Lesson 13: Numerical Problems
2024-05-15
Zero cell count in a contingency table
- If no observations at any intersection of the covariate and outcome
- Zero cell in a contingency table should be detected in descriptive statistical analysis stage
- Example of one covariate with outcome:
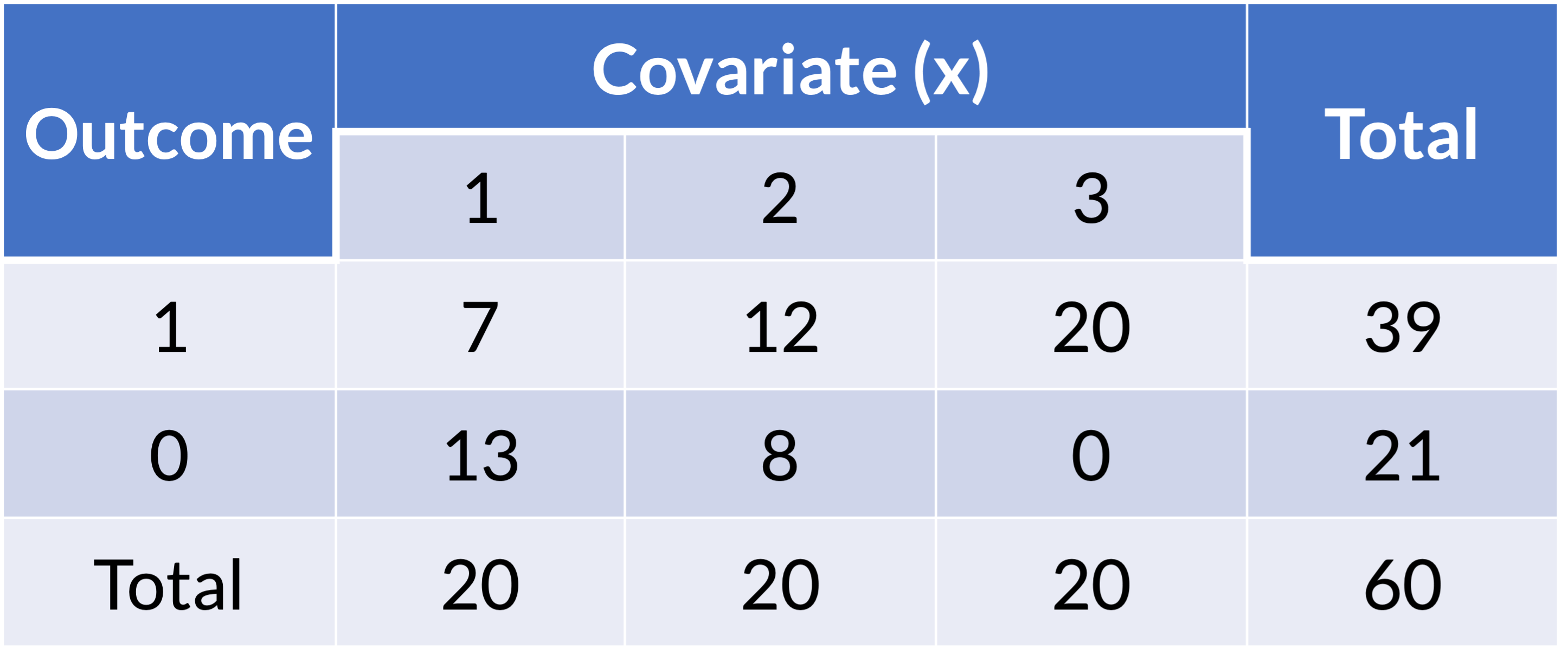
Zero cell count: example (1/3)
- Example of logistic regression with one covariate:
Zero cell count: example (2/3)
- Example of logistic regression with one covariate:
Coefficient estimates
| term | estimate | std.error | statistic | p.value | conf.low | conf.high |
|---|---|---|---|---|---|---|
| (Intercept) | −0.62 | 0.47 | −1.32 | 0.19 | −1.60 | 0.27 |
| xTwo | 1.02 | 0.65 | 1.57 | 0.12 | −0.23 | 2.35 |
| xThree | 20.19 | 2,404.67 | 0.01 | 0.99 | −119.00 | NA |
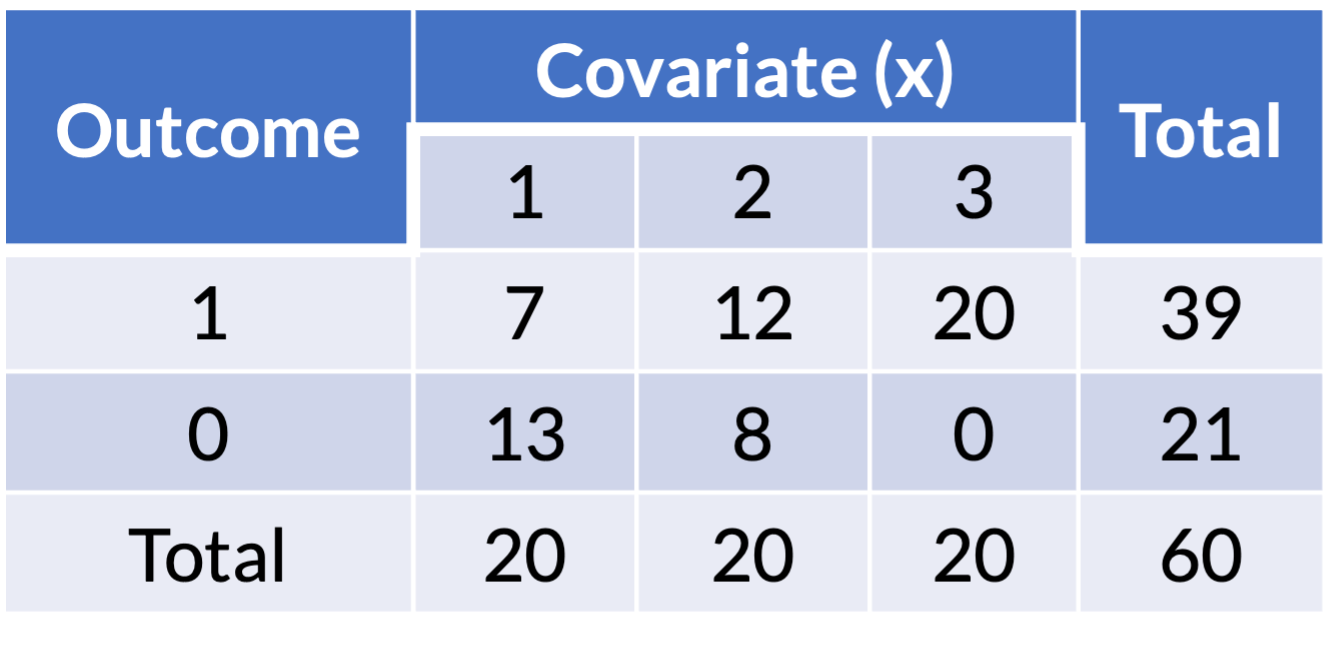
Zero cell count: example (3/3)
- Example of logistic regression with one covariate:
Coefficient estimates
| term | estimate | std.error | statistic | p.value | conf.low | conf.high |
|---|---|---|---|---|---|---|
| (Intercept) | −0.62 | 0.47 | −1.32 | 0.19 | −1.60 | 0.27 |
| xTwo | 1.02 | 0.65 | 1.57 | 0.12 | −0.23 | 2.35 |
| xThree | 20.19 | 2,404.67 | 0.01 | 0.99 | −119.00 | NA |
Coefficient estimate is large and standard error is large! Estimated odds ratio is very large and confidence interval cannot be computed.
Decide on how to address zero cell (1/2)
- Look at the proportions across the predictor, X:
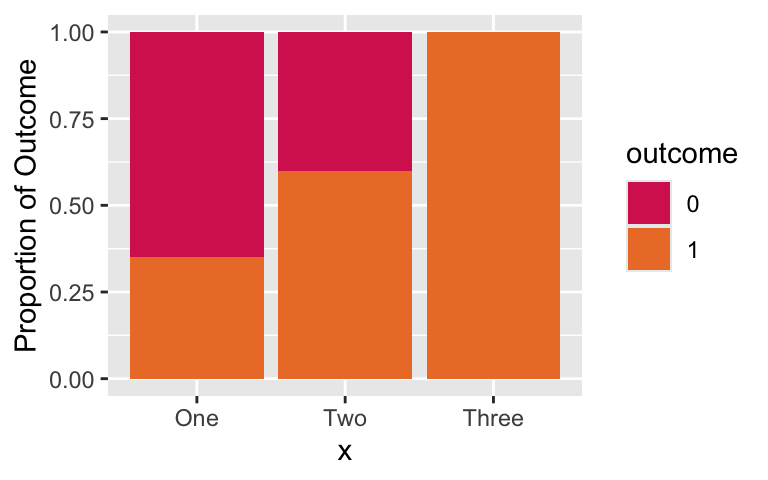
Decide on how to address zero cell (2/2)
- Look at the proportions across the predictor, X:
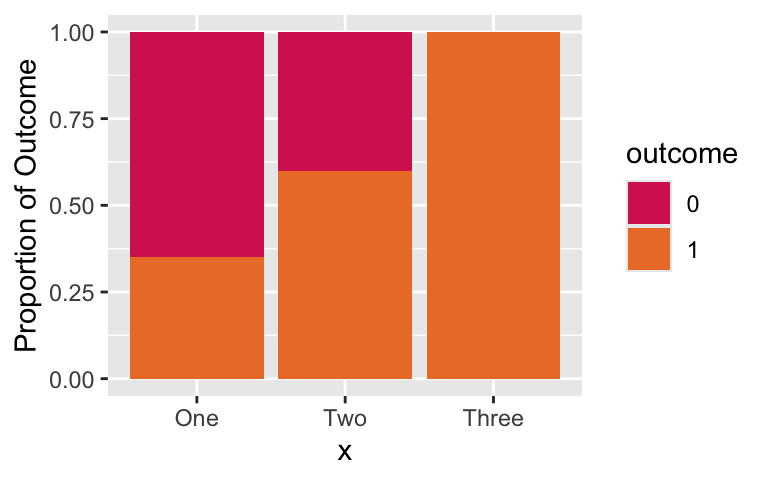
- Combining groups 2 and 3 together may not be a good idea.
- Their proportions of the outcome do not look similar.
- The predictor has an ordinal quality, so this is making me think a continuous approach might be good.
Treat predictor as continuous: check linearity assumption
newdata = data.frame(x = c(1, 2, 3))
pred = predict(ex1_cont_glm, newdata, se.fit=T, type = "link")
LL_CI1 = pred$fit - qnorm(1-0.05/2) * pred$se.fit
UL_CI1 = pred$fit + qnorm(1-0.05/2) * pred$se.fit
pred_link = cbind(Pred = pred$fit, LL_CI1, UL_CI1) %>% inv.logit()
pred_prob = as.data.frame(pred_link) %>% mutate(x = c("One", "Two", "Three"))Plotting sample and predicted probabilities
ggplot() +
geom_bar(data = ex1, aes(x = x, fill = outcome), stat = "count", position = "fill") +
labs(y = "Proportion of Outcome") +
scale_fill_manual(values=c("#D6295E", "#ED7D31")) +
geom_point(data = pred_prob, aes(x = x, y=Pred), size=3) +
geom_errorbar(data = pred_prob, aes(x = x, y=Pred, ymin = LL_CI1, ymax = UL_CI1), width = 0.25)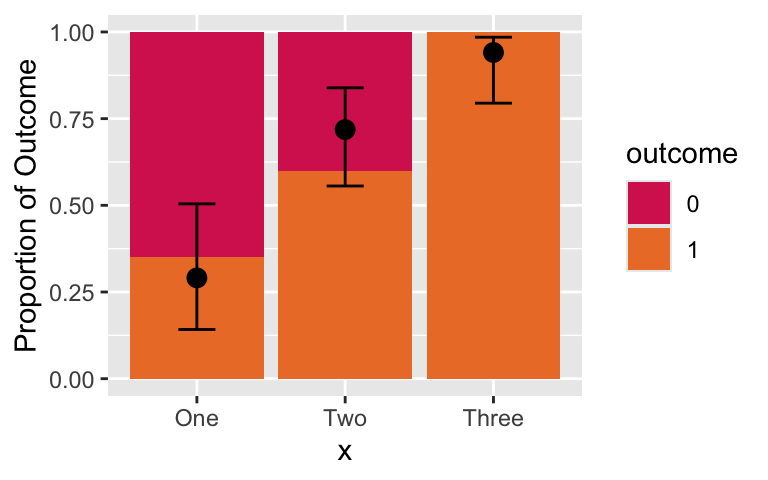
This looks pretty good. We’ve mostly captured the trend of the outcome proportion!
Complete Separation: Ways to address issue
Collapse categorical variables in a meaningful way
- Easiest and best if stat methods are restricted (common for collaborations)
Exclude
x1from the model- Not ideal because this could lead to biased estimates for the other predicted variables in the model
Firth logistic regression
Uses penalized likelihood estimation method
Basically takes the likelihood (that has no maximum) and adds a penalty that makes the MLE estimatable

Complete Separation: Firth logistic regression
library(logistf)
m1_f = logistf(outcome ~ x1 + x2, data = ex3, family=binomial)
summary(m1_f) # Cannot use tidy on this :(logistf(formula = outcome ~ x1 + x2, data = ex3, family = binomial)
Model fitted by Penalized ML
Coefficients:
coef se(coef) lower 0.95 upper 0.95 Chisq p
(Intercept) -2.9748898 1.7244237 -15.47721665 -0.1208883 4.2179522 0.03999841
x1 0.4908484 0.2745754 0.05268216 2.1275832 5.0225056 0.02501994
x2 0.4313732 0.4988396 -0.65793078 4.4758930 0.7807099 0.37692411
method
(Intercept) 2
x1 2
x2 2
Method: 1-Wald, 2-Profile penalized log-likelihood, 3-None
Likelihood ratio test=5.505687 on 2 df, p=0.06374636, n=8
Wald test = 3.624899 on 2 df, p = 0.1632538
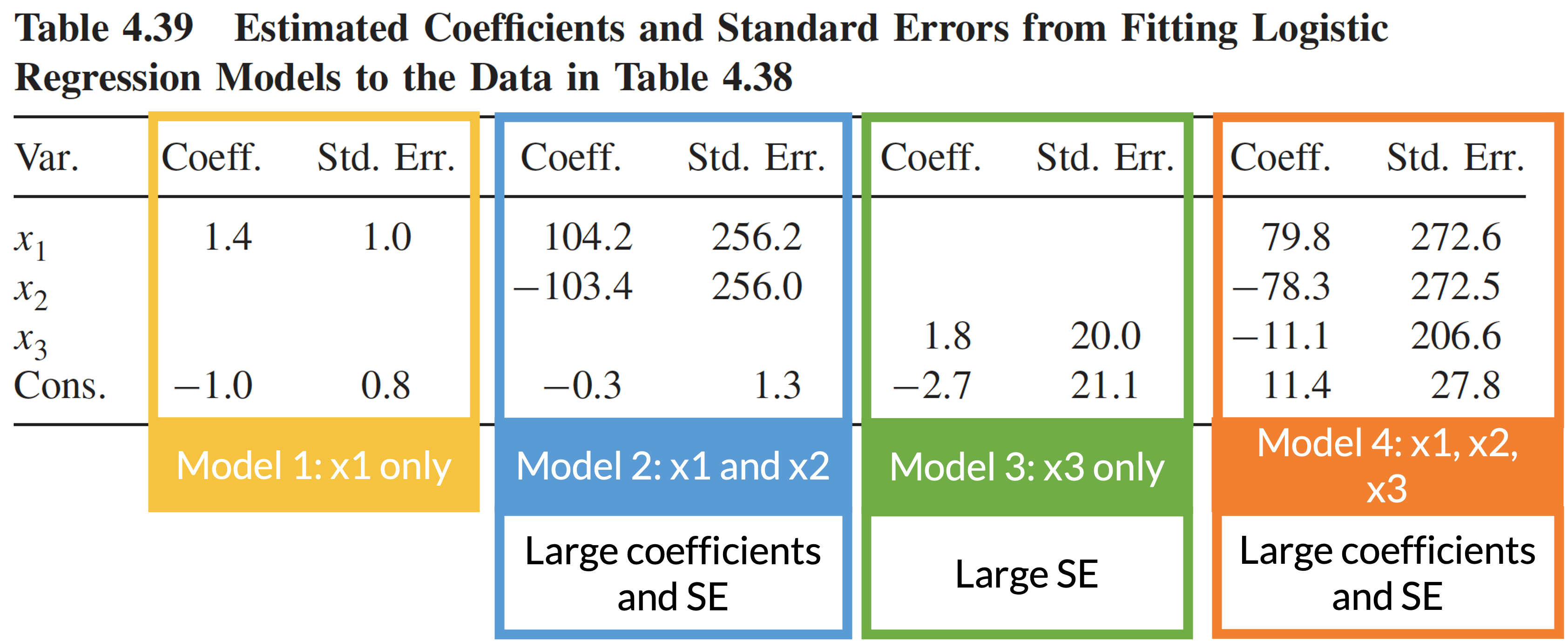
Multicollinearity: example (1/4)
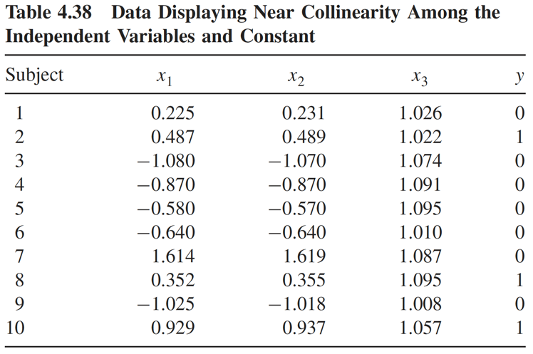
Table below is a simulated data with
- \(x_1 \sim \text{Normal}(0,1)\)
- \(x_2 = x_1 + \text{Uniform}(0,0.1)\)
- \(x_3 = 1 + \text{Uniform}(0, 0.01)\)
Therefore, \(x_1\) and \(x_2\) are highly correlated, and \(x_3\) is nearly collinear with the constant term
Multicollinearity: example (2/4)
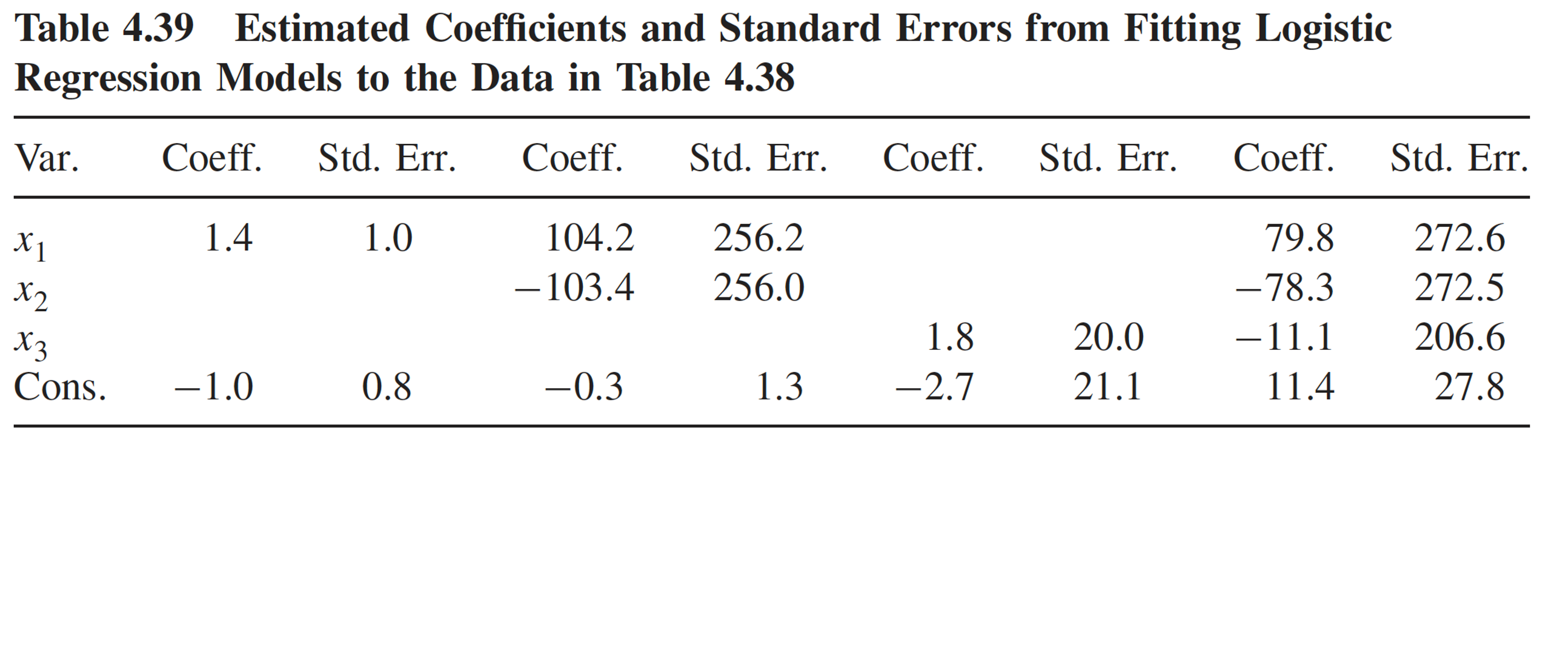
Four logistic regression models using data in the previous slide
Consequence of multicollinearity: large coefficient estimates and/or standard errors
Multicollinearity: example (3/4)
Four logistic regression models using data in the previous slide
Consequence of multicollinearity: large coefficient estimates and/or standard errors

Multicollinearity: example (4/4)
Four logistic regression models using data in the previous slide
Consequence of multicollinearity: large coefficient estimates and/or standard errors