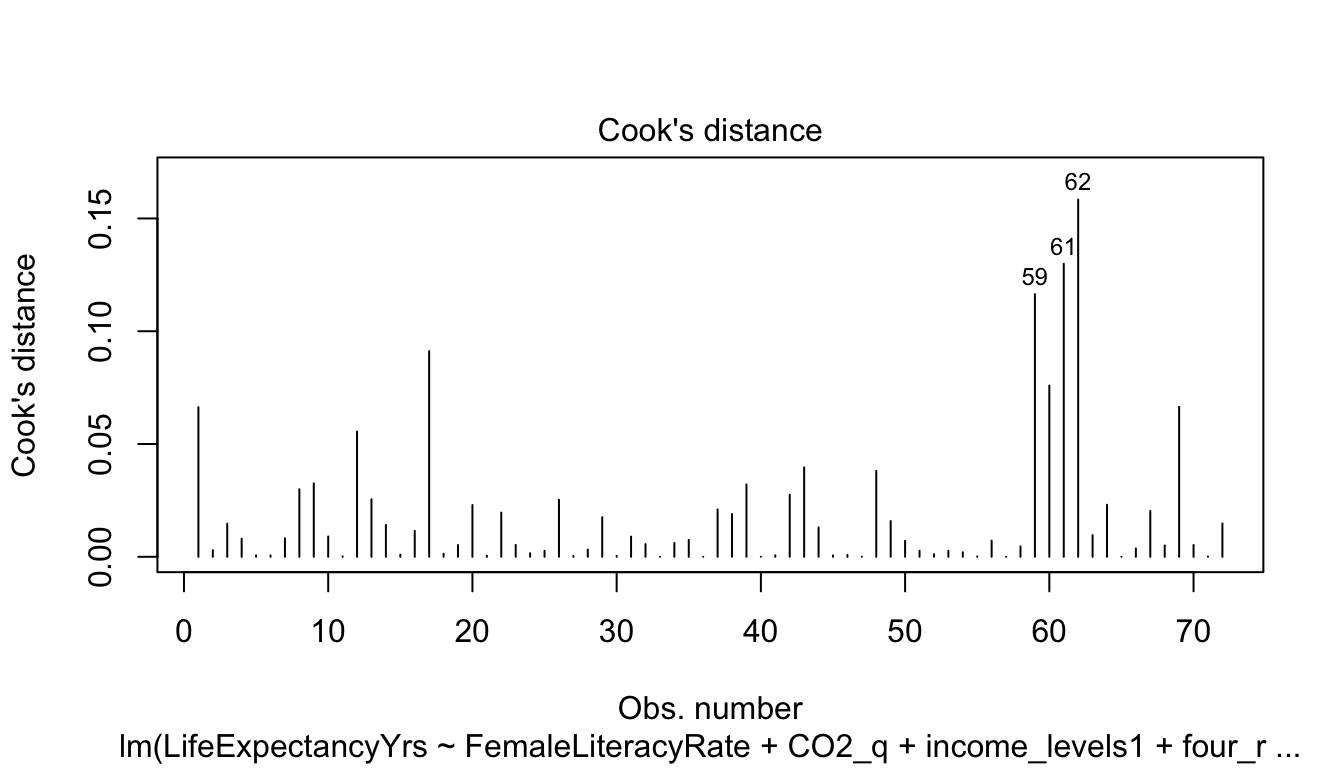
| (Intercept) |
39.877 |
4.889 |
8.157 |
0.000 |
| FemaleLiteracyRate |
−0.073 |
0.047 |
−1.555 |
0.125 |
| CO2_q(0.806,2.54] |
1.099 |
1.914 |
0.574 |
0.568 |
| CO2_q(2.54,4.66] |
−0.292 |
2.419 |
−0.121 |
0.904 |
| CO2_q(4.66,35.2] |
−0.595 |
2.524 |
−0.236 |
0.814 |
| income_levels1Lower middle income |
5.441 |
2.343 |
2.322 |
0.024 |
| income_levels1Upper middle income |
6.111 |
2.954 |
2.069 |
0.043 |
| income_levels1High income |
7.959 |
3.277 |
2.429 |
0.018 |
| four_regionsAmericas |
9.003 |
2.050 |
4.391 |
0.000 |
| four_regionsAsia |
5.260 |
1.637 |
3.213 |
0.002 |
| four_regionsEurope |
6.855 |
2.871 |
2.387 |
0.020 |
| WaterSourcePrct |
0.166 |
0.066 |
2.496 |
0.015 |
| FoodSupplykcPPD |
0.004 |
0.002 |
1.825 |
0.073 |
| members_oecd_g77oecd |
1.119 |
2.674 |
0.418 |
0.677 |
| members_oecd_g77others |
1.047 |
2.511 |
0.417 |
0.678 |